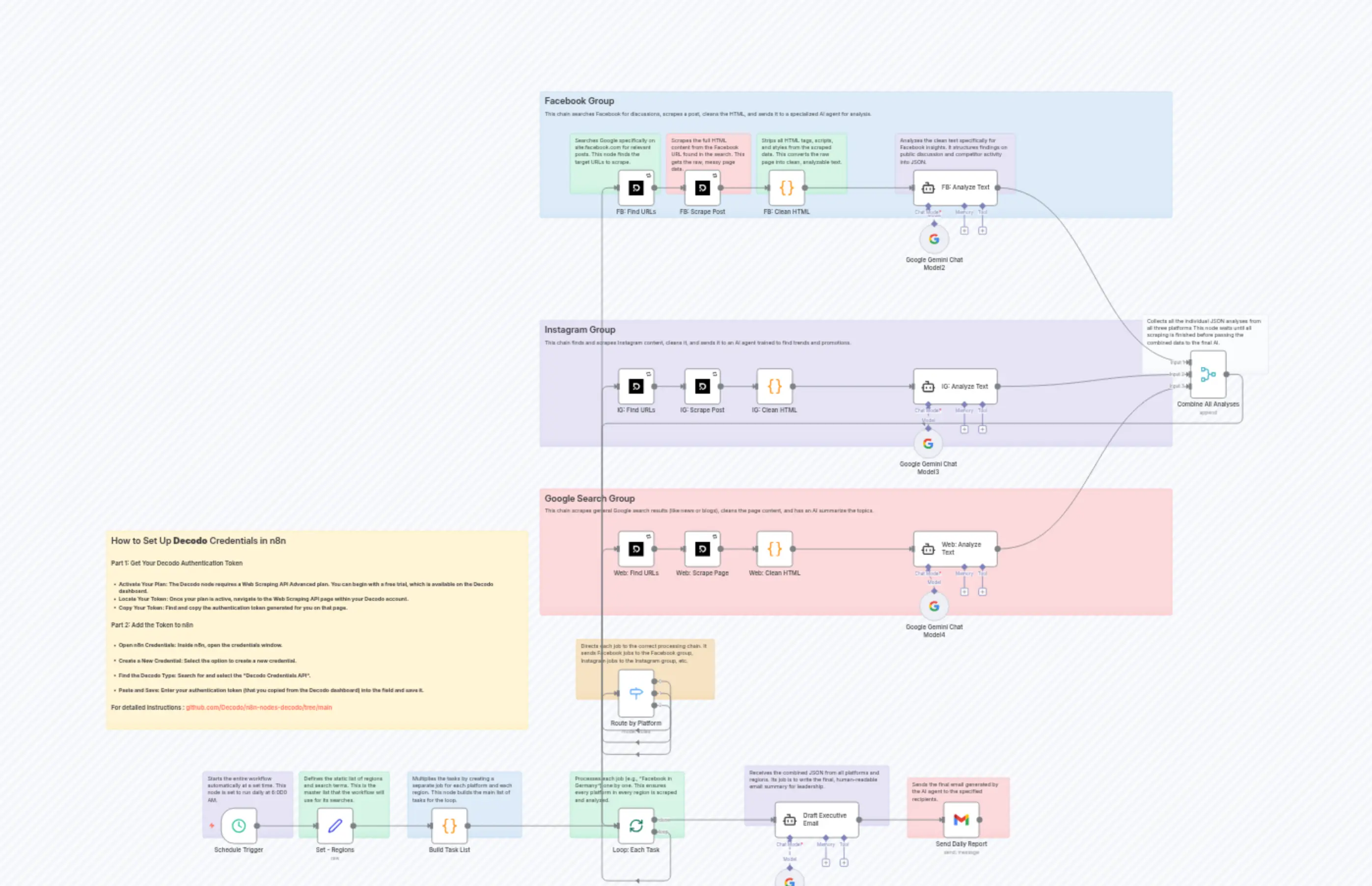
Decodo Market Research (Template)
描述
分类
📢 Marketing🤖 AI & Machine Learning
使用的节点
n8n-nodes-base.setn8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.gmailn8n-nodes-base.mergen8n-nodes-base.switchn8n-nodes-base.stickyNoten8n-nodes-base.stickyNote
价格免费
浏览量1
最后更新1/30/2026
workflow.json
{
"id": "DWKUmotZA33TXbT1",
"meta": {
"instanceId": "7f1a0694161455be3a7e71f1e0dea04908b0376a1a81e3a0c1e5ac879d48f83a"
},
"name": "Decodo Market Research (Template)",
"tags": [],
"nodes": [
{
"id": "9d7734c1-1b15-45d8-bf24-df2d1270534a",
"name": "Set - Regions",
"type": "n8n-nodes-base.set",
"notes": "Holds the array of regions you need to scrape.",
"position": [
-944,
2480
],
"parameters": {
"mode": "raw",
"options": {},
"jsonOutput": "{\n \"topic\": \"[YOUR_TOPIC_HERE]\",\n \"regions\": [\n\"[Region_1]\", \"[Region_2]\", \"[Region_3]\"\n ],\n \"search_terms\": [\"[Search_Term_1]\", \"[Search_Term_2]\", \"[Search_Term_3]\"]\n}\n\n\n"
},
"typeVersion": 3.4
},
{
"id": "362c4b5d-e718-47b0-8f70-bccb3848de8a",
"name": "Google Gemini Chat Model",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
272,
2640
],
"parameters": {
"options": {}
},
"typeVersion": 1
},
{
"id": "e0967a0d-5698-471c-8a40-a41807fe5a25",
"name": "Google Gemini Chat Model2",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
656,
928
],
"parameters": {
"options": {}
},
"typeVersion": 1
},
{
"id": "3dc08800-6a8c-4655-bb24-caacb8347ca1",
"name": "Google Gemini Chat Model3",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
640,
1472
],
"parameters": {
"options": {}
},
"typeVersion": 1
},
{
"id": "c1867d93-ce94-431b-88bc-a27e20c5ca2b",
"name": "Google Gemini Chat Model4",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
656,
1904
],
"parameters": {
"options": {}
},
"typeVersion": 1
},
{
"id": "6aa23982-da46-46fc-8f49-3da58932e83c",
"name": "Schedule Trigger",
"type": "n8n-nodes-base.scheduleTrigger",
"position": [
-1200,
2480
],
"parameters": {
"rule": {
"interval": [
{
"triggerAtHour": 6
}
]
}
},
"typeVersion": 1.2
},
{
"id": "b90db4b0-2bff-4db8-8708-462a39447d0d",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-352,
576
],
"parameters": {
"color": 5,
"width": 1680,
"height": 336,
"content": "## Facebook Group\nThis chain searches Facebook for discussions, scrapes a post, cleans the HTML, and sends it to a specialized AI agent for analysis."
},
"typeVersion": 1
},
{
"id": "69bf4b8d-69b9-459b-9b49-bff2bbb4ac76",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-272,
688
],
"parameters": {
"color": 4,
"content": "Searches Google specifically on site:facebook.com for relevant posts. This node finds the target URLs to scrape."
},
"typeVersion": 1
},
{
"id": "843cb9b4-2b45-418d-b184-afe84a182912",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
-16,
688
],
"parameters": {
"color": 3,
"width": 224,
"content": "Scrapes the full HTML content from the Facebook URL found in the search. This gets the raw, messy page data."
},
"typeVersion": 1
},
{
"id": "5cee9e3d-b600-4566-a12e-b0b4214aa614",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
224,
688
],
"parameters": {
"color": 4,
"content": "Strips all HTML tags, scripts, and styles from the scraped data. This converts the raw page into clean, analyzable text."
},
"typeVersion": 1
},
{
"id": "e1aac060-7709-4ac7-b88f-8d87f2129ec0",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
592,
688
],
"parameters": {
"color": 6,
"width": 320,
"content": "Analyzes the clean text specifically for Facebook insights. It structures findings on public discussion and competitor activity into JSON."
},
"typeVersion": 1
},
{
"id": "e98e8d88-3665-49ad-b780-5808d221977b",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
-352,
1184
],
"parameters": {
"color": 6,
"width": 1680,
"height": 336,
"content": "## Instagram Group\nThis chain finds and scrapes Instagram content, cleans it, and sends it to an AI agent trained to find trends and promotions."
},
"typeVersion": 1
},
{
"id": "8f8a81ae-879a-40a8-9004-5e8ac1099532",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
-352,
1632
],
"parameters": {
"color": 3,
"width": 1680,
"height": 336,
"content": "## Google Search Group\nThis chain scrapes general Google search results (like news or blogs), cleans the page content, and has an AI summarize the topics."
},
"typeVersion": 1
},
{
"id": "c96a9838-0061-43f9-980a-4bfd223e2c82",
"name": "Sticky Note7",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1248,
2384
],
"parameters": {
"color": 6,
"height": 176,
"content": "Starts the entire workflow automatically at a set time. This node is set to run daily at 6:0D0 AM."
},
"typeVersion": 1
},
{
"id": "3fd439ca-945a-479a-b169-4c774be84bc4",
"name": "Sticky Note8",
"type": "n8n-nodes-base.stickyNote",
"position": [
-992,
2384
],
"parameters": {
"color": 4,
"height": 176,
"content": "Defines the static list of regions and search terms. This is the master list that the workflow will use for its searches."
},
"typeVersion": 1
},
{
"id": "086537b6-16dd-4f57-9110-5afe7fc90238",
"name": "Sticky Note9",
"type": "n8n-nodes-base.stickyNote",
"position": [
-704,
2384
],
"parameters": {
"color": 5,
"width": 304,
"height": 176,
"content": "Multiplies the tasks by creating a separate job for each platform and each region. This node builds the main list of tasks for the loop."
},
"typeVersion": 1
},
{
"id": "32b2d7c2-963d-43c3-a287-6e1c9abeac25",
"name": "Sticky Note10",
"type": "n8n-nodes-base.stickyNote",
"position": [
-272,
2384
],
"parameters": {
"color": 4,
"width": 304,
"height": 176,
"content": "Processes each job (e.g., \"Facebook in Germany\") one by one. This ensures every platform in every region is scraped and analyzed."
},
"typeVersion": 1
},
{
"id": "95f6448f-4142-4a21-8128-8a37d651e665",
"name": "Sticky Note11",
"type": "n8n-nodes-base.stickyNote",
"position": [
-256,
2032
],
"parameters": {
"color": 2,
"width": 368,
"content": "Directs each job to the correct processing chain. It sends Facebook jobs to the Facebook group, Instagram jobs to the Instagram group, etc."
},
"typeVersion": 1
},
{
"id": "02e9c014-5478-486f-b65f-446f0001c88a",
"name": "Sticky Note12",
"type": "n8n-nodes-base.stickyNote",
"position": [
1248,
1168
],
"parameters": {
"color": 7,
"width": 336,
"content": "Collects all the individual JSON analyses from all three platforms This node waits until all scraping is finished before passing the combined data to the final AI."
},
"typeVersion": 1
},
{
"id": "b3fecce5-4146-4a4b-8e12-b8ecce2886c3",
"name": "Sticky Note13",
"type": "n8n-nodes-base.stickyNote",
"position": [
192,
2368
],
"parameters": {
"color": 6,
"width": 384,
"content": "Receives the combined JSON from all platforms and regions. Its job is to write the final, human-readable email summary for leadership."
},
"typeVersion": 1
},
{
"id": "3e2f3576-3dfc-4a03-9f76-70f943ecb125",
"name": "Sticky Note14",
"type": "n8n-nodes-base.stickyNote",
"position": [
624,
2400
],
"parameters": {
"color": 3,
"width": 272,
"content": "Sends the final email generated by the AI agent to the specified recipients."
},
"typeVersion": 1
},
{
"id": "6832bdde-2cad-42d6-9eab-ebee8007f883",
"name": "Sticky Note15",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1504,
1744
],
"parameters": {
"width": 1120,
"height": 528,
"content": "## How to Set Up **Decodo** Credentials in n8n\n\n### Part 1: Get Your Decodo Authentication Token\n\n* **Activate Your Plan: The Decodo node requires a Web Scraping API Advanced plan. You can begin with a free trial, which is available on the Decodo dashboard.**\n* **Locate Your Token: Once your plan is active, navigate to the Web Scraping API page within your Decodo account.**\n* **Copy Your Token: Find and copy the authentication token generated for you on that page.**\n\n### Part 2: Add the Token to n8n\n\n* **Open n8n Credentials: Inside n8n, open the credentials window.**\n\n* **Create a New Credential: Select the option to create a new credential.**\n\n* **Find the Decodo Type: Search for and select the \"Decodo Credentials API\".**\n\n* **Paste and Save: Enter your authentication token (that you copied from the Decodo dashboard) into the field and save it.**\n\n\n### For detailed instructions : github.com/Decodo/n8n-nodes-decodo/tree/main"
},
"typeVersion": 1
},
{
"id": "71adeb60-e316-458f-afbe-bb5b9b9439f9",
"name": "Build Task List",
"type": "n8n-nodes-base.code",
"position": [
-640,
2480
],
"parameters": {
"jsCode": "// Input from Set node\nconst { topic, regions, search_terms } = $json;\n\n// EDIT: Add or remove platforms as needed\nconst platforms = [\"facebook.com\", \"instagram.com\", \"google.com\"];\n\n// Calculate a date 1 month ago for freshness filtering\nconst date = new Date();\ndate.setMonth(date.getMonth() - 1);\nconst afterDate = date.toISOString().split(\"T\")[0]; // e.g. \"2025-10-09\"\n\n// Build output: one record per region × platform\nconst results = [];\n\nregions.forEach(region => {\n platforms.forEach(platform => {\n results.push({\n json: {\n topic,\n region,\n platform,\n search_terms,\n afterDate,\n query: `${topic} ${platform} promotions after:${afterDate}`\n }\n });\n });\n});\n\nreturn results;\n"
},
"typeVersion": 2
},
{
"id": "bdd44f51-0524-469b-8beb-9da5f482a939",
"name": "Loop: Each Task",
"type": "n8n-nodes-base.splitInBatches",
"position": [
-144,
2480
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "bf189102-99a4-403f-a7f9-7143d4fc4551",
"name": "Route by Platform",
"type": "n8n-nodes-base.switch",
"position": [
-144,
2112
],
"parameters": {
"rules": {
"values": [
{
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "b59b2ece-9d8a-4258-a143-f36a313b2370",
"operator": {
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $json.platform }}",
"rightValue": "facebook.com"
}
]
}
},
{
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "4494e5a2-0064-445b-9b74-6f7de2efb5fc",
"operator": {
"name": "filter.operator.equals",
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $json.platform }}",
"rightValue": "instagram.com"
}
]
}
},
{
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "b7e3a699-72e0-4934-b1f6-2005ead20a33",
"operator": {
"name": "filter.operator.equals",
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $json.platform }}",
"rightValue": "google.com"
}
]
}
}
]
},
"options": {}
},
"typeVersion": 3.3
},
{
"id": "4d230962-ec86-4bcd-aa0d-65b717719138",
"name": "FB: Find URLs",
"type": "@decodo/n8n-nodes-decodo.decodo",
"position": [
-144,
784
],
"parameters": {
"geo": "={{ $('Loop: Each Task').item.json.region }}",
"query": "=[YOUR_SEARCH_QUERY_HERE] site:facebook.com after:{{ $('Loop: Each Task').item.json.afterDate }}",
"operation": "google_search"
},
"credentials": {
"decodoApi": {
"id": "9HI1GSmz6KVEMRzA",
"name": "Decodo Credentials account"
}
},
"retryOnFail": true,
"typeVersion": 1
},
{
"id": "2059d5ba-55d6-4438-8798-4ae22304e0ba",
"name": "FB: Scrape Post",
"type": "@decodo/n8n-nodes-decodo.decodo",
"position": [
32,
784
],
"parameters": {
"url": "={{ $json.results[0].content.results.results.organic[0].url }}"
},
"credentials": {
"decodoApi": {
"id": "9HI1GSmz6KVEMRzA",
"name": "Decodo Credentials account"
}
},
"retryOnFail": true,
"typeVersion": 1
},
{
"id": "a307357a-b5dd-4104-a769-6c41de823e50",
"name": "FB: Clean HTML",
"type": "n8n-nodes-base.code",
"position": [
256,
784
],
"parameters": {
"jsCode": "// get the raw HTML string from your previous node\nconst html = $json.results?.[0]?.content || $json.body || \"\";\n\n// --- BASIC CLEANUP ---\n\n// remove <script>, <style>, <noscript>, and their contents\nlet cleaned = html.replace(/<script[^>]*>[\\s\\S]*?<\\/script>/gi, \"\")\n .replace(/<style[^>]*>[\\s\\S]*?<\\/style>/gi, \"\")\n .replace(/<noscript[^>]*>[\\s\\S]*?<\\/noscript>/gi, \"\");\n\n// remove all HTML tags\ncleaned = cleaned.replace(/<\\/?[^>]+(>|$)/g, \" \");\n\n// decode HTML entities like &, "\ncleaned = cleaned.replace(/ /gi, \" \")\n .replace(/&/gi, \"&\")\n .replace(/"/gi, '\"')\n .replace(/'/gi, \"'\")\n .replace(/</gi, \"<\")\n .replace(/>/gi, \">\");\n\n// collapse whitespace and line breaks\ncleaned = cleaned.replace(/\\s+/g, \" \").trim();\n\n// optional: cut super-long strings (>10k chars)\nif (cleaned.length > 10000) cleaned = cleaned.slice(0, 10000) + \" … [truncated]\";\n\n// return it\nreturn [{ json: { text_clean: cleaned } }];\n"
},
"typeVersion": 2
},
{
"id": "14c9d216-5294-46a3-b549-99ffa117bedb",
"name": "FB: Analyze Text",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
640,
784
],
"parameters": {
"text": "=You are a marketing-intelligence analyst specializing in social listening.\n\nAnalyze the following Facebook data related to [YOUR_TOPIC] markets. The content may include public posts, comments, page updates, or ads across multiple regions.\n\nGoals:\n• Identify what people are talking about: opinions, experiences, recurring sentiments.\n• Detect any competitor activity: campaigns, discounts, launches, or brand mentions.\n• Note which region each insight belongs to.\n\nOutput a structured analytical summary formatted as JSON:\n\n{\n \"platform\": \"Facebook\",\n \"regions\": [\n {\n \"region\": \"\",\n \"public_discussion\": \"\",\n \"sentiment\": \"\",\n \"competitor_activity\": \"\",\n \"notable_trends\": \"\"\n }\n ],\n \"key_takeaways\": \"\"\n}\n\nGuidelines:\n- Include every region you can detect; do not assume a fixed list.\n- Stay analytical and concise.\n- Focus only on content from the past month.\n- Return valid JSON only.\n\n\ncontent to be processed : {{ $json.text_clean }}",
"options": {},
"promptType": "define"
},
"typeVersion": 3
},
{
"id": "a4a3356e-54c3-4663-aa35-9d1a4c76633f",
"name": "IG: Find URLs",
"type": "@decodo/n8n-nodes-decodo.decodo",
"position": [
-144,
1312
],
"parameters": {
"geo": "={{ $('Loop: Each Task').item.json.region }}",
"query": "=[YOUR_SEARCH_QUERY_HERE] site:instagram.com after:{{ $('Loop: Each Task').item.json.afterDate }}",
"operation": "google_search"
},
"credentials": {
"decodoApi": {
"id": "9HI1GSmz6KVEMRzA",
"name": "Decodo Credentials account"
}
},
"retryOnFail": true,
"typeVersion": 1
},
{
"id": "7fc000e4-0320-4802-80f7-0c6b6dff371d",
"name": "IG: Scrape Post",
"type": "@decodo/n8n-nodes-decodo.decodo",
"position": [
32,
1312
],
"parameters": {
"url": "={{ $json.results[0].content.results.results.organic[0].url }}"
},
"credentials": {
"decodoApi": {
"id": "9HI1GSmz6KVEMRzA",
"name": "Decodo Credentials account"
}
},
"retryOnFail": true,
"typeVersion": 1
},
{
"id": "6e6c15af-b04e-466b-90e8-6ff56f3ef6c1",
"name": "IG: Clean HTML",
"type": "n8n-nodes-base.code",
"position": [
224,
1312
],
"parameters": {
"jsCode": "// get the raw HTML string from your previous node\nconst html = $json.results?.[0]?.content || $json.body || \"\";\n\n// --- BASIC CLEANUP ---\n\n// remove <script>, <style>, <noscript>, and their contents\nlet cleaned = html.replace(/<script[^>]*>[\\s\\S]*?<\\/script>/gi, \"\")\n .replace(/<style[^>]*>[\\s\\S]*?<\\/style>/gi, \"\")\n .replace(/<noscript[^>]*>[\\s\\S]*?<\\/noscript>/gi, \"\");\n\n// remove all HTML tags\ncleaned = cleaned.replace(/<\\/?[^>]+(>|$)/g, \" \");\n\n// decode HTML entities like &, "\ncleaned = cleaned.replace(/ /gi, \" \")\n .replace(/&/gi, \"&\")\n .replace(/"/gi, '\"')\n .replace(/'/gi, \"'\")\n .replace(/</gi, \"<\")\n .replace(/>/gi, \">\");\n\n// collapse whitespace and line breaks\ncleaned = cleaned.replace(/\\s+/g, \" \").trim();\n\n// optional: cut super-long strings (>10k chars)\nif (cleaned.length > 10000) cleaned = cleaned.slice(0, 10000) + \" … [truncated]\";\n\n// return it\nreturn [{ json: { text_clean: cleaned } }];\n"
},
"typeVersion": 2
},
{
"id": "b00d1a01-4c9a-414f-bc44-c38a25558288",
"name": "IG: Analyze Text",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
640,
1312
],
"parameters": {
"text": "=You are a digital-marketing trend analyst reviewing Instagram data about [YOUR_TOPIC].\n\nThe text may come from captions, hashtags, or influencer posts from different countries.\n\nTasks:\n• Identify what people are saying about [YOUR_TOPIC] products, lifestyles, and routines.\n• Capture tone and sentiment (enthusiasm, skepticism, curiosity, etc.).\n• Detect competitor promotions or influencer collaborations.\n• Assign each insight to its correct region if possible.\n\nOutput JSON:\n\n{\n \"platform\": \"Instagram\",\n \"regions\": [\n {\n \"region\": \"\",\n \"audience_opinion\": \"\",\n \"sentiment\": \"\",\n \"competitor_promotions\": \"\",\n \"visual_or_trend_notes\": \"\"\n }\n ],\n \"key_takeaways\": \"\"\n}\n\nRules:\n- Make the “regions” array dynamic based on detected locations.\n- Keep summaries factual and strategic.\n- Limit scope to recent (≈30 days) observations.\n- Return pure JSON without commentary.\n\n\ncontent to be processed: {{ $json.text_clean }}",
"options": {},
"promptType": "define"
},
"typeVersion": 3
},
{
"id": "2199813d-3019-47f4-b25e-14b87d192458",
"name": "Web: Find URLs",
"type": "@decodo/n8n-nodes-decodo.decodo",
"position": [
-144,
1744
],
"parameters": {
"geo": "={{ $('Loop: Each Task').item.json.region }}",
"query": "=[YOUR_SEARCH_QUERY_HERE] after:{{ $('Loop: Each Task').item.json.afterDate }}",
"operation": "google_search"
},
"credentials": {
"decodoApi": {
"id": "9HI1GSmz6KVEMRzA",
"name": "Decodo Credentials account"
}
},
"retryOnFail": true,
"typeVersion": 1
},
{
"id": "f31f5f97-e56a-4cd6-b407-f7adda1bbb59",
"name": "Web: Scrape Page",
"type": "@decodo/n8n-nodes-decodo.decodo",
"position": [
32,
1744
],
"parameters": {
"url": "={{ $json.results[0].content.results.results.organic[0].url }}"
},
"credentials": {
"decodoApi": {
"id": "9HI1GSmz6KVEMRzA",
"name": "Decodo Credentials account"
}
},
"retryOnFail": true,
"typeVersion": 1
},
{
"id": "e7227f25-30c1-4391-be3f-67d8aea7066d",
"name": "Web: Clean HTML",
"type": "n8n-nodes-base.code",
"position": [
224,
1744
],
"parameters": {
"jsCode": "// get the raw HTML string from your previous node\nconst html = $json.results?.[0]?.content || $json.body || \"\";\n\n// --- BASIC CLEANUP ---\n\n// remove <script>, <style>, <noscript>, and their contents\nlet cleaned = html.replace(/<script[^>]*>[\\s\\S]*?<\\/script>/gi, \"\")\n .replace(/<style[^>]*>[\\s\\S]*?<\\/style>/gi, \"\")\n .replace(/<noscript[^>]*>[\\s\\S]*?<\\/noscript>/gi, \"\");\n\n// remove all HTML tags\ncleaned = cleaned.replace(/<\\/?[^>]+(>|$)/g, \" \");\n\n// decode HTML entities like &, "\ncleaned = cleaned.replace(/ /gi, \" \")\n .replace(/&/gi, \"&\")\n .replace(/"/gi, '\"')\n .replace(/'/gi, \"'\")\n .replace(/</gi, \"<\")\n .replace(/>/gi, \">\");\n\n// collapse whitespace and line breaks\ncleaned = cleaned.replace(/\\s+/g, \" \").trim();\n\n// optional: cut super-long strings (>10k chars)\nif (cleaned.length > 10000) cleaned = cleaned.slice(0, 10000) + \" … [truncated]\";\n\n// return it\nreturn [{ json: { text_clean: cleaned } }];\n"
},
"typeVersion": 2
},
{
"id": "c7e48ecd-4854-40c0-9c0e-98a19811f295",
"name": "Web: Analyze Text",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
640,
1744
],
"parameters": {
"text": "=You are a competitive-intelligence model summarizing insights from Google Search results related to the [YOUR_TOPIC] industry.\n\nInput text includes snippets from articles, reviews, and promotional pages indexed across multiple regions.\n\nTasks:\n• Summarize what topics or concerns dominate public and media attention.\n• Identify visible competitor promotions or new product announcements.\n• Note SEO or advertising trends.\n• Detect and label each insight by region.\n\nReturn JSON structured as:\n\n{\n \"platform\": \"Google Search\",\n \"regions\": [\n {\n \"region\": \"\",\n \"media_topics\": \"\",\n \"public_interest\": \"\",\n \"competitor_campaigns\": \"\",\n \"marketing_patterns\": \"\"\n }\n ],\n \"key_takeaways\": \"\"\n}\n\nGuidelines:\n- Dynamically include any region found.\n- Keep language formal and insight-driven.\n- Only include fresh or recently indexed material.\n\n\ncontent to be processed: {{ $json.text_clean }}",
"options": {},
"promptType": "define"
},
"typeVersion": 3
},
{
"id": "fd5d4e76-f995-420e-9baa-6efe7dce8e13",
"name": "Combine All Analyses",
"type": "n8n-nodes-base.merge",
"position": [
1376,
1264
],
"parameters": {
"numberInputs": 3
},
"typeVersion": 3.2
},
{
"id": "e6f960f9-98c5-4fc5-accc-e7acb9b24d68",
"name": "Draft Executive Email",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
272,
2464
],
"parameters": {
"text": "=You are an AI communication specialist preparing a professional daily intelligence email\nfor the leadership team of a [YOUR_COMPANY_TOPIC] company.\n\nInput: structured summaries from multiple platforms (Facebook, Instagram, Google Search, etc.),\neach containing multiple regions.\n\nYour job:\n• Combine all information into a clear, executive-ready email.\n• Dynamically include every region and every platform present in the input.\n• Categorize insights under two major sections:\n 1. People's Opinions\n 2. Competitors & Promotions\n\nFormatting instructions (plain text output, no markdown):\n\nBody:\n\n1️⃣ People's Opinions\n - For each region, group findings by platform:\n Region: <region name>\n • Facebook: summarize opinions, tone, notable public themes.\n • Instagram: summarize audience sentiment and visual trends.\n • Google Search: summarize media/public focus and sentiment.\n (Include all regions dynamically.)\n\n2️⃣ Competitors & Promotions\n - For each region, group by platform:\n Region: <region name>\n • Facebook: competitor names, promo types, campaign tone.\n • Instagram: influencer collabs, giveaway or discount trends.\n • Google Search: visible ad or content marketing initiatives.\n\nEnd with:\n• “Global Takeaway” – two short sentences summarizing overall consumer sentiment and competitive activity across all regions and platforms.\n\nTone: professional, analytical, and concise.\nDo not include regions or platforms that have no data.\nOutput must be fully written email text, ready to send.\n\ncontent to be processed: {{ $json.output }}",
"options": {},
"promptType": "define"
},
"typeVersion": 3
},
{
"id": "a9131ab5-1159-4db0-b520-2ddec51bd568",
"name": "Send Daily Report",
"type": "n8n-nodes-base.gmail",
"position": [
720,
2464
],
"webhookId": "a20e616a-96ff-4a1d-a813-7e2804a59d13",
"parameters": {
"sendTo": "=[[email protected]]",
"message": "={{ $json.output }}",
"options": {},
"subject": "=Daily Global [YOUR_TOPIC] Market Insights "
},
"credentials": {
"gmailOAuth2": {
"id": "OVQrwg5oLZomwQcs",
"name": "Gmail account"
}
},
"typeVersion": 2.1
}
],
"active": false,
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"versionId": "3fcb9873-bfd7-485e-8a18-6e80f3eeb1aa",
"connections": {
"FB: Find URLs": {
"main": [
[
{
"node": "FB: Scrape Post",
"type": "main",
"index": 0
}
]
]
},
"IG: Find URLs": {
"main": [
[
{
"node": "IG: Scrape Post",
"type": "main",
"index": 0
}
]
]
},
"Set - Regions": {
"main": [
[
{
"node": "Build Task List",
"type": "main",
"index": 0
}
]
]
},
"FB: Clean HTML": {
"main": [
[
{
"node": "FB: Analyze Text",
"type": "main",
"index": 0
}
]
]
},
"IG: Clean HTML": {
"main": [
[
{
"node": "IG: Analyze Text",
"type": "main",
"index": 0
}
]
]
},
"Web: Find URLs": {
"main": [
[
{
"node": "Web: Scrape Page",
"type": "main",
"index": 0
}
]
]
},
"Build Task List": {
"main": [
[
{
"node": "Loop: Each Task",
"type": "main",
"index": 0
}
]
]
},
"FB: Scrape Post": {
"main": [
[
{
"node": "FB: Clean HTML",
"type": "main",
"index": 0
}
]
]
},
"IG: Scrape Post": {
"main": [
[
{
"node": "IG: Clean HTML",
"type": "main",
"index": 0
}
]
]
},
"Loop: Each Task": {
"main": [
[
{
"node": "Draft Executive Email",
"type": "main",
"index": 0
}
],
[
{
"node": "Route by Platform",
"type": "main",
"index": 0
}
]
]
},
"Web: Clean HTML": {
"main": [
[
{
"node": "Web: Analyze Text",
"type": "main",
"index": 0
}
]
]
},
"FB: Analyze Text": {
"main": [
[
{
"node": "Combine All Analyses",
"type": "main",
"index": 0
}
]
]
},
"IG: Analyze Text": {
"main": [
[
{
"node": "Combine All Analyses",
"type": "main",
"index": 1
}
]
]
},
"Schedule Trigger": {
"main": [
[
{
"node": "Set - Regions",
"type": "main",
"index": 0
}
]
]
},
"Web: Scrape Page": {
"main": [
[
{
"node": "Web: Clean HTML",
"type": "main",
"index": 0
}
]
]
},
"Route by Platform": {
"main": [
[
{
"node": "FB: Find URLs",
"type": "main",
"index": 0
}
],
[
{
"node": "IG: Find URLs",
"type": "main",
"index": 0
}
],
[
{
"node": "Web: Find URLs",
"type": "main",
"index": 0
}
]
]
},
"Web: Analyze Text": {
"main": [
[
{
"node": "Combine All Analyses",
"type": "main",
"index": 2
}
]
]
},
"Combine All Analyses": {
"main": [
[
{
"node": "Loop: Each Task",
"type": "main",
"index": 0
}
]
]
},
"Draft Executive Email": {
"main": [
[
{
"node": "Send Daily Report",
"type": "main",
"index": 0
}
]
]
},
"Google Gemini Chat Model": {
"ai_languageModel": [
[
{
"node": "Draft Executive Email",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Google Gemini Chat Model2": {
"ai_languageModel": [
[
{
"node": "FB: Analyze Text",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Google Gemini Chat Model3": {
"ai_languageModel": [
[
{
"node": "IG: Analyze Text",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Google Gemini Chat Model4": {
"ai_languageModel": [
[
{
"node": "Web: Analyze Text",
"type": "ai_languageModel",
"index": 0
}
]
]
}
}
}