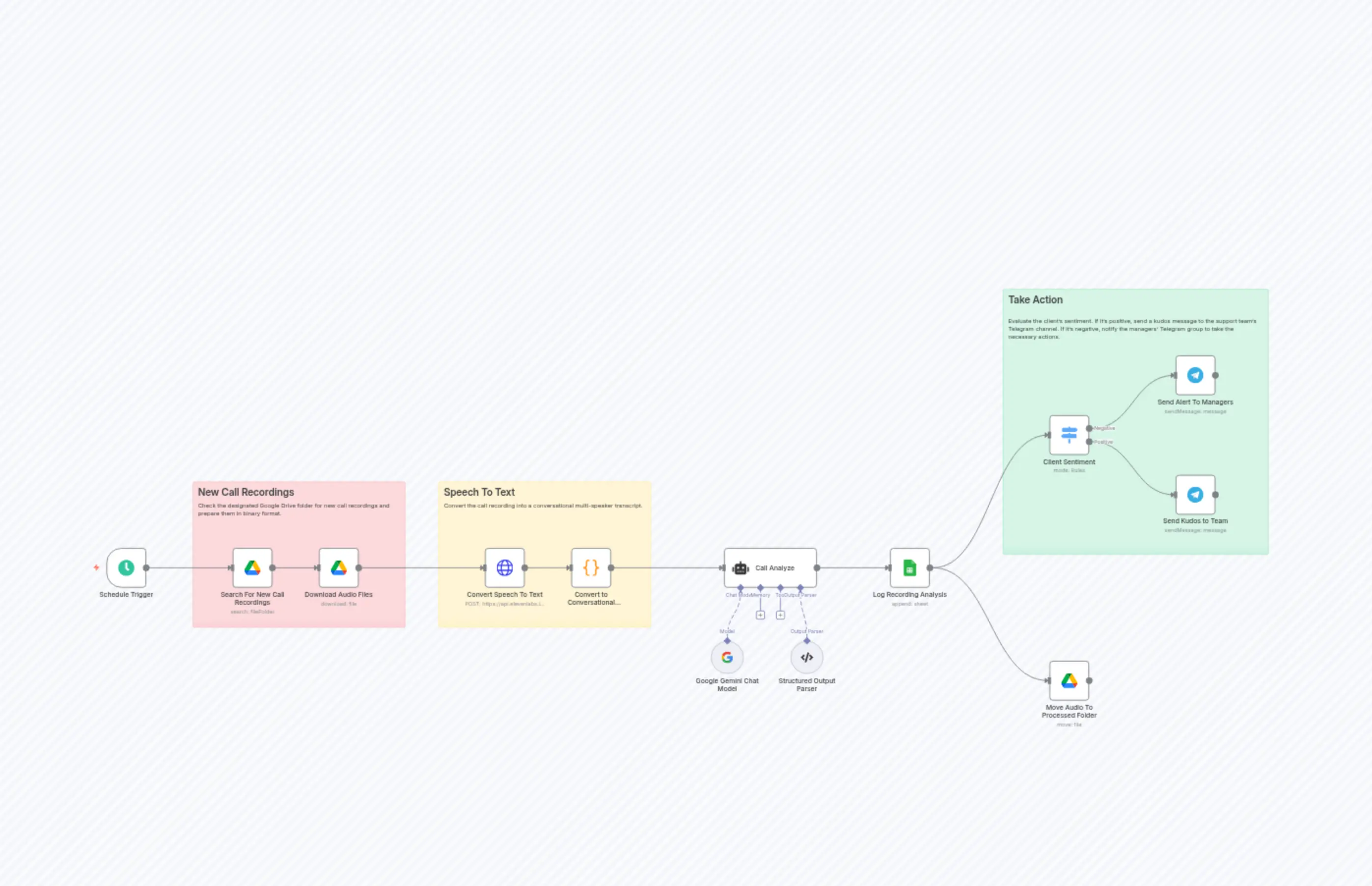
Support Call Analysis & Routing with Gemini AI, ElevenLabs & Telegram Alerts
描述
分类
🤖 AI & Machine Learning
使用的节点
n8n-nodes-base.coden8n-nodes-base.switchn8n-nodes-base.telegramn8n-nodes-base.telegramn8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.googleDriven8n-nodes-base.googleDriven8n-nodes-base.googleDrive
价格免费
浏览量0
最后更新11/28/2025
workflow.json
{
"meta": {
"instanceId": "afca6c018fd85ecd6bb793dc620b1f9d2de9ea7edb2532dd2708b1a0cf01d640",
"templateCredsSetupCompleted": true
},
"nodes": [
{
"id": "9a21ebb6-763a-4d2c-b91f-f135e24cc3c3",
"name": "Schedule Trigger",
"type": "n8n-nodes-base.scheduleTrigger",
"position": [
-720,
-80
],
"parameters": {
"rule": {
"interval": [
{
"field": "minutes",
"minutesInterval": 1
}
]
}
},
"typeVersion": 1.2
},
{
"id": "73d1c0b8-49e1-4ce8-af80-106ac1702acc",
"name": "Search For New Call Recordings",
"type": "n8n-nodes-base.googleDrive",
"position": [
-416,
-80
],
"parameters": {
"filter": {
"driveId": {
"__rl": true,
"mode": "list",
"value": "My Drive",
"cachedResultUrl": "https://drive.google.com/drive/my-drive",
"cachedResultName": "My Drive"
},
"folderId": {
"__rl": true,
"mode": "list",
"value": "1Kz8dGr8Hful3CeUJWjsbxktAEih3-Xjt",
"cachedResultUrl": "https://drive.google.com/drive/folders/1Kz8dGr8Hful3CeUJWjsbxktAEih3-Xjt",
"cachedResultName": "Company - Support Call Recordings"
},
"whatToSearch": "files"
},
"options": {},
"resource": "fileFolder",
"queryString": "mimeType = 'audio/wav'",
"searchMethod": "query"
},
"credentials": {
"googleDriveOAuth2Api": {
"id": "tX6IrS7GnpJZlmGG",
"name": "Google Drive account"
}
},
"typeVersion": 3
},
{
"id": "b0f31a61-f491-4d8c-8bb4-b8aa542fd4c8",
"name": "Google Gemini Chat Model",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
736,
144
],
"parameters": {
"options": {}
},
"credentials": {
"googlePalmApi": {
"id": "vppVWKsiofTY92Ht",
"name": "Google Gemini(PaLM) Api account"
}
},
"typeVersion": 1
},
{
"id": "9a1137fe-2fa0-4844-9c8d-b56e92e27f17",
"name": "Structured Output Parser",
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"position": [
928,
144
],
"parameters": {
"jsonSchemaExample": "{\n \"speaker_identification\": {\n \"agent\": \"speaker_id\",\n \"agent_name\": \"The agent's name if mentioned, otherwise 'Not mentioned'\",\n \"client\": \"speaker_id\",\n \"client_name\": \"The client's name if mentioned, otherwise 'Not mentioned'\"\n },\n \"summary\": \"A concise, one-paragraph summary of the entire conversation.\",\n \"client_sentiment\": \"Classify the client's overall sentiment as 'Positive', 'Negative', or 'Neutral'.\",\n \"call_topic\": \"A brief phrase describing the main reason for the call.\",\n \"department_tag\": \"The single most relevant department tag from the provided list.\",\n \"action_items\": [\n \"A list of clear, actionable tasks for the company or agent.\",\n \"A second action item if identified.\"\n ]\n}"
},
"typeVersion": 1.3
},
{
"id": "827a11ee-3f33-49e8-90ac-8a87a0e83bb5",
"name": "Send Alert To Managers",
"type": "n8n-nodes-base.telegram",
"position": [
1856,
-544
],
"webhookId": "b5ebab8b-da7a-4444-a62b-fb0c0d4c52c3",
"parameters": {
"text": "=*😠 Negative Call Alert*\n\nA call with negative sentiment has been flagged.\n\n*Agent:* `{{ $('Call Analyze').item.json.output.speaker_identification.agent_name }}`\n*Client:* `{{ $('Call Analyze').item.json.output.speaker_identification.client_name }}`\n*Topic:* `{{ $('Call Analyze').item.json.output.call_topic }}`\n\n*Summary:*\n> {{ $('Call Analyze').item.json.output.summary }}\n\n*Action Items:*\n{{ $json.Actions }}",
"chatId": "-4832906342",
"additionalFields": {
"appendAttribution": false
}
},
"credentials": {
"telegramApi": {
"id": "r3h7nm0gQ4NXYmcD",
"name": "Telegram account 2"
}
},
"typeVersion": 1.2
},
{
"id": "633c28f1-066c-4804-82aa-08f8a93100f2",
"name": "Send Kudos to Team",
"type": "n8n-nodes-base.telegram",
"position": [
1856,
-256
],
"webhookId": "b5ebab8b-da7a-4444-a62b-fb0c0d4c52c3",
"parameters": {
"text": "=*😊 Great Job!*\n\nKudos to *{{ $json.Agnent }}* for handling a positive call regarding *{{ $json.Topic }}*! Keep up the great work. ✨",
"chatId": "-1003053970420",
"additionalFields": {
"appendAttribution": false
}
},
"credentials": {
"telegramApi": {
"id": "r3h7nm0gQ4NXYmcD",
"name": "Telegram account 2"
}
},
"typeVersion": 1.2
},
{
"id": "d5e2a2a1-0c64-4b8d-81f2-64af3648032d",
"name": "Client Sentiment",
"type": "n8n-nodes-base.switch",
"position": [
1552,
-400
],
"parameters": {
"rules": {
"values": [
{
"outputKey": "Negative",
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "790e5d44-51a2-4132-b2d4-4dcd393e77fa",
"operator": {
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $('Call Analyze').item.json.output.client_sentiment }}",
"rightValue": "Negative"
}
]
},
"renameOutput": true
},
{
"outputKey": "Positive",
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "9b0236dc-4452-428a-add5-9764fc166d50",
"operator": {
"name": "filter.operator.equals",
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $('Call Analyze').item.json.output.client_sentiment }}",
"rightValue": "Positive"
}
]
},
"renameOutput": true
}
]
},
"options": {}
},
"typeVersion": 3.2
},
{
"id": "e962bcca-4d42-4c1a-ab50-6d9e944df94f",
"name": "Call Analyze",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
768,
-80
],
"parameters": {
"text": "=Analyze the following support call transcript according to the system instructions.\n\n---\n{{ $json.formattedTranscript }}\n---",
"options": {
"systemMessage": "=You are an expert AI assistant specializing in call center quality assurance and conversation analysis. Your task is to analyze a support call transcript, identify roles and names, and extract key information for routing and analytics.\n\nLook for names mentioned in the conversation (e.g., \"my name is Alex\", \"Hi, this is Sarah\"). Based on the call's topic, assign a single, most relevant department tag from the following list: [Billing, Technical Support, Sales, Customer Service, HR, Marketing].\n\nYou MUST provide your response exclusively in a valid JSON format. Do not add any explanatory text, greetings, or markdown formatting before or after the JSON object.\n\nThe JSON object must conform to the following structure:\n{\n \"speaker_identification\": {\n \"agent\": \"speaker_id\",\n \"agent_name\": \"The agent's name if mentioned, otherwise 'Not mentioned'\",\n \"client\": \"speaker_id\",\n \"client_name\": \"The client's name if mentioned, otherwise 'Not mentioned'\"\n },\n \"summary\": \"A concise, one-paragraph summary of the entire conversation.\",\n \"client_sentiment\": \"Classify the client's overall sentiment as 'Positive', 'Negative', or 'Neutral'.\",\n \"call_topic\": \"A brief phrase describing the main reason for the call.\",\n \"department_tag\": \"The single most relevant department tag from the provided list.\",\n \"action_items\": [\n \"A list of clear, actionable tasks for the company or agent.\",\n \"A second action item if identified.\"\n ]\n}"
},
"promptType": "define",
"hasOutputParser": true
},
"typeVersion": 2.2
},
{
"id": "40fa2621-945b-474a-bd51-8a31a43d8442",
"name": "Log Recording Analysis",
"type": "n8n-nodes-base.googleSheets",
"position": [
1168,
-80
],
"parameters": {
"columns": {
"value": {
"Topic": "={{ $json.output.call_topic }}",
"Agnent": "={{ $json.output.speaker_identification.agent_name }}",
"Client": "={{ $json.output.speaker_identification.client_name }}",
"Actions": "={{ '• '+$json.output.action_items.join('\\n• ')}}",
"Summary": "={{ $json.output.summary }}",
"Fulltext": "={{ $('Convert to Conversational Transcribe').item.json.formattedTranscript.replaceAll($json.output.speaker_identification.agent,$json.output.speaker_identification.agent_name.toLowerCase()=='not mentioned' ? 'Agent' : $json.output.speaker_identification.agent_name).replaceAll($json.output.speaker_identification.client,$json.output.speaker_identification.client_name.toLowerCase()=='not mentioned' ? 'Client' : $json.output.speaker_identification.client_name) }}",
"Sentiment": "={{ $json.output.client_sentiment }}",
"Department": "={{ $json.output.department_tag }}",
"Recording Filename": "={{ $('Download Audio Files').item.json.name }}"
},
"schema": [
{
"id": "Recording Filename",
"type": "string",
"display": true,
"required": false,
"displayName": "Recording Filename",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Sentiment",
"type": "string",
"display": true,
"required": false,
"displayName": "Sentiment",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Department",
"type": "string",
"display": true,
"required": false,
"displayName": "Department",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Topic",
"type": "string",
"display": true,
"required": false,
"displayName": "Topic",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Agnent",
"type": "string",
"display": true,
"required": false,
"displayName": "Agnent",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Client",
"type": "string",
"display": true,
"required": false,
"displayName": "Client",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Summary",
"type": "string",
"display": true,
"required": false,
"displayName": "Summary",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Actions",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "Actions",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Fulltext",
"type": "string",
"display": true,
"required": false,
"displayName": "Fulltext",
"defaultMatch": false,
"canBeUsedToMatch": true
}
],
"mappingMode": "defineBelow",
"matchingColumns": [],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {},
"operation": "append",
"sheetName": {
"__rl": true,
"mode": "list",
"value": "gid=0",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/182ds-RDJ2RcNo1xmx0EucXkmBAlBJe-muhnN78My3wc/edit#gid=0",
"cachedResultName": "Logs"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "182ds-RDJ2RcNo1xmx0EucXkmBAlBJe-muhnN78My3wc",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/182ds-RDJ2RcNo1xmx0EucXkmBAlBJe-muhnN78My3wc/edit?usp=drivesdk",
"cachedResultName": "Call Recording Process Results"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"id": "rg3jSc3UMNbC7pZ8",
"name": "Google Sheets account"
}
},
"typeVersion": 4.7
},
{
"id": "d4263888-9284-4be1-8f44-3bd1ec785c54",
"name": "Download Audio Files",
"type": "n8n-nodes-base.googleDrive",
"position": [
-208,
-80
],
"parameters": {
"fileId": {
"__rl": true,
"mode": "id",
"value": "={{ $json.id }}"
},
"options": {},
"operation": "download"
},
"credentials": {
"googleDriveOAuth2Api": {
"id": "tX6IrS7GnpJZlmGG",
"name": "Google Drive account"
}
},
"typeVersion": 3
},
{
"id": "fe3de287-6e9f-4f2a-a132-ec3c03555250",
"name": "Convert to Conversational Transcribe",
"type": "n8n-nodes-base.code",
"position": [
400,
-80
],
"parameters": {
"mode": "runOnceForEachItem",
"jsCode": "// Get the array of words from the input JSON provided by ElevenLabs\n// It assumes the input data is in the format $json.words or $items[0].json.words\nconst words = $json.words;\n\n// If there are no words, return an empty transcript\nif (!words || words.length === 0) {\n return { json: { transcript: \"\" } };\n}\n\nlet transcript = \"\";\nlet currentSpeaker = null;\nlet currentLine = \"\";\n\n// Loop through each word object provided by the API\nfor (const word of words) {\n const speakerId = word.speaker_id;\n \n // Check if this is the very first word\n if (currentSpeaker === null) {\n currentSpeaker = speakerId;\n // Format the speaker ID for better readability (e.g., 'speaker_0' becomes 'Speaker 0')\n const formattedSpeaker = `Speaker ${speakerId.split('_')[1]}`;\n currentLine = `${formattedSpeaker}: ${word.text}`;\n continue;\n }\n\n // If the speaker changes, add the completed line to the transcript and start a new one\n if (speakerId !== currentSpeaker) {\n transcript += currentLine.trim() + \"\\n\"; // Add the previous line and a newline\n currentSpeaker = speakerId;\n const formattedSpeaker = `Speaker ${speakerId.split('_')[1]}`;\n currentLine = `${formattedSpeaker}: ${word.text}`;\n } else {\n // If the same speaker continues, just add their word to the current line\n // The API includes spacing objects, so we just append the text\n currentLine += word.text;\n }\n}\n\n// Add the very last line to the transcript\ntranscript += currentLine.trim();\n\n// Return the final formatted transcript in a new n8n item\nreturn {\n json: {\n formattedTranscript: transcript\n }\n};"
},
"typeVersion": 2
},
{
"id": "c604ea35-a82d-45a9-87f1-22a24f120ab0",
"name": "Move Audio To Processed Folder",
"type": "n8n-nodes-base.googleDrive",
"position": [
1552,
192
],
"parameters": {
"fileId": {
"__rl": true,
"mode": "id",
"value": "={{ $('Download Audio Files').item.json.id }}"
},
"driveId": {
"__rl": true,
"mode": "list",
"value": "My Drive"
},
"folderId": {
"__rl": true,
"mode": "list",
"value": "1MDRPnlY6WYFwpR7WgNg2yhriq75gH8Bc",
"cachedResultUrl": "https://drive.google.com/drive/folders/1MDRPnlY6WYFwpR7WgNg2yhriq75gH8Bc",
"cachedResultName": "Processed Audio"
},
"operation": "move"
},
"credentials": {
"googleDriveOAuth2Api": {
"id": "tX6IrS7GnpJZlmGG",
"name": "Google Drive account"
}
},
"typeVersion": 3
},
{
"id": "38a5598e-18c5-4745-a5e5-80137527aa0a",
"name": "Convert Speech To Text",
"type": "n8n-nodes-base.httpRequest",
"position": [
192,
-80
],
"parameters": {
"url": "https://api.elevenlabs.io/v1/speech-to-text",
"method": "POST",
"options": {},
"sendBody": true,
"contentType": "multipart-form-data",
"sendHeaders": true,
"authentication": "genericCredentialType",
"bodyParameters": {
"parameters": [
{
"name": "file",
"parameterType": "formBinaryData",
"inputDataFieldName": "data"
},
{
"name": "diarize",
"value": "true"
},
{
"name": "model_id",
"value": "scribe_v1"
}
]
},
"genericAuthType": "httpHeaderAuth",
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "multipart/form-data"
}
]
}
},
"credentials": {
"httpHeaderAuth": {
"id": "2HyBr4oAJMr0xPur",
"name": "ElevenLabs"
}
},
"typeVersion": 4.2
},
{
"id": "d789c6cc-a8e0-4725-b222-bdb855dba2a9",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
80,
-240
],
"parameters": {
"width": 512,
"height": 352,
"content": "## Speech To Text \nConvert the call recording into a conversational multi-speaker transcript."
},
"typeVersion": 1
},
{
"id": "3c662a89-8cb6-4cb1-b52a-3524ac044591",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-512,
-240
],
"parameters": {
"color": 3,
"width": 512,
"height": 352,
"content": "## New Call Recordings\nCheck the designated Google Drive folder for new call recordings and prepare them in binary format."
},
"typeVersion": 1
},
{
"id": "1f90983e-ae47-44ea-97a6-642671b642c8",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
1440,
-704
],
"parameters": {
"color": 4,
"width": 640,
"height": 640,
"content": "## Take Action\n\nEvaluate the client’s sentiment. If it’s positive, send a kudos message to the support team’s Telegram channel. If it’s negative, notify the managers’ Telegram group to take the necessary actions."
},
"typeVersion": 1
}
],
"pinData": {},
"connections": {
"Call Analyze": {
"main": [
[
{
"node": "Log Recording Analysis",
"type": "main",
"index": 0
}
]
]
},
"Client Sentiment": {
"main": [
[
{
"node": "Send Alert To Managers",
"type": "main",
"index": 0
}
],
[
{
"node": "Send Kudos to Team",
"type": "main",
"index": 0
}
]
]
},
"Schedule Trigger": {
"main": [
[
{
"node": "Search For New Call Recordings",
"type": "main",
"index": 0
}
]
]
},
"Download Audio Files": {
"main": [
[
{
"node": "Convert Speech To Text",
"type": "main",
"index": 0
}
]
]
},
"Convert Speech To Text": {
"main": [
[
{
"node": "Convert to Conversational Transcribe",
"type": "main",
"index": 0
}
]
]
},
"Log Recording Analysis": {
"main": [
[
{
"node": "Move Audio To Processed Folder",
"type": "main",
"index": 0
},
{
"node": "Client Sentiment",
"type": "main",
"index": 0
}
]
]
},
"Google Gemini Chat Model": {
"ai_languageModel": [
[
{
"node": "Call Analyze",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Structured Output Parser": {
"ai_outputParser": [
[
{
"node": "Call Analyze",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"Move Audio To Processed Folder": {
"main": [
[]
]
},
"Search For New Call Recordings": {
"main": [
[
{
"node": "Download Audio Files",
"type": "main",
"index": 0
}
]
]
},
"Convert to Conversational Transcribe": {
"main": [
[
{
"node": "Call Analyze",
"type": "main",
"index": 0
}
]
]
}
}
}