Langfuse-tracing
描述
分类
🔧 Engineering🤖 AI & Machine Learning
使用的节点
n8n-nodes-base.n8nn8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.waitn8n-nodes-base.waitn8n-nodes-base.splitOutn8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.httpRequestn8n-nodes-base.splitInBatches
价格免费
浏览量0
最后更新11/28/2025
workflow.json
{
"id": "cFEhvBNcaSFxATXN",
"meta": {
"instanceId": "64e2e6219c21561109cfc6c128be1b2db6e516fa79f92287604734757bdc0881",
"templateCredsSetupCompleted": true
},
"name": "Langfuse-tracing",
"tags": [
{
"id": "IIhB5fqgApTNy0rp",
"name": "tracing",
"createdAt": "2025-10-12T18:54:49.152Z",
"updatedAt": "2025-10-12T18:54:49.152Z"
}
],
"nodes": [
{
"id": "d792a10f-7746-4c53-9451-6f0472bae2be",
"name": "When Executed by Another Workflow",
"type": "n8n-nodes-base.executeWorkflowTrigger",
"position": [
0,
0
],
"parameters": {
"workflowInputs": {
"values": [
{
"name": "execution_id"
}
]
}
},
"typeVersion": 1.1
},
{
"id": "b1d16fb4-fce6-46a1-a612-70b5559d9af3",
"name": "n8n",
"type": "n8n-nodes-base.n8n",
"position": [
660,
0
],
"parameters": {
"options": {
"activeWorkflows": true
},
"resource": "execution",
"operation": "get",
"executionId": "={{ $('When Executed by Another Workflow').item.json.execution_id }}",
"requestOptions": {}
},
"credentials": {
"n8nApi": {
"id": "6a4Ov9OMUAoJ0kGJ",
"name": "n8n account"
}
},
"typeVersion": 1
},
{
"id": "b6bedd99-921a-4160-887c-303c9956b850",
"name": "Split Out",
"type": "n8n-nodes-base.splitOut",
"position": [
1120,
0
],
"parameters": {
"include": "selectedOtherFields",
"options": {},
"fieldToSplitOut": "perModelRuns",
"fieldsToInclude": "workflowId, , workflowName, executionId, startedAt, stoppedAt, executionMs, executionSec, totals_promptTokens, totals_completionTokens, totals_totalTokens"
},
"typeVersion": 1
},
{
"id": "d2524dd7-554f-425e-879b-53b070b793e7",
"name": "Loop Over Items",
"type": "n8n-nodes-base.splitInBatches",
"position": [
1340,
0
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "9a7e20bc-607f-4e17-b4f4-7dac76212551",
"name": "HTTP Request",
"type": "n8n-nodes-base.httpRequest",
"position": [
2100,
60
],
"parameters": {
"url": "https://cloud.langfuse.com/api/public/ingestion",
"method": "POST",
"options": {},
"jsonBody": "={{ { batch: $json.batch } }}",
"sendBody": true,
"sendHeaders": true,
"specifyBody": "json",
"authentication": "genericCredentialType",
"genericAuthType": "httpBasicAuth",
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
}
},
"credentials": {
"httpBasicAuth": {
"id": "uX87P9QjH9rMCMiY",
"name": "Unnamed credential"
}
},
"typeVersion": 4.2
},
{
"id": "7108e1e5-975d-43ed-a877-990544994b50",
"name": "Wait1",
"type": "n8n-nodes-base.wait",
"position": [
1820,
60
],
"webhookId": "4fdb5c55-03c9-4b96-b021-e91b2d1c09aa",
"parameters": {
"amount": 3
},
"typeVersion": 1.1
},
{
"id": "8665bccf-5646-4544-ac39-fcefceec9e28",
"name": "Remove Duplicates",
"type": "n8n-nodes-base.removeDuplicates",
"position": [
220,
0
],
"parameters": {
"options": {}
},
"typeVersion": 2
},
{
"id": "3bdd9fdb-2508-46b4-b167-62dcfedcd71b",
"name": "Wait to get an execution data",
"type": "n8n-nodes-base.wait",
"position": [
440,
0
],
"webhookId": "339e09b8-4206-46c9-9f30-dca7fd6ab0fb",
"parameters": {
"amount": 80
},
"typeVersion": 1.1
},
{
"id": "93852674-c6a5-415f-b532-f70c14f24151",
"name": "Code: structure execution data",
"type": "n8n-nodes-base.code",
"position": [
880,
0
],
"parameters": {
"jsCode": "function toArray(x){return Array.isArray(x)?x:(x==null?[]:[x]);}\nfunction safeGet(obj, path, fallback=undefined){\n try { return path.split(\".\").reduce((o,k)=>o==null?undefined:o[k], obj) ?? fallback; }\n catch { return fallback; }\n}\nfunction flattenMessages(msgs){\n const arr = Array.isArray(msgs)?msgs:(msgs==null?[]:[msgs]);\n return { array: arr, joined: arr.join(\"\\n\") };\n}\n\nconst raw = $input.first().json;\nconst exec = Array.isArray(raw) ? raw[0] : raw;\n\nconst runData = safeGet(exec, \"data.resultData.runData\", {});\nconst workflow = safeGet(exec, \"workflowData\", {});\nconst startedAt = new Date(exec.startedAt || exec.createdAt || Date.now());\nconst stoppedAt = new Date(exec.stoppedAt || Date.now());\nconst executionMs = Math.max(0, stoppedAt - startedAt);\n\n// Build lookups by node and executionIndex\nconst nodeRuns = {};\nfor (const [nodeName, runs] of Object.entries(runData)) {\n const arr = toArray(runs);\n const byIndex = new Map();\n const indices = [];\n for (const r of arr) {\n const idx = Number(r?.executionIndex);\n if (Number.isFinite(idx)) {\n byIndex.set(idx, r);\n indices.push(idx);\n }\n }\n indices.sort((a,b)=>a-b);\n nodeRuns[nodeName] = { all: arr, byIndex, indices };\n}\n\n// Precompute candidate prompt nodes: names starting with \"Get a prompt\"\nconst promptNodeNames = Object.keys(nodeRuns).filter(n => n.startsWith(\"Get a prompt\"));\n\n// Aggregated latency per node\nconst perNodeLatency = Object.entries(runData).reduce((acc, [nodeName, runs]) => {\n const arr = toArray(runs);\n const times = [];\n for (const r of arr) {\n const t = Number(r?.executionTime ?? 0);\n if (!Number.isNaN(t) && t >= 0) times.push(t);\n }\n const sum = times.reduce((s,v)=>s+v,0);\n const count = times.length;\n const avg = count ? sum / count : 0;\n acc[nodeName] = { count, sumMs: sum, avgMs: avg, samplesMs: times };\n return acc;\n}, {});\n\n// nearest index ≤ target\nfunction nearestLE(indices, target){\n if (!indices || indices.length === 0) return undefined;\n let lo = 0, hi = indices.length - 1, best;\n while (lo <= hi) {\n const mid = (lo + hi) >> 1;\n const v = indices[mid];\n if (v === target) return v;\n if (v < target) { best = v; lo = mid + 1; }\n else { hi = mid - 1; }\n }\n return best;\n}\n\n// Choose the best \"Get a prompt*\" run for a given LLM run index\nfunction choosePromptRunForIndex(idx, prevNodeName) {\n if (!Number.isFinite(idx) || promptNodeNames.length === 0) return { nodeName: \"\", run: undefined };\n\n // 1) If prevNode is a \"Get a prompt*\" node, try to use it first\n if (prevNodeName && prevNodeName.startsWith(\"Get a prompt\") && nodeRuns[prevNodeName]) {\n const group = nodeRuns[prevNodeName];\n let run = group.byIndex.get(idx - 1);\n if (!run) {\n const near = nearestLE(group.indices, idx);\n if (near != null) run = group.byIndex.get(near);\n }\n if (!run && group.indices.length) {\n run = group.byIndex.get(group.indices[group.indices.length - 1]);\n }\n if (run) return { nodeName: prevNodeName, run };\n }\n\n // 2) Otherwise, scan all prompt nodes and pick the closest to (idx - 1)\n let best = { nodeName: \"\", run: undefined, score: Infinity, diff: Infinity };\n const target = idx - 1;\n\n for (const name of promptNodeNames) {\n const group = nodeRuns[name];\n if (!group || group.indices.length === 0) continue;\n\n // Try exact (idx-1)\n let candidate = group.byIndex.get(target);\n let candIdx = candidate ? target : undefined;\n\n if (!candidate) {\n // nearest ≤ idx\n const near = nearestLE(group.indices, idx);\n if (near != null) {\n candidate = group.byIndex.get(near);\n candIdx = near;\n }\n }\n if (!candidate) {\n // fallback: last run\n const lastIdx = group.indices[group.indices.length - 1];\n candidate = group.byIndex.get(lastIdx);\n candIdx = lastIdx;\n }\n if (!candidate || candIdx == null) continue;\n\n const diff = Math.abs(candIdx - target);\n const penalty = candIdx <= idx ? 0 : 0.5;\n const score = diff + penalty;\n\n if (score < best.score) {\n best = { nodeName: name, run: candidate, score, diff };\n }\n }\n\n return { nodeName: best.nodeName, run: best.run };\n}\n\n// Resolve prompt from any \"Get a prompt*\" node (metadata only)\nfunction resolvePromptForRun(run) {\n const idx = Number(run?.executionIndex);\n const prevNode = safeGet(run, \"source.0.previousNode\", \"\");\n\n const { nodeName: chosenNode, run: promptRun } = choosePromptRunForIndex(idx, prevNode);\n if (!promptRun) return { promptName: \"\", promptVersion: undefined, promptText: \"\", promptNode: \"\" };\n\n const promptJson = safeGet(promptRun, \"data.main.0.0.json\", {});\n return {\n promptName: String(promptJson.name ?? \"\"),\n promptVersion: (promptJson.version != null) ? Number(promptJson.version) : undefined,\n promptText: String(promptJson.prompt ?? promptJson.text ?? \"\"),\n promptNode: chosenNode\n };\n}\n\n// Focus OpenAI Chat Model* runs (OpenAI Chat Model, OpenAI Chat Model1..N)\nconst openAiNodeNames = Object.keys(nodeRuns).filter(n =>\n n === \"OpenAI Chat Model\" || n.startsWith(\"OpenAI Chat Model\")\n);\nconst openAiRuns = [];\nfor (const name of openAiNodeNames) {\n const group = nodeRuns[name];\n if (!group) continue;\n for (const r of group.all) {\n openAiRuns.push({ run: r, nodeName: name });\n }\n}\n\n// Helper: extract only the part after the last \"Human:\" (or \"User:\") tag,\n// and strip leading punctuation like \":\" or \"-\" and whitespace/newlines.\nfunction extractHumanPortion(text){\n if (!text) return \"\";\n const tags = [\"Human:\", \"User:\"];\n let lastPos = -1;\n let lastTag = \"\";\n for (const tag of tags) {\n const pos1 = text.lastIndexOf(\"\\n\" + tag);\n const pos2 = text.lastIndexOf(tag);\n const pos = Math.max(pos1, pos2);\n if (pos > lastPos) { lastPos = pos; lastTag = tag; }\n }\n if (lastPos === -1) return text;\n let start = lastPos;\n if (text.slice(start, start + 1) === \"\\n\") start += 1;\n start += lastTag.length;\n let out = text.slice(start);\n out = out.replace(/^[:\\-–—\\s]+/, \"\");\n return out;\n}\n\n// Robust completion text extractor across variants\nfunction getCompletionText(r){\n // Common n8n LangChain variants\n const paths = [\n \"data.ai_languageModel.0.0.json.response.generations.0.0.text\",\n \"data.ai_languageModel.0.0.json.response.generations.0.text\",\n \"data.ai_languageModel.0.0.json.response.generations.0.message.content\",\n \"data.ai_languageModel.0.0.json.response.generations.0.0.message.content\",\n // Sometimes under data.main\n \"data.main.0.0.json.response.generations.0.0.text\",\n \"data.main.0.0.json.response.generations.0.text\",\n \"data.main.0.0.json.response.generations.0.message.content\",\n \"data.main.0.0.json.response.generations.0.0.message.content\",\n // OpenAI-style choices if ever passed through\n \"data.ai_languageModel.0.0.json.response.choices.0.message.content\",\n \"data.main.0.0.json.response.choices.0.message.content\",\n // Fallback simple text\n \"data.ai_languageModel.0.0.json.response.text\",\n \"data.main.0.0.json.response.text\"\n ];\n for (const p of paths) {\n const v = safeGet(r, p);\n if (typeof v === \"string\" && v.length) return v;\n }\n return \"\";\n}\n\n// Collect all LLM runs with input/output fields\nconst perRun = [];\nfor (const { run: r, nodeName: llmNodeName } of openAiRuns) {\n const model =\n safeGet(r, \"inputOverride.ai_languageModel.0.0.json.options.model\") ||\n safeGet(r, \"inputOverride.ai_languageModel.0.0.json.model\") ||\n \"unknown-model\";\n\n const promptTokens = Number(safeGet(r, \"data.ai_languageModel.0.0.json.tokenUsage.promptTokens\", 0));\n const completionTokens = Number(safeGet(r, \"data.ai_languageModel.0.0.json.tokenUsage.completionTokens\", 0));\n const totalTokensRaw = Number(safeGet(r, \"data.ai_languageModel.0.0.json.tokenUsage.totalTokens\", 0));\n const totalTokens = totalTokensRaw || (promptTokens + completionTokens);\n\n // Input to AI node: messages array under inputOverride\n const messages = safeGet(r, \"inputOverride.ai_languageModel.0.0.json.messages\", []);\n const promptFromMessages = flattenMessages(messages);\n const inputTextAll = promptFromMessages.joined || \"\";\n const inputTextHumanOnly = extractHumanPortion(inputTextAll);\n\n // Output text (robust)\n const completionText = getCompletionText(r);\n\n const nodeName =\n safeGet(r, \"source.0.previousNode\") ||\n safeGet(r, \"metadata.subRun.0.node\") ||\n llmNodeName ||\n \"Unknown Node\";\n\n // Keep prompt metadata from \"Get a prompt*\" for reference (name/version/node)\n const { promptName, promptVersion, promptText, promptNode } = resolvePromptForRun(r);\n\n const latencyMs = Number(r?.executionTime ?? 0);\n\n // Previews\n const promptPreview = (inputTextHumanOnly || \"\").slice(0, 2000);\n const completionPreview = (completionText || \"\").slice(0, 2000);\n\n perRun.push({\n model,\n nodeName,\n latencyMs,\n promptTokens,\n completionTokens,\n totalTokens,\n promptName, // metadata only\n promptVersion, // metadata only\n promptText: inputTextHumanOnly, // canonical input (Human-only)\n promptJoined: inputTextHumanOnly,\n completionText,\n promptPreview,\n completionPreview,\n promptNode: promptNode || \"\"\n });\n}\n\n// Aggregate per model\nconst perModelMap = new Map();\nfor (const r of perRun) {\n if (!perModelMap.has(r.model)) {\n perModelMap.set(r.model, {\n model: r.model,\n runs: 0,\n promptTokens: 0,\n completionTokens: 0,\n totalTokens: 0,\n nodeNamesSet: new Set(),\n nodeNameCounts: new Map(),\n examples: [],\n latencyByNode: new Map(),\n });\n }\n const m = perModelMap.get(r.model);\n m.runs += 1;\n m.promptTokens += r.promptTokens;\n m.completionTokens += r.completionTokens;\n m.totalTokens += r.totalTokens;\n m.nodeNamesSet.add(r.nodeName);\n m.nodeNameCounts.set(r.nodeName, (m.nodeNameCounts.get(r.nodeName) || 0) + 1);\n\n if (!m.latencyByNode.has(r.nodeName)) m.latencyByNode.set(r.nodeName, { sumMs: 0, count: 0 });\n const agg = m.latencyByNode.get(r.nodeName);\n if (Number.isFinite(r.latencyMs) && r.latencyMs >= 0) {\n agg.sumMs += r.latencyMs;\n agg.count += 1;\n }\n\n if (m.examples.length < 2) {\n m.examples.push({\n promptPreview: (r.promptJoined || \"\").slice(0, 200),\n completionPreview: (r.completionText || \"\").slice(0, 200),\n });\n }\n}\n\nconst perModel = Array.from(perModelMap.values()).map(m => {\n const latencyMsByNode = Array.from(m.latencyByNode.entries()).map(([nodeName, a]) => ({\n nodeName,\n sumMs: a.sumMs,\n count: a.count,\n avgMs: a.count ? a.sumMs / a.count : 0,\n })).sort((a,b)=>a.nodeName.localeCompare(b.nodeName));\n\n return {\n model: m.model,\n runs: m.runs,\n promptTokens: m.promptTokens,\n completionTokens: m.completionTokens,\n totalTokens: m.totalTokens,\n nodeNames: Array.from(m.nodeNamesSet).sort(),\n nodeNameCounts: Array.from(m.nodeNameCounts.entries())\n .map(([nodeName, runs]) => ({ nodeName, runs }))\n .sort((a,b)=>a.nodeName.localeCompare(b.nodeName)),\n latencyMsByNode,\n examples: m.examples,\n };\n});\n\nconst totals = perModel.reduce((acc,m)=>{\n acc.models += 1;\n acc.runs += m.runs;\n acc.promptTokens += m.promptTokens;\n acc.completionTokens += m.completionTokens;\n acc.totalTokens += m.totalTokens;\n return acc;\n}, { models:0, runs:0, promptTokens:0, completionTokens:0, totalTokens:0 });\n\nconst summary = {\n workflowId: workflow.id || exec.workflowId || \"\",\n workflowName: workflow.name || \"n8n-workflow\",\n executionId: String(exec.id || \"\"),\n startedAt: startedAt.toISOString(),\n stoppedAt: stoppedAt.toISOString(),\n executionMs,\n executionSec: executionMs / 1000,\n perModel,\n totals,\n firstPrompt: perRun[0]?.promptJoined || \"\",\n firstCompletion: perRun[0]?.completionText || \"\",\n lastPrompt: perRun[perRun.length - 1]?.promptJoined || \"\",\n lastCompletion: perRun[perRun.length - 1]?.completionText || \"\",\n};\n\n// Flat runs for downstream nodes\nconst perModelRuns = perRun.map(r => ({\n model: r.model,\n nodeName: r.nodeName,\n latencyMs: r.latencyMs,\n promptTokens: r.promptTokens,\n completionTokens: r.completionTokens,\n totalTokens: r.totalTokens,\n promptName: r.promptName || \"\",\n promptVersion: r.promptVersion,\n promptText: r.promptText || \"\", // Human-only input\n promptPreview: r.promptPreview, // Human-only preview\n completionPreview: r.completionPreview,\n promptNode: r.promptNode || \"\"\n}));\n\nreturn [{\n json: {\n workflowId: summary.workflowId,\n workflowName: summary.workflowName,\n executionId: summary.executionId,\n startedAt: summary.startedAt,\n stoppedAt: summary.stoppedAt,\n executionMs: summary.executionMs,\n executionSec: summary.executionSec,\n totals_promptTokens: totals.promptTokens,\n totals_completionTokens: totals.completionTokens,\n totals_totalTokens: totals.totalTokens,\n perNodeLatency,\n perModel,\n perModelRuns,\n summary\n }\n}];"
},
"typeVersion": 2
},
{
"id": "4f571c0d-a993-469c-b4cb-aead0a9f9d47",
"name": "Code: prepare JSON for LF",
"type": "n8n-nodes-base.code",
"position": [
1600,
60
],
"parameters": {
"jsCode": "const batch = [];\n\n// Stable identifiers for the whole execution\nconst executionId = String($json.executionId || $execution.id);\nconst traceId = `trace-${executionId}`;\n\n// Grouping: one session per workflow (adjust)\nconst sessionId = `session-${$json.workflowId || 'unknown'}`;\n\n// Pull per-run fields\nconst run = $json.perModelRuns || {};\nconst model = run.model === \"gpt-4.1-mini\" ? \"gpt-4o-mini\" : (run.model || \"unknown\");\nconst inputText = run.promptText || run.promptPreview || \"\";\nconst outputText = run.completionPreview || \"\";\nconst latencyMs = Number(run.latencyMs ?? 1);\nconst safeLatency = Number.isFinite(latencyMs) && latencyMs > 0 ? latencyMs : 1;\n\n// Timing\nconst end = Date.now();\nconst start = end - safeLatency;\n\n// Prompt naming\nconst promptName = run.promptName || $json.promptName || $json.nodeName || \"Prompt\";\nconst promptVersion = ($json.promptVersion != null) ? Number($json.promptVersion) : null;\n\n// Prompt link\nconst promptBaseUrl = \"https://cloud.langfuse.com/project/cmdpyxcw40047ad072og9tzqg/prompts/\";\nconst promptLink = promptBaseUrl + encodeURIComponent(String(promptName || \"\").trim());\n\n// Build events\nconst traceEventId = `evt-trace-${traceId}`;\nconst genEventId = `evt-gen-${traceId}-${$itemIndex != null ? $itemIndex : 0}-${end}`;\n\n// TRACE (idempotent)\nbatch.push({\n id: traceEventId,\n timestamp: new Date().toISOString(),\n type: \"trace-create\",\n body: {\n id: traceId,\n timestamp: new Date().toISOString(),\n name: $json.workflowName || promptName,\n userId: `workflow-${$json.workflowId || 'unknown'}`,\n sessionId,\n tags: [\"n8n\", \"execution\", $json.nodeName || \"node\"],\n input: inputText,\n output: outputText,\n metadata: {\n source: \"n8n\",\n workflowId: $json.workflowId,\n workflowName: $json.workflowName,\n executionId,\n promptName,\n promptVersion,\n promptLink,\n workflowTotalTokens: Number($json.totals_totalTokens) || 0,\n workflowPromptTokens: Number($json.totals_promptTokens) || 0,\n workflowCompletionTokens: Number($json.totals_completionTokens) || 0\n }\n }\n});\n\n// GENERATION\nbatch.push({\n id: genEventId,\n timestamp: new Date().toISOString(),\n type: \"generation-create\",\n body: {\n id: `gen-${traceId}-${end}`,\n traceId,\n timestamp: new Date().toISOString(),\n name: promptName,\n model,\n input: inputText,\n output: outputText,\n startTime: new Date(start).toISOString(),\n endTime: new Date(end).toISOString(),\n usage: {\n promptTokens: Number(run.promptTokens) || 0,\n completionTokens: Number(run.completionTokens) || 0,\n totalTokens: Number(run.totalTokens) || 0\n },\n metadata: {\n workflowId: $json.workflowId,\n workflowName: $json.workflowName,\n executionId,\n promptName,\n promptVersion,\n promptLink,\n latencyMs: safeLatency\n }\n }\n});\n\nreturn { json: { batch } };"
},
"typeVersion": 2
},
{
"id": "d18ab1bc-c40b-4777-af2d-46c9ac0f34fa",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-20,
200
],
"parameters": {
"width": 680,
"height": 1120,
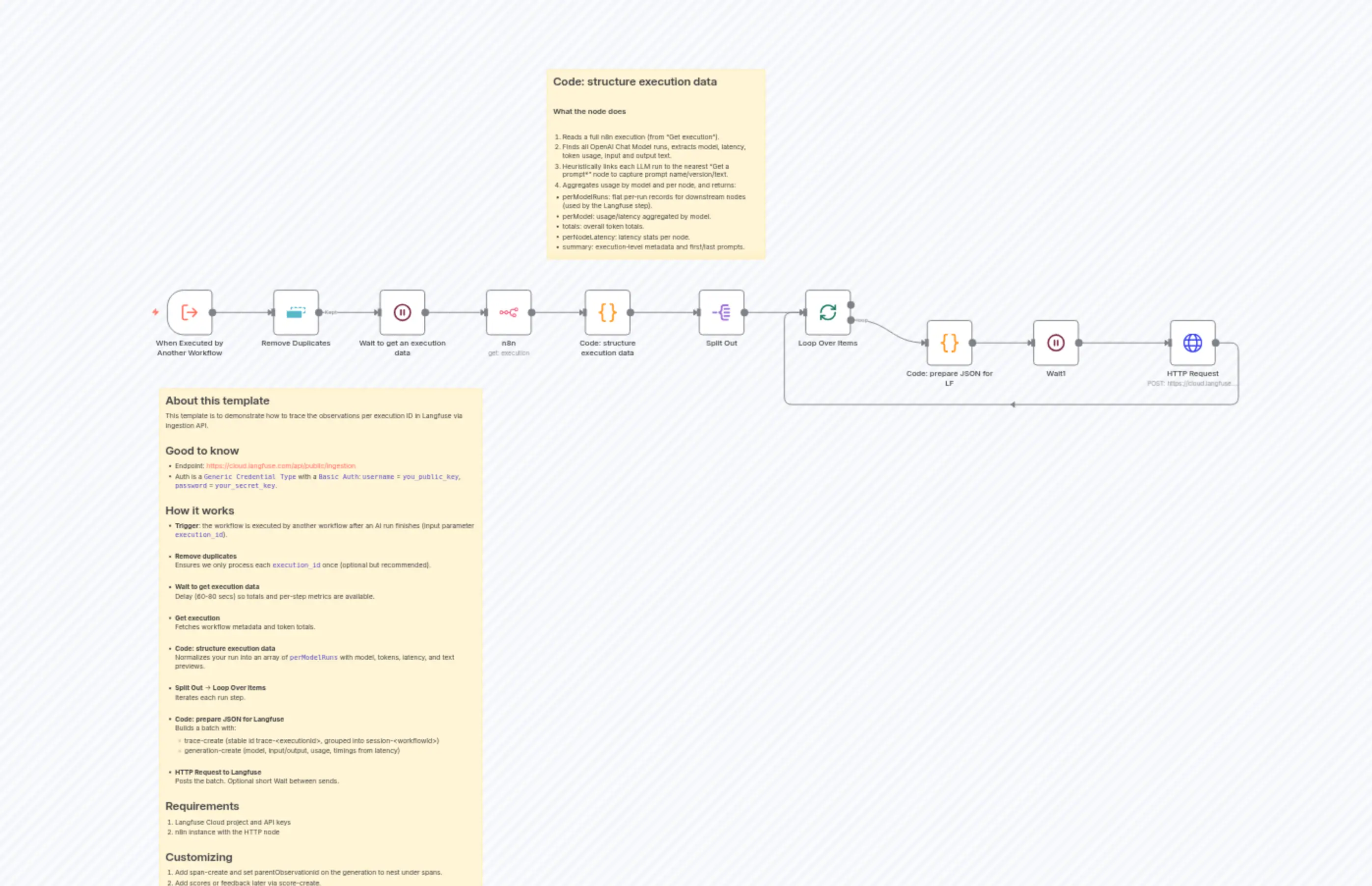
"content": "## About this template\nThis template is to demonstrate how to trace the observations per execution ID in Langfuse via ingestion API.\n\n## Good to know\n* Endpoint: https://cloud.langfuse.com/api/public/ingestion\n* Auth is a `Generic Credential Type` with a `Basic Auth`: `username` = `you_public_key`, `password` = `your_secret_key`.\n\n## How it works\n* **Trigger**: the workflow is executed by another workflow after an AI run finishes (input parameter `execution_id`).\n\n* **Remove duplicates**\nEnsures we only process each `execution_id` once (optional but recommended).\n\n* **Wait to get execution data**\nDelay (60-80 secs) so totals and per-step metrics are available.\n\n* **Get execution**\nFetches workflow metadata and token totals.\n\n* **Code: structure execution data**\nNormalizes your run into an array of `perModelRuns` with model, tokens, latency, and text previews.\n\n* **Split Out** → **Loop Over Items**\nIterates each run step.\n\n* **Code: prepare JSON for Langfuse**\n Builds a batch with:\n * trace-create (stable id trace-<executionId>, grouped into session-<workflowId>) \n * generation-create (model, input/output, usage, timings from latency)\n\n\n* **HTTP Request to Langfuse**\nPosts the batch. Optional short Wait between sends.\n\n## Requirements\n1. Langfuse Cloud project and API keys\n2. n8n instance with the HTTP node\n\n## Customizing\n1. Add span-create and set parentObservationId on the generation to nest under spans.\n2. Add scores or feedback later via score-create.\n3. Replace `sessionId` strategy (per workflow, per user, etc.). If some steps don’t produce tokens, compute and set usage yourself before sending."
},
"typeVersion": 1
},
{
"id": "f7c974c4-4fe1-4359-8d8d-954f062f245c",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
800,
-460
],
"parameters": {
"width": 460,
"height": 400,
"content": "## Code: structure execution data\n\n### What the node does\n\n1. Reads a full n8n execution (from “Get execution”).\n2. Finds all OpenAI Chat Model runs, extracts model, latency, token usage, input and output text.\n3. Heuristically links each LLM run to the nearest “Get a prompt*” node to capture prompt name/version/text.\n4. Aggregates usage by model and per node, and returns:\n* perModelRuns: flat per‑run records for downstream nodes (used by the Langfuse step).\n* perModel: usage/latency aggregated by model.\n* totals: overall token totals.\n* perNodeLatency: latency stats per node.\n* summary: execution‑level metadata and first/last prompts."
},
"typeVersion": 1
}
],
"active": false,
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"versionId": "418b6a95-03df-428c-825f-387362823aad",
"connections": {
"n8n": {
"main": [
[
{
"node": "Code: structure execution data",
"type": "main",
"index": 0
}
]
]
},
"Wait1": {
"main": [
[
{
"node": "HTTP Request",
"type": "main",
"index": 0
}
]
]
},
"Split Out": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"HTTP Request": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[],
[
{
"node": "Code: prepare JSON for LF",
"type": "main",
"index": 0
}
]
]
},
"Remove Duplicates": {
"main": [
[
{
"node": "Wait to get an execution data",
"type": "main",
"index": 0
}
]
]
},
"Code: prepare JSON for LF": {
"main": [
[
{
"node": "Wait1",
"type": "main",
"index": 0
}
]
]
},
"Wait to get an execution data": {
"main": [
[
{
"node": "n8n",
"type": "main",
"index": 0
}
]
]
},
"Code: structure execution data": {
"main": [
[
{
"node": "Split Out",
"type": "main",
"index": 0
}
]
]
},
"When Executed by Another Workflow": {
"main": [
[
{
"node": "Remove Duplicates",
"type": "main",
"index": 0
}
]
]
}
}
}