Wikipedia Podcast Telegram Agent - Template
描述
分类
🤖 AI & Machine Learning📢 Marketing
使用的节点
n8n-nodes-base.setn8n-nodes-base.switchn8n-nodes-base.telegramn8n-nodes-base.telegramn8n-nodes-base.stickyNote@n8n/n8n-nodes-langchain.agentn8n-nodes-base.telegramTrigger@n8n/n8n-nodes-langchain.openAi@n8n/n8n-nodes-langchain.toolThink@n8n/n8n-nodes-langchain.toolWikipedia
价格免费
浏览量0
最后更新11/28/2025
workflow.json
{
"id": "zCH7mVwHTPMedQnn",
"meta": {
"instanceId": "7dfa146768a036d27a67d125f90ea637bfb301bd4fd25d0086548016421d44bd",
"templateCredsSetupCompleted": true
},
"name": "Wikipedia Podcast Telegram Agent - Template",
"tags": [],
"nodes": [
{
"id": "02ec8740-62ea-4803-aec0-93ec18f24be1",
"name": "Telegram Trigger",
"type": "n8n-nodes-base.telegramTrigger",
"position": [
-1000,
-80
],
"webhookId": "7d818408-495c-447b-9c56-2a67c783db27",
"parameters": {
"updates": [
"message"
],
"additionalFields": {}
},
"credentials": {
"telegramApi": {
"id": "Zq1NBOOoVJ5tyR1G",
"name": "Wikipedia Podcast Bot"
}
},
"typeVersion": 1.1
},
{
"id": "0820738d-45f2-49fe-8837-bd9fdbde5a25",
"name": "Anthropic Chat Model",
"type": "@n8n/n8n-nodes-langchain.lmChatAnthropic",
"position": [
-120,
140
],
"parameters": {
"model": {
"__rl": true,
"mode": "list",
"value": "claude-sonnet-4-20250514",
"cachedResultName": "Claude 4 Sonnet"
},
"options": {}
},
"credentials": {
"anthropicApi": {
"id": "WgfLltDtHqUy7q9O",
"name": "Anthropic account"
}
},
"typeVersion": 1.3
},
{
"id": "665f8751-48b8-46cc-bd76-d82127435ea2",
"name": "Wikipedia",
"type": "@n8n/n8n-nodes-langchain.toolWikipedia",
"position": [
0,
140
],
"parameters": {},
"typeVersion": 1
},
{
"id": "54b0a604-9e7c-43dc-899b-80432e1e9aa8",
"name": "Think",
"type": "@n8n/n8n-nodes-langchain.toolThink",
"position": [
120,
140
],
"parameters": {},
"typeVersion": 1
},
{
"id": "8c4ecbd4-e340-4017-9c73-eea76aecb30f",
"name": "Text or Voice",
"type": "n8n-nodes-base.switch",
"position": [
-780,
-80
],
"parameters": {
"rules": {
"values": [
{
"outputKey": "Text",
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "7c629699-9dd6-4a75-9b76-d796875f9ac9",
"operator": {
"type": "string",
"operation": "notEmpty",
"singleValue": true
},
"leftValue": "={{ $json.message.text }}",
"rightValue": ""
}
]
},
"renameOutput": true
},
{
"outputKey": "Voice",
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "0e56bc7f-c754-4f5e-9ddd-7124e1f5d998",
"operator": {
"type": "object",
"operation": "exists",
"singleValue": true
},
"leftValue": "={{ $json.message.voice }}",
"rightValue": ""
}
]
},
"renameOutput": true
}
]
},
"options": {}
},
"typeVersion": 3.2
},
{
"id": "4a62e7d8-204d-407e-a090-3dcad37c70b2",
"name": "Get Voice Message",
"type": "n8n-nodes-base.telegram",
"position": [
-560,
20
],
"webhookId": "3c23a290-0c65-447f-9e7f-f4d71226a8e9",
"parameters": {
"fileId": "={{ $json.message.voice.file_id }}",
"resource": "file"
},
"credentials": {
"telegramApi": {
"id": "Zq1NBOOoVJ5tyR1G",
"name": "Wikipedia Podcast Bot"
}
},
"typeVersion": 1.2
},
{
"id": "7c0a4950-13c5-401a-b9bc-3409cd8cde24",
"name": "Transcribe Voice Message",
"type": "@n8n/n8n-nodes-langchain.openAi",
"position": [
-340,
20
],
"parameters": {
"options": {},
"resource": "audio",
"operation": "transcribe"
},
"credentials": {
"openAiApi": {
"id": "x1byAha0t8ltLIeW",
"name": "OpenAi account"
}
},
"typeVersion": 1.8
},
{
"id": "73daa7c9-124f-4595-ae2a-de4aa9ce1cd4",
"name": "Prepare Text Message for AI Agent",
"type": "n8n-nodes-base.set",
"position": [
-340,
-180
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "a5bcf087-7580-4904-88d3-ca29614fc923",
"name": "text",
"type": "string",
"value": "={{ $json.message.text }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "c8d4fa95-94b4-47ae-9332-4cefe844d4f0",
"name": "ElevenLabs Text to Speech",
"type": "@elevenlabs/n8n-nodes-elevenlabs.elevenLabs",
"position": [
320,
-80
],
"parameters": {
"text": "={{ $json.output }}",
"voice": {
"__rl": true,
"mode": "list",
"value": "yUy9CCX9brt8aPVvIWy3",
"cachedResultName": "Ramona - Calm & Soothing Voice"
},
"resource": "speech",
"requestOptions": {},
"additionalOptions": {}
},
"credentials": {
"elevenLabsApi": {
"id": "MQAFsLdzC3NvDqyE",
"name": "ElevenLabs account"
}
},
"typeVersion": 1
},
{
"id": "119ec323-c887-45ac-bd9d-b1b7691789df",
"name": "Send Voice Response",
"type": "n8n-nodes-base.telegram",
"position": [
540,
-80
],
"webhookId": "ffe71aef-85a4-4a81-b220-4632e19d6982",
"parameters": {
"chatId": "={{ $('Telegram Trigger').item.json.message.chat.id }}",
"operation": "sendAudio",
"binaryData": true,
"additionalFields": {
"caption": "=🎙️ Wikipedia-Podcast: {{ $('Telegram Trigger').item.json.message.text }}",
"fileName": "={{ $('Telegram Trigger').item.json.message.text }}.mp3"
}
},
"credentials": {
"telegramApi": {
"id": "Zq1NBOOoVJ5tyR1G",
"name": "Wikipedia Podcast Bot"
}
},
"typeVersion": 1.2
},
{
"id": "c2e46d2f-01e9-4512-b44d-5b2bae881341",
"name": "Wikipedia Podcast Agent",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
-88,
-80
],
"parameters": {
"text": "={{ $json.text }}",
"options": {
"systemMessage": "=You are a professional podcast host who creates captivating and informative 5-minute podcasts about Wikipedia articles. Your task is to produce an engaging, well-structured podcast from the topic mentioned by the user.\n\n## Your Working Method:\n\n1. **Research**: Use the Wikipedia tool to gather comprehensive information about the desired topic\n2. **Deep Dive**: Search for additional interesting details, backgrounds, and connections\n3. **Podcast Creation**: Create approximately a 5-minute podcast text (about 600-750 words)\n\n## Podcast Structure:\n\n**Intro (30-45 seconds)**\n- Greet the listeners warmly\n- Introduce the topic and spark curiosity\n- Give a brief preview of the most interesting aspects\n\n**Main Part (3.5-4 minutes)**\n- Tell the story chronologically or thematically structured\n- Emphasize particularly fascinating, surprising, or little-known facts\n- Use vivid descriptions and concrete examples\n- Make connections to current events or other well-known topics\n\n**Outro (30-45 seconds)**\n- Summarize the most important insights\n- Encourage reflection or pose an interesting concluding question\n- Say goodbye in a friendly manner\n\n## Style Guidelines:\n\n- **Conversational**: Speak as if you were telling a fascinating story to a friend\n- **Accessible**: Explain complex matters understandably without oversimplifying\n- **Enthusiastic**: Show your enthusiasm for the topic\n- **Structured**: Use clear transitions between sections\n- **Lively**: Use rhetorical questions, short pauses (marked with \"...\") and vary the pace\n- **Direct**: Continuously address the listeners with \"you\" - they are your conversation partners\n- **Tangible**: Translate large numbers and abstract statistics into understandable comparisons\n\n## Special Notes:\n\n- Pay attention to natural language suitable for speaking\n- Avoid overly long sentences or complicated nested clauses\n- Occasionally integrate \"By the way...\" or \"Did you know that...\" for additional facts\n- **No stage directions**: NEVER use brackets with music or sound cues like [INTRO MUSIC] or [OUTRO MUSIC]\n- **Make numbers tangible**: Translate large statistics into comparisons (e.g., \"As many people as live in all of Bavaria today\" instead of \"13 million\")\n- **Continuous listener address**: Use \"you\" throughout - the listeners are always directly addressed\n- Always ensure that all information comes from reliable Wikipedia sources\n\nNow create a captivating podcast about the desired topic!"
},
"promptType": "define"
},
"typeVersion": 2
},
{
"id": "d6dc5f36-789e-46df-88cd-2ad9b0be7d59",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1900,
-540
],
"parameters": {
"width": 820,
"height": 1140,
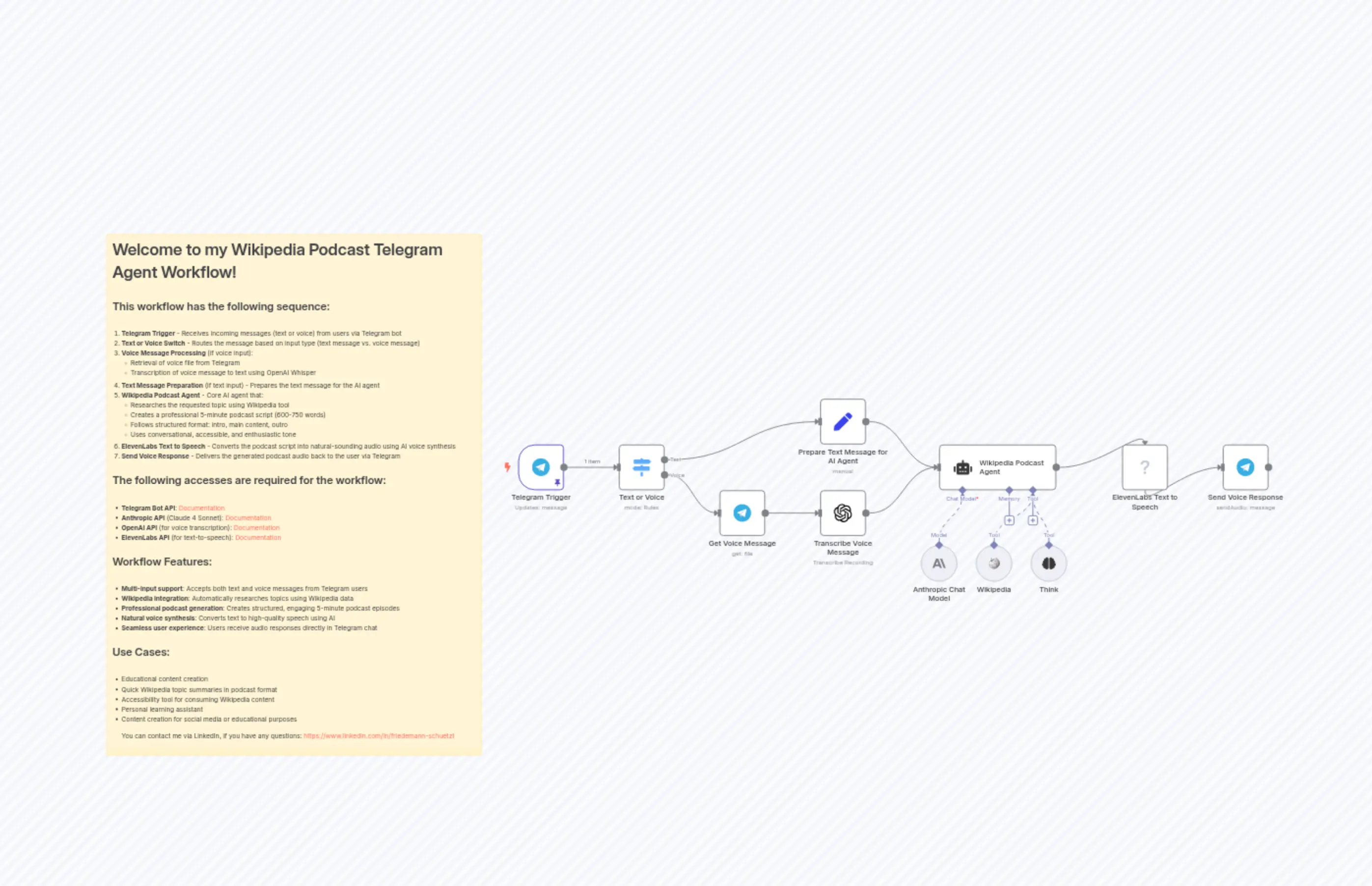
"content": "# Welcome to my Wikipedia Podcast Telegram Agent Workflow!\n\n## This workflow has the following sequence:\n\n1. **Telegram Trigger** - Receives incoming messages (text or voice) from users via Telegram bot\n2. **Text or Voice Switch** - Routes the message based on input type (text message vs. voice message)\n3. **Voice Message Processing** (if voice input):\n - Retrieval of voice file from Telegram\n - Transcription of voice message to text using OpenAI Whisper\n4. **Text Message Preparation** (if text input) - Prepares the text message for the AI agent\n5. **Wikipedia Podcast Agent** - Core AI agent that:\n - Researches the requested topic using Wikipedia tool\n - Creates a professional 5-minute podcast script (600-750 words)\n - Follows structured format: intro, main content, outro\n - Uses conversational, accessible, and enthusiastic tone\n6. **ElevenLabs Text to Speech** - Converts the podcast script into natural-sounding audio using AI voice synthesis\n7. **Send Voice Response** - Delivers the generated podcast audio back to the user via Telegram\n\n## The following accesses are required for the workflow:\n\n- **Telegram Bot API**: [Documentation](https://docs.n8n.io/integrations/builtin/credentials/telegram/)\n- **Anthropic API** (Claude 4 Sonnet): [Documentation](https://docs.n8n.io/integrations/builtin/credentials/anthropic/)\n- **OpenAI API** (for voice transcription): [Documentation](https://docs.n8n.io/integrations/builtin/credentials/openai/)\n- **ElevenLabs API** (for text-to-speech): [Documentation](https://github.com/n8n-ninja/n8n-nodes-elevenlabs?tab=readme-ov-fil/)\n\n## Workflow Features:\n\n- **Multi-input support**: Accepts both text and voice messages from Telegram users\n- **Wikipedia integration**: Automatically researches topics using Wikipedia data\n- **Professional podcast generation**: Creates structured, engaging 5-minute podcast episodes\n- **Natural voice synthesis**: Converts text to high-quality speech using AI\n- **Seamless user experience**: Users receive audio responses directly in Telegram chat\n\n## Use Cases:\n\n- Educational content creation\n- Quick Wikipedia topic summaries in podcast format\n- Accessibility tool for consuming Wikipedia content\n- Personal learning assistant\n- Content creation for social media or educational purposes\n\nYou can contact me via LinkedIn, if you have any questions: https://www.linkedin.com/in/friedemann-schuetzt "
},
"typeVersion": 1
}
],
"active": false,
"pinData": {
"Telegram Trigger": [
{
"json": {
"message": {
"chat": {
"id": 1810565648,
"type": "private",
"username": "FSEssen",
"first_name": "FS"
},
"date": 1748536655,
"from": {
"id": 1810565648,
"is_bot": false,
"username": "FSEssen",
"first_name": "FS",
"language_code": "de"
},
"text": "City of Essen",
"message_id": 6
},
"update_id": 958624919
}
}
]
},
"settings": {
"executionOrder": "v1"
},
"versionId": "5355ca40-6418-40b0-9b54-2add30a8bb1e",
"connections": {
"Think": {
"ai_tool": [
[
{
"node": "Wikipedia Podcast Agent",
"type": "ai_tool",
"index": 0
}
]
]
},
"Wikipedia": {
"ai_tool": [
[
{
"node": "Wikipedia Podcast Agent",
"type": "ai_tool",
"index": 0
}
]
]
},
"Text or Voice": {
"main": [
[
{
"node": "Prepare Text Message for AI Agent",
"type": "main",
"index": 0
}
],
[
{
"node": "Get Voice Message",
"type": "main",
"index": 0
}
]
]
},
"Telegram Trigger": {
"main": [
[
{
"node": "Text or Voice",
"type": "main",
"index": 0
}
]
]
},
"Get Voice Message": {
"main": [
[
{
"node": "Transcribe Voice Message",
"type": "main",
"index": 0
}
]
]
},
"Anthropic Chat Model": {
"ai_languageModel": [
[
{
"node": "Wikipedia Podcast Agent",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Wikipedia Podcast Agent": {
"main": [
[
{
"node": "ElevenLabs Text to Speech",
"type": "main",
"index": 0
}
]
]
},
"Transcribe Voice Message": {
"main": [
[
{
"node": "Wikipedia Podcast Agent",
"type": "main",
"index": 0
}
]
]
},
"ElevenLabs Text to Speech": {
"main": [
[
{
"node": "Send Voice Response",
"type": "main",
"index": 0
}
]
]
},
"Prepare Text Message for AI Agent": {
"main": [
[
{
"node": "Wikipedia Podcast Agent",
"type": "main",
"index": 0
}
]
]
}
}
}