Transcribe Long Audio Files Beyond 25MB Limit with FileFlows and OpenAI Whisper
描述
分类
🤖 AI & Machine Learning
使用的节点
n8n-nodes-base.ifn8n-nodes-base.setn8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.noOpn8n-nodes-base.noOpn8n-nodes-base.noOpn8n-nodes-base.noOpn8n-nodes-base.wait
价格免费
浏览量0
最后更新11/28/2025
workflow.json
{
"meta": {
"instanceId": "854c212d3baca2d6108faeb1187a4f6d9a3e60117068e7e872ad5e663327af93"
},
"nodes": [
{
"id": "64ef094b-c447-4dc3-a3c3-8b0d777b5759",
"name": "GET Form",
"type": "n8n-nodes-base.formTrigger",
"position": [
-2080,
624
],
"webhookId": "21d6b441-1469-4531-be4a-1d139651cccd",
"parameters": {
"options": {
"path": "audio-transcription",
"ignoreBots": false,
"respondWithOptions": {
"values": {
"formSubmittedText": "Your file has been received; an email will be sent to you upon completion of transcription or in case of error."
}
}
},
"formTitle": "Audio Transcription",
"formFields": {
"values": [
{
"fieldType": "file",
"fieldLabel": "file",
"requiredField": true,
"acceptFileTypes": ".mp3"
},
{
"fieldType": "email",
"fieldLabel": "email",
"requiredField": true
}
]
},
"formDescription": "Select an audio file to transcribe and an email address to receive the result."
},
"typeVersion": 2.3
},
{
"id": "7787660b-343e-49a0-8177-c77e263002fe",
"name": "Make 4MiB Chunks",
"type": "n8n-nodes-base.code",
"position": [
-1632,
624
],
"parameters": {
"jsCode": "// 4 MiB chunks (FileFlows UI)\nconst CHUNK_SIZE = $(\"Configuration\").first().json.chunk_size;\n\nconst item = items[0];\n\n// Get the file uploaded by the Form Trigger\n// (the field is named \"file\" → binary.file; fallback to the first binary found)\nconst bin =\n item.binary?.file ||\n (item.binary ? item.binary[Object.keys(item.binary)[0]] : null);\n\nif (!bin?.data) {\n throw new Error('No file received. Make sure the field is named \"file\".');\n}\n\nconst override =\n item.json?.fields?.fileNameOverride?.toString().trim() ||\n item.json?.fileNameOverride?.toString().trim() ||\n '';\n\nconst fileName = override || bin.fileName || 'upload.bin';\nconst mimeType = bin.mimeType || 'application/octet-stream';\n\nconst buf = Buffer.from(bin.data, 'base64');\nconst totalChunks = Math.max(1, Math.ceil(buf.length / CHUNK_SIZE));\n\nconst out = [];\nfor (let i = 0; i < totalChunks; i++) {\n const start = i * CHUNK_SIZE;\n const end = Math.min(start + CHUNK_SIZE, buf.length);\n const slice = buf.subarray(start, end);\n\n out.push({\n json: {\n fileName,\n chunkNumber: i, // 0-based like the UI\n totalChunks,\n size: slice.length\n },\n binary: {\n chunk: {\n data: slice.toString('base64'),\n fileName,\n mimeType\n }\n }\n });\n}\n\nreturn out;\n"
},
"typeVersion": 2
},
{
"id": "fc76d2f5-8ea6-4d8e-bf64-7772d1735860",
"name": "Upload Chunk",
"type": "n8n-nodes-base.httpRequest",
"position": [
-960,
688
],
"parameters": {
"url": "={{ $('Configuration').item.json.fileflows_url }}/api/library-file/upload",
"method": "POST",
"options": {},
"sendBody": true,
"contentType": "multipart-form-data",
"bodyParameters": {
"parameters": [
{
"name": "fileName",
"value": "={{$json[\"fileName\"]}}"
},
{
"name": "chunkNumber",
"value": "={{$json[\"chunkNumber\"]}}"
},
{
"name": "totalChunks",
"value": "={{$json[\"totalChunks\"]}}"
},
{
"name": "file",
"parameterType": "formBinaryData",
"inputDataFieldName": "chunk"
}
]
}
},
"typeVersion": 4.2
},
{
"id": "d0277bd8-7c34-4220-9005-4f1aa00c2409",
"name": "Result",
"type": "n8n-nodes-base.noOp",
"position": [
-1184,
384
],
"parameters": {},
"typeVersion": 1
},
{
"id": "646cd48f-d686-4d8a-a477-f892c2bfbf4d",
"name": "If succeed",
"type": "n8n-nodes-base.if",
"position": [
-736,
384
],
"parameters": {
"options": {},
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "7cb6c8ab-074b-4ccf-a1e1-cc0163c9090d",
"operator": {
"type": "string",
"operation": "exists",
"singleValue": true
},
"leftValue": "={{ $json.data }}",
"rightValue": ""
}
]
}
},
"typeVersion": 2.2
},
{
"id": "9c135f4b-a927-4ed0-97c0-7e634be06668",
"name": "Split audio file",
"type": "n8n-nodes-base.httpRequest",
"position": [
-512,
240
],
"parameters": {
"url": "={{ $('Configuration').item.json.fileflows_url }}/api/library-file/manually-add",
"method": "POST",
"options": {},
"jsonBody": "={\n \"FlowUid\": \"{{ $('Configuration').first().json.flowUid }}\",\n \"Files\": [\n \"{{ $json.data }}\"\n ],\n \"CustomVariables\": {\n \"callbackUrl\": \"{{$execution.resumeUrl}}\"\n }\n} ",
"sendBody": true,
"sendHeaders": true,
"specifyBody": "json",
"headerParameters": {
"parameters": [
{
"name": "accept",
"value": "*/*"
}
]
}
},
"typeVersion": 4.2
},
{
"id": "035b6116-13ae-4077-b74c-f1f0f6ee5909",
"name": "Wait",
"type": "n8n-nodes-base.wait",
"position": [
-288,
240
],
"webhookId": "56226497-16f8-4ef8-b2e3-731ea3cf1725",
"parameters": {
"resume": "webhook",
"options": {},
"httpMethod": "POST",
"resumeUnit": "minutes",
"resumeAmount": 30,
"limitWaitTime": true
},
"typeVersion": 1.1
},
{
"id": "fbfdf35a-f759-40c0-ace6-5b92ad89dc51",
"name": "Split Audio",
"type": "n8n-nodes-base.code",
"position": [
-64,
240
],
"parameters": {
"jsCode": "const binaries = $input.first().binary;\nconst entries = Object.entries(binaries);\n\nconst Audio = [];\nfor (let index = 0; index < entries.length; index++) {\n const [key, value] = entries[index];\n\n Audio.push({\n json: {\n fileExtension: value.fileExtension,\n fileName: value.fileName,\n fileSize: value.fileSize,\n fileType: value.fileType,\n mimeType: value.mimeType,\n },\n binary: {\n [\"Audio\"]: value, // Preserve the complete binary structure\n },\n });\n}\n\n// ⚠️ Important : send back array of items\nreturn Audio;"
},
"typeVersion": 2
},
{
"id": "138f793f-72eb-4d6b-a91e-56d26986a4ec",
"name": "Loop Over Segments",
"type": "n8n-nodes-base.splitInBatches",
"position": [
160,
240
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "2bfd6a91-ba2d-4be5-b728-5f0fb4138fea",
"name": "OpenAI",
"type": "@n8n/n8n-nodes-langchain.openAi",
"onError": "continueErrorOutput",
"position": [
608,
336
],
"parameters": {
"options": {
"language": "fr"
},
"resource": "audio",
"operation": "transcribe",
"binaryPropertyName": "Audio"
},
"credentials": {
"openAiApi": {
"id": "LpWtc4NmjHy1H15S",
"name": "OpenAI Account"
}
},
"retryOnFail": true,
"typeVersion": 1.8,
"waitBetweenTries": 5000
},
{
"id": "fb77ddde-81bb-4d33-ad6c-18feb4554337",
"name": "Result transcription",
"type": "n8n-nodes-base.noOp",
"position": [
384,
144
],
"parameters": {},
"typeVersion": 1
},
{
"id": "4e2d9d43-db6e-400e-b7c3-e6b9d30c28bd",
"name": "Loop Over Chunks",
"type": "n8n-nodes-base.splitInBatches",
"position": [
-1408,
624
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "3bdb454b-e54e-41da-a98d-5cf2c4049830",
"name": "Merge transcription",
"type": "n8n-nodes-base.code",
"position": [
608,
144
],
"parameters": {
"jsCode": "let res = \"\";\n// Loop over input items and add a new field called 'myNewField' to the JSON of each one\nfor (const item of $input.all()) {\n res += item.json.text;\n}\n\nreturn {\n transcription: res\n};"
},
"typeVersion": 2
},
{
"id": "587d7489-863d-459b-bbc6-c902f0745bae",
"name": "Convert to File",
"type": "n8n-nodes-base.convertToFile",
"position": [
832,
144
],
"parameters": {
"options": {
"encoding": "utf8",
"fileName": "transcription.txt"
},
"operation": "toText",
"sourceProperty": "transcription"
},
"typeVersion": 1.1
},
{
"id": "ce3854cc-d870-4a47-b931-676bdf3b2181",
"name": "Configuration",
"type": "n8n-nodes-base.set",
"position": [
-1856,
624
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "cfb1a46f-20fa-4a40-b52e-da8249cbd31b",
"name": "chunk_size",
"type": "number",
"value": "={{ 4 * 1024 * 1024 }}"
},
{
"id": "eff0f114-6e49-43ef-aae0-a078dd671833",
"name": "fileflows_url",
"type": "string",
"value": "http://172.19.0.2:5000"
},
{
"id": "dbbed56f-1ca8-4106-aed8-14f7d6009068",
"name": "flowUid",
"type": "string",
"value": "65fad732-0ac3-4f6d-ac10-2d31ef84c154"
}
]
},
"includeOtherFields": true
},
"typeVersion": 3.4
},
{
"id": "290bec95-3807-4d7f-abbc-affdeb54553e",
"name": "Filter temporary files",
"type": "n8n-nodes-base.filter",
"position": [
-960,
384
],
"parameters": {
"options": {},
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "46105005-e7f3-4fd9-9d2d-491a4bab372e",
"operator": {
"type": "string",
"operation": "notEndsWith"
},
"leftValue": "={{ $json.data }}",
"rightValue": ".temp"
}
]
}
},
"typeVersion": 2.2,
"alwaysOutputData": true
},
{
"id": "114c1df2-99b8-49bc-86c5-3404d27f6718",
"name": "Rate Limit Delay",
"type": "n8n-nodes-base.wait",
"position": [
832,
400
],
"webhookId": "46702252-568a-4066-8ed9-1e9e8753a596",
"parameters": {},
"typeVersion": 1.1
},
{
"id": "cfebb196-a52b-4594-8725-51236e0e4e22",
"name": "Send Email with Transcription",
"type": "n8n-nodes-base.gmail",
"position": [
1056,
144
],
"webhookId": "780625e1-7281-42bc-92d4-6fe224bd6a23",
"parameters": {
"sendTo": "={{ $('GET Form').first().json.email }}",
"message": "Hi,\n\nYour audio transcription is complete and attached to this email.\n\nBest regards",
"options": {
"attachmentsUi": {
"attachmentsBinary": [
{}
]
}
},
"subject": "Your transcription is ready"
},
"credentials": {
"gmailOAuth2": {
"id": "2",
"name": "Gmail account JDR perso"
}
},
"typeVersion": 2.1
},
{
"id": "9b1de36f-6b8f-4044-9fa2-6dd8c641a51b",
"name": "Send Error",
"type": "n8n-nodes-base.gmail",
"position": [
848,
608
],
"webhookId": "780625e1-7281-42bc-92d4-6fe224bd6a23",
"parameters": {
"sendTo": "={{ $('GET Form').first().json.email }}",
"message": "Hi,\n\nWe encountered an issue with the translation model.\nPlease retry in a moment.\n\nBest",
"options": {},
"subject": "Your transcription encountered an issue"
},
"credentials": {
"gmailOAuth2": {
"id": "2",
"name": "Gmail account JDR perso"
}
},
"typeVersion": 2.1
},
{
"id": "e1e89a89-165d-4aa1-b15a-d5aff0d0fc4d",
"name": "Send Error1",
"type": "n8n-nodes-base.gmail",
"position": [
-512,
480
],
"webhookId": "780625e1-7281-42bc-92d4-6fe224bd6a23",
"parameters": {
"sendTo": "={{ $('GET Form').first().json.email }}",
"message": "Hi,\n\nWe encountered an issue to split your file.\nPlease retry in a moment.\n\nBest",
"options": {},
"subject": "Your transcription encountered an issue"
},
"credentials": {
"gmailOAuth2": {
"id": "2",
"name": "Gmail account JDR perso"
}
},
"typeVersion": 2.1
},
{
"id": "55862df0-b4b5-4078-b90b-998c893710b9",
"name": "Chunk",
"type": "n8n-nodes-base.noOp",
"position": [
-1184,
576
],
"parameters": {},
"typeVersion": 1
},
{
"id": "d911c170-5767-49e7-8959-53cf809a7f4d",
"name": "Segment",
"type": "n8n-nodes-base.noOp",
"position": [
384,
336
],
"parameters": {},
"typeVersion": 1
},
{
"id": "2aee5e34-e10d-4149-9dfc-ea05a2d5b4a8",
"name": "Overview",
"type": "n8n-nodes-base.stickyNote",
"position": [
-2848,
-96
],
"parameters": {
"width": 676,
"height": 1128,
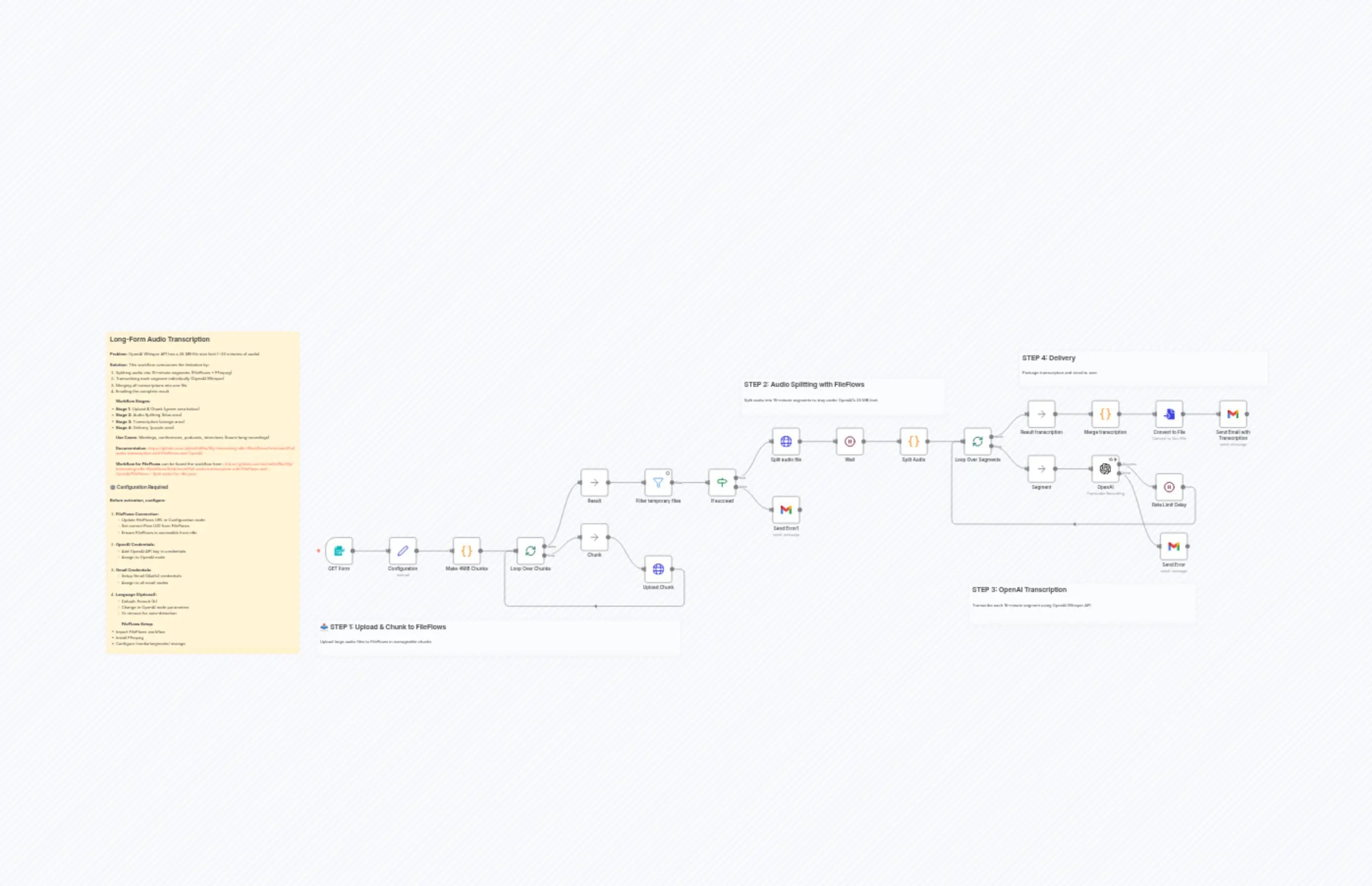
"content": "## Long-Form Audio Transcription\n\n**Problem:** OpenAI Whisper API has a 25 MB file size limit (~20 minutes of audio)\n\n**Solution:** This workflow overcomes the limitation by:\n1. Splitting audio into 15-minute segments (FileFlows + FFmpeg)\n2. Transcribing each segment individually (OpenAI Whisper)\n3. Merging all transcriptions into one file\n4. Emailing the complete result\n\n**Workflow Stages:**\n- **Stage 1:** Upload & Chunk (green area below)\n- **Stage 2:** Audio Splitting (blue area)\n- **Stage 3:** Transcription (orange area)\n- **Stage 4:** Delivery (purple area)\n\n**Use Cases:** Meetings, conferences, podcasts, interviews (hours-long recordings)\n\n**Documentation:** https://github.com/JulienDelRio/My-Interesting-n8n-Workflows/tree/main/Full%20audio%20transcription%20with%20FileFlows%20and%20OpenAI\n\n**Workflow for FileFlows** can be found the workflow here : https://github.com/JulienDelRio/My-Interesting-n8n-Workflows/blob/main/Full%20audio%20transcription%20with%20FileFlows%20and%20OpenAI/FileFlows%20-%20Split%20audio%20for%20n8n.json\n\n\n### ⚙️ Configuration Required\n\n**Before activation, configure:**\n\n1. **FileFlows Connection:**\n - Update FileFlows URL in Configuration node\n - Set correct Flow UID from FileFlows\n - Ensure FileFlows is accessible from n8n\n\n2. **OpenAI Credentials:**\n - Add OpenAI API key in credentials\n - Assign to OpenAI node\n\n3. **Gmail Credentials:**\n - Setup Gmail OAuth2 credentials\n - Assign to all email nodes\n\n4. **Language (Optional):**\n - Default: French (fr)\n - Change in OpenAI node parameters\n - Or remove for auto-detection\n\n**FileFlows Setup:**\n- Import FileFlows workflow\n- Install FFmpeg\n- Configure /media/segments/ storage"
},
"typeVersion": 1
},
{
"id": "d0b1f7d2-8819-4ec9-9d33-183051233741",
"name": "Stage 4 Delivery",
"type": "n8n-nodes-base.stickyNote",
"position": [
352,
-32
],
"parameters": {
"color": 7,
"width": 876,
"height": 132,
"content": "## STEP 4: Delivery\n\nPackage transcription and email to user"
},
"typeVersion": 1
},
{
"id": "cc22e417-d574-4098-b4f1-50c4690f3bfe",
"name": "Stage 3 Transcription",
"type": "n8n-nodes-base.stickyNote",
"position": [
176,
784
],
"parameters": {
"color": 7,
"width": 800,
"height": 152,
"content": "## STEP 3: OpenAI Transcription\n\nTranscribe each 15-minute segment using OpenAI Whisper API"
},
"typeVersion": 1
},
{
"id": "5441f26c-c5df-4464-b794-e45c3199ddb5",
"name": "Stage 2 Splitting",
"type": "n8n-nodes-base.stickyNote",
"position": [
-624,
64
],
"parameters": {
"color": 7,
"width": 720,
"height": 140,
"content": "## STEP 2: Audio Splitting with FileFlows\n\nSplit audio into 15-minute segments to stay under OpenAI's 25 MB limit."
},
"typeVersion": 1
},
{
"id": "a0c0ed38-3f9a-4237-9012-a24a03e05c3d",
"name": "Stage 1 Upload",
"type": "n8n-nodes-base.stickyNote",
"position": [
-2112,
912
],
"parameters": {
"color": 7,
"width": 1280,
"height": 134,
"content": "## 📤 STEP 1: Upload & Chunk to FileFlows\n\nUpload large audio files to FileFlows in manageable chunks"
},
"typeVersion": 1
}
],
"pinData": {},
"connections": {
"Wait": {
"main": [
[
{
"node": "Split Audio",
"type": "main",
"index": 0
}
]
]
},
"Chunk": {
"main": [
[
{
"node": "Upload Chunk",
"type": "main",
"index": 0
}
]
]
},
"OpenAI": {
"main": [
[
{
"node": "Rate Limit Delay",
"type": "main",
"index": 0
}
],
[
{
"node": "Send Error",
"type": "main",
"index": 0
}
]
]
},
"Result": {
"main": [
[
{
"node": "Filter temporary files",
"type": "main",
"index": 0
}
]
]
},
"Segment": {
"main": [
[
{
"node": "OpenAI",
"type": "main",
"index": 0
}
]
]
},
"GET Form": {
"main": [
[
{
"node": "Configuration",
"type": "main",
"index": 0
}
]
]
},
"If succeed": {
"main": [
[
{
"node": "Split audio file",
"type": "main",
"index": 0
}
],
[
{
"node": "Send Error1",
"type": "main",
"index": 0
}
]
]
},
"Split Audio": {
"main": [
[
{
"node": "Loop Over Segments",
"type": "main",
"index": 0
}
]
]
},
"Upload Chunk": {
"main": [
[
{
"node": "Loop Over Chunks",
"type": "main",
"index": 0
}
]
]
},
"Configuration": {
"main": [
[
{
"node": "Make 4MiB Chunks",
"type": "main",
"index": 0
}
]
]
},
"Convert to File": {
"main": [
[
{
"node": "Send Email with Transcription",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Chunks": {
"main": [
[
{
"node": "Result",
"type": "main",
"index": 0
}
],
[
{
"node": "Chunk",
"type": "main",
"index": 0
}
]
]
},
"Make 4MiB Chunks": {
"main": [
[
{
"node": "Loop Over Chunks",
"type": "main",
"index": 0
}
]
]
},
"Rate Limit Delay": {
"main": [
[
{
"node": "Loop Over Segments",
"type": "main",
"index": 0
}
]
]
},
"Split audio file": {
"main": [
[
{
"node": "Wait",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Segments": {
"main": [
[
{
"node": "Result transcription",
"type": "main",
"index": 0
}
],
[
{
"node": "Segment",
"type": "main",
"index": 0
}
]
]
},
"Merge transcription": {
"main": [
[
{
"node": "Convert to File",
"type": "main",
"index": 0
}
]
]
},
"Result transcription": {
"main": [
[
{
"node": "Merge transcription",
"type": "main",
"index": 0
}
]
]
},
"Filter temporary files": {
"main": [
[
{
"node": "If succeed",
"type": "main",
"index": 0
}
]
]
}
}
}