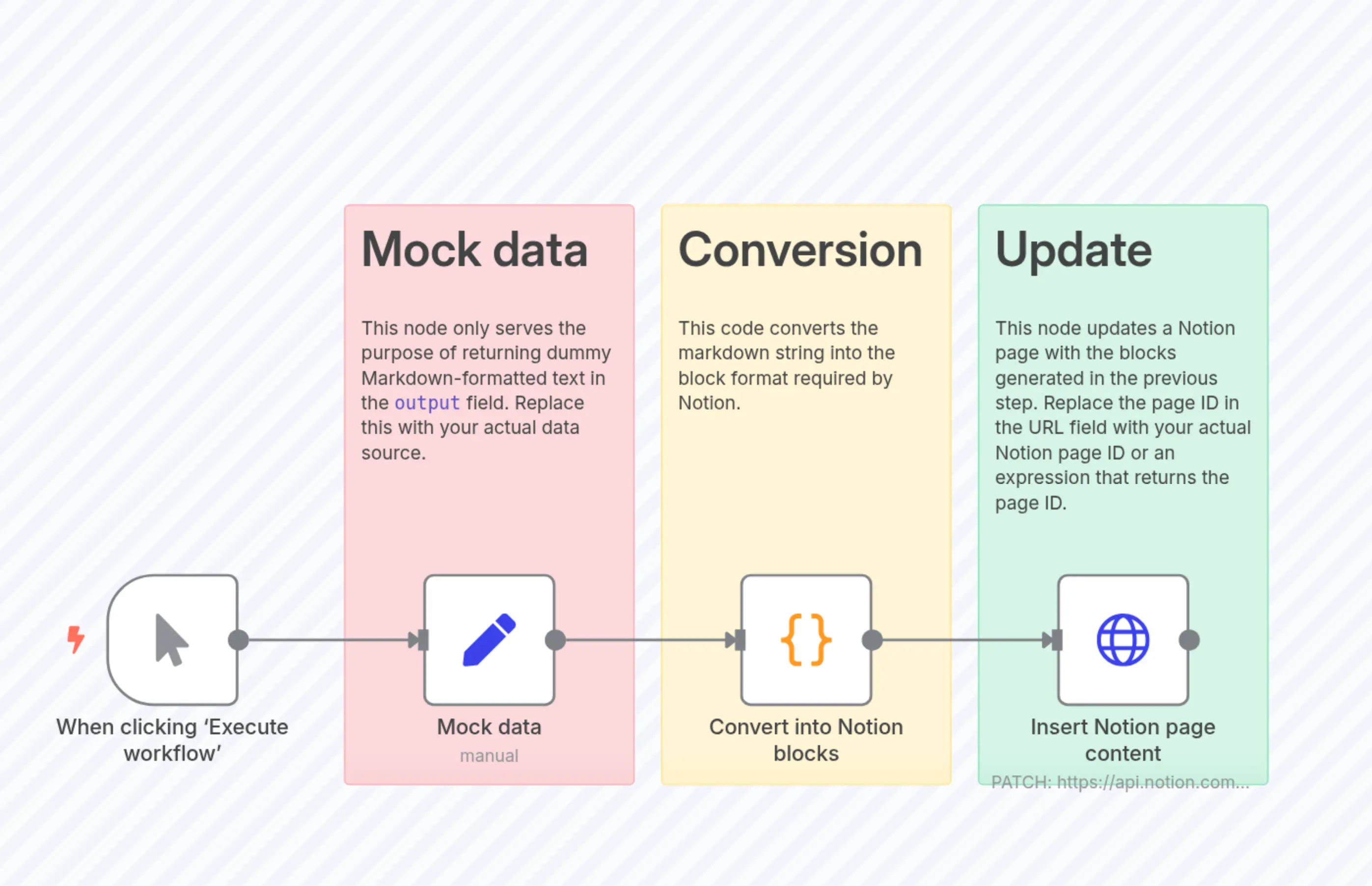
Transform Markdown Content into Structured Notion Blocks
説明
Categories
⚙️ Automation
Nodes Used
n8n-nodes-base.setn8n-nodes-base.coden8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.httpRequestn8n-nodes-base.manualTrigger
Price無料
Views0
最終更新11/28/2025
workflow.json
{
"meta": {
"instanceId": "cb484ba7b742928a2048bf8829668bed5b5ad9787579adea888f05980292a4a7"
},
"nodes": [
{
"id": "007b49ed-a264-4beb-92a9-917c0550c665",
"name": "Convert into Notion blocks",
"type": "n8n-nodes-base.code",
"position": [
220,
0
],
"parameters": {
"jsCode": "// Get the output string and page_id from the previous node\nconst outputText = $input.item.json.output;\nconst pageId = $input.item.json.page_id; // Add this if you have the page ID in your data\n\n// Function to convert text to Notion blocks\nfunction textToNotionBlocks(text) {\n if (!text || typeof text !== 'string') {\n return [];\n }\n\n const blocks = [];\n const lines = text.split('\\n');\n let inCodeBlock = false;\n let codeBlockContent = [];\n let codeBlockLanguage = '';\n \n for (let i = 0; i < lines.length; i++) {\n const line = lines[i];\n const trimmedLine = line.trim();\n \n // Handle code blocks\n if (trimmedLine.startsWith('```')) {\n if (!inCodeBlock) {\n // Starting a code block\n inCodeBlock = true;\n codeBlockLanguage = trimmedLine.substring(3).trim();\n codeBlockContent = [];\n } else {\n // Ending a code block\n inCodeBlock = false;\n blocks.push({\n object: 'block',\n type: 'code',\n code: {\n caption: [],\n rich_text: [{\n type: 'text',\n text: { content: codeBlockContent.join('\\n') }\n }],\n language: codeBlockLanguage || 'plain text'\n }\n });\n codeBlockContent = [];\n codeBlockLanguage = '';\n }\n continue;\n }\n \n // If we're inside a code block, collect the content\n if (inCodeBlock) {\n codeBlockContent.push(line);\n continue;\n }\n \n // Skip empty lines\n if (!trimmedLine) {\n continue;\n }\n \n // Check for horizontal rules\n if (trimmedLine === '---' || trimmedLine === '***' || trimmedLine === '___') {\n blocks.push({\n object: 'block',\n type: 'divider',\n divider: {}\n });\n }\n // Check for headers (markdown style)\n else if (trimmedLine.startsWith('#### ')) {\n const richText = parseRichText(trimmedLine.substring(5));\n blocks.push({\n object: 'block',\n type: 'heading_3',\n heading_3: {\n rich_text: richText\n }\n });\n }\n else if (trimmedLine.startsWith('### ')) {\n const richText = parseRichText(trimmedLine.substring(4));\n blocks.push({\n object: 'block',\n type: 'heading_3',\n heading_3: {\n rich_text: richText\n }\n });\n }\n else if (trimmedLine.startsWith('## ')) {\n const richText = parseRichText(trimmedLine.substring(3));\n blocks.push({\n object: 'block',\n type: 'heading_2',\n heading_2: {\n rich_text: richText\n }\n });\n }\n else if (trimmedLine.startsWith('# ')) {\n const richText = parseRichText(trimmedLine.substring(2));\n blocks.push({\n object: 'block',\n type: 'heading_1',\n heading_1: {\n rich_text: richText\n }\n });\n }\n // Check for bullet points\n else if (trimmedLine.startsWith('- ') || trimmedLine.startsWith('* ')) {\n const richText = parseRichText(trimmedLine.substring(2));\n blocks.push({\n object: 'block',\n type: 'bulleted_list_item',\n bulleted_list_item: {\n rich_text: richText\n }\n });\n }\n // Check for numbered lists\n else if (/^\\d+\\.\\s/.test(trimmedLine)) {\n const content = trimmedLine.replace(/^\\d+\\.\\s/, '');\n const richText = parseRichText(content);\n blocks.push({\n object: 'block',\n type: 'numbered_list_item',\n numbered_list_item: {\n rich_text: richText\n }\n });\n }\n // Check for quotes\n else if (trimmedLine.startsWith('> ')) {\n const richText = parseRichText(trimmedLine.substring(2));\n blocks.push({\n object: 'block',\n type: 'quote',\n quote: {\n rich_text: richText\n }\n });\n }\n // Regular paragraph\n else {\n const richText = parseRichText(trimmedLine);\n blocks.push({\n object: 'block',\n type: 'paragraph',\n paragraph: {\n rich_text: richText\n }\n });\n }\n }\n \n // Handle case where code block wasn't closed\n if (inCodeBlock && codeBlockContent.length > 0) {\n blocks.push({\n object: 'block',\n type: 'code',\n code: {\n caption: [],\n rich_text: [{\n type: 'text',\n text: { content: codeBlockContent.join('\\n') }\n }],\n language: codeBlockLanguage || 'plain text'\n }\n });\n }\n \n return blocks;\n}\n\n// Function to parse rich text formatting (bold, italic, links)\nfunction parseRichText(text) {\n const richTextArray = [];\n \n // Handle simple case with no formatting\n if (!text.includes('**') && !text.includes('__') && !text.includes('*') && \n !text.includes('_') && !text.includes('[')) {\n return [{\n type: 'text',\n text: { content: text }\n }];\n }\n \n let workingText = text;\n let segments = [];\n \n // Process links first [text](url)\n const linkRegex = /\\[([^\\]]*)\\]\\(([^)]*)\\)/g;\n let linkMatch;\n let lastLinkIndex = 0;\n \n while ((linkMatch = linkRegex.exec(text)) !== null) {\n // Add text before link\n if (linkMatch.index > lastLinkIndex) {\n const beforeText = text.substring(lastLinkIndex, linkMatch.index);\n if (beforeText) {\n segments.push({ type: 'text', content: beforeText });\n }\n }\n \n // Add link\n segments.push({\n type: 'link',\n content: linkMatch[1],\n url: linkMatch[2]\n });\n \n lastLinkIndex = linkMatch.index + linkMatch[0].length;\n }\n \n // Add remaining text after last link\n if (lastLinkIndex < text.length) {\n const remainingText = text.substring(lastLinkIndex);\n if (remainingText) {\n segments.push({ type: 'text', content: remainingText });\n }\n }\n \n // If no links found, treat entire text as one segment\n if (segments.length === 0) {\n segments.push({ type: 'text', content: text });\n }\n \n // Now process each segment for bold/italic formatting\n segments.forEach(segment => {\n if (segment.type === 'link') {\n // Links can have formatting too\n const formattedContent = processTextFormatting(segment.content);\n formattedContent.forEach(item => {\n richTextArray.push({\n type: 'text',\n text: { \n content: item.content,\n link: { url: segment.url }\n },\n annotations: item.annotations || {}\n });\n });\n } else {\n // Regular text - process for formatting\n const formattedContent = processTextFormatting(segment.content);\n formattedContent.forEach(item => {\n richTextArray.push({\n type: 'text',\n text: { content: item.content },\n annotations: item.annotations || {}\n });\n });\n }\n });\n \n return richTextArray;\n}\n\n// Helper function to process bold/italic formatting\nfunction processTextFormatting(text) {\n const result = [];\n let currentIndex = 0;\n \n // Patterns for markdown formatting - order matters (bold before italic)\n const patterns = [\n { regex: /\\*\\*(.*?)\\*\\*/g, annotation: { bold: true } },\n { regex: /__(.*?)__/g, annotation: { bold: true } },\n { regex: /\\*(.*?)\\*/g, annotation: { italic: true } },\n { regex: /_(.*?)_/g, annotation: { italic: true } }\n ];\n \n let matches = [];\n \n // Find all formatting matches\n patterns.forEach(pattern => {\n let match;\n const regex = new RegExp(pattern.regex.source, pattern.regex.flags);\n while ((match = regex.exec(text)) !== null) {\n matches.push({\n start: match.index,\n end: match.index + match[0].length,\n content: match[1],\n annotation: pattern.annotation,\n fullMatch: match[0]\n });\n }\n });\n \n // Sort matches by position and remove overlapping matches\n matches.sort((a, b) => a.start - b.start);\n \n // Remove overlapping matches (keep the first one)\n const filteredMatches = [];\n let lastEnd = -1;\n \n matches.forEach(match => {\n if (match.start >= lastEnd) {\n filteredMatches.push(match);\n lastEnd = match.end;\n }\n });\n \n // If no formatting found, return simple text\n if (filteredMatches.length === 0) {\n return [{ content: text }];\n }\n \n // Build result array\n let lastIndex = 0;\n \n filteredMatches.forEach(match => {\n // Add text before the match\n if (match.start > lastIndex) {\n const beforeText = text.substring(lastIndex, match.start);\n if (beforeText) {\n result.push({ content: beforeText });\n }\n }\n \n // Add the formatted text\n result.push({\n content: match.content,\n annotations: match.annotation\n });\n \n lastIndex = match.end;\n });\n \n // Add remaining text\n if (lastIndex < text.length) {\n const remainingText = text.substring(lastIndex);\n if (remainingText) {\n result.push({ content: remainingText });\n }\n }\n \n return result;\n}\n\n// Convert the output text to Notion blocks\nconst notionBlocks = textToNotionBlocks(outputText);\n\n// Create plain text excerpt (first 300 characters)\nfunction createPlainTextExcerpt(text, maxLength = 300) {\n if (!text || typeof text !== 'string') {\n return '';\n }\n \n // Remove markdown formatting for plain text excerpt\n let plainText = text\n // Remove headers\n .replace(/^#{1,6}\\s+/gm, '')\n // Remove horizontal rules\n .replace(/^[-*_]{3,}$/gm, '')\n // Remove code blocks\n .replace(/```[\\s\\S]*?```/g, '')\n // Remove inline code\n .replace(/`([^`]+)`/g, '$1')\n // Remove links but keep text\n .replace(/\\[([^\\]]*)\\]\\([^)]*\\)/g, '$1')\n // Remove bold and italic\n .replace(/\\*\\*([^*]+)\\*\\*/g, '$1')\n .replace(/__([^_]+)__/g, '$1')\n .replace(/\\*([^*]+)\\*/g, '$1')\n .replace(/_([^_]+)_/g, '$1')\n // Remove bullet points and list markers\n .replace(/^[-*+]\\s+/gm, '')\n .replace(/^\\d+\\.\\s+/gm, '')\n // Remove quotes\n .replace(/^>\\s+/gm, '')\n // Clean up extra whitespace\n .replace(/\\n\\s*\\n/g, '\\n')\n .replace(/^\\s+|\\s+$/g, '')\n .replace(/\\s+/g, ' ');\n \n // Truncate to maxLength and add ellipsis if needed\n if (plainText.length > maxLength) {\n // Try to break at a word boundary\n const truncated = plainText.substring(0, maxLength);\n const lastSpace = truncated.lastIndexOf(' ');\n \n if (lastSpace > maxLength * 0.8) { // If we can break at a word within 80% of max length\n return truncated.substring(0, lastSpace) + '...';\n } else {\n return truncated + '...';\n }\n }\n \n return plainText;\n}\n\nconst plainTextExcerpt = createPlainTextExcerpt(outputText);\n\n// Return the blocks in the format expected by n8n\nreturn {\n json: {\n blocks: notionBlocks,\n page_id: pageId, // Include page_id if available\n original_output: outputText,\n plain_text_excerpt: plainTextExcerpt,\n block_count: notionBlocks.length\n }\n};"
},
"typeVersion": 2
},
{
"id": "3a976100-d298-415b-bd64-8b68dd547104",
"name": "When clicking ‘Execute workflow’",
"type": "n8n-nodes-base.manualTrigger",
"position": [
-260,
0
],
"parameters": {},
"typeVersion": 1
},
{
"id": "57c30dd2-3e55-4d8e-86a7-956fa86ffdd1",
"name": "Mock data",
"type": "n8n-nodes-base.set",
"position": [
-20,
0
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "884c6f7c-6dee-4fc7-be70-d733c076bc5b",
"name": "output",
"type": "string",
"value": "# Doloria Vensat Ipsum\n\nLorem versatio clarnum est vendora siltrix, et moratia crendix lortum valdi. Cursentia flomidar nuxter velion, agranda flumanti torquis. *Velatrix domor silvenum* — carendus in torquatis, nebulo squanda litur. Trandem solquix veritor, ulmeris paxondae vulturum grestia invernox.\n\n> “Nostra vintrix est, florandum est.” — Vexar Omnitron, Codex Veritas\n\nVenustra maxon lurtavis credentor fluvia. Grendix talmora vendos questrion, nebularas sintoria metril. Tractum in calderae floritia ramondux, ventalis frumor saxentin. Ultranor vistrix candela morit, in parandum vixellor nostrem. Torvix pelanda selquor — flandrix omnia trevalla.\n\n## Vestiran Monclavis Quord\n\nTrandora visclarum meridio juxenta, flammor regentrix boltorum. Corrivax tenebris lurtantis draxelor montilar, **vivandor estro mentelix**. Brevisculae trelmon vexor flintor qui dramulax. Ferontis calvantar voltria nexarium exelvis. Gravandus yeltrix mandor, silverom paxitas dulvore est brontium."
}
]
}
},
"typeVersion": 3.4
},
{
"id": "b9d263bb-5d62-4171-8e33-f4060b5e893b",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-80,
-280
],
"parameters": {
"color": 3,
"width": 220,
"height": 440,
"content": "# Mock data\n\nThis node only serves the purpose of returning dummy Markdown-formatted text in the `output` field. Replace this with your actual data source."
},
"typeVersion": 1
},
{
"id": "98f7de06-cdf2-49fd-895e-3b2b7bc59837",
"name": "Insert Notion page content",
"type": "n8n-nodes-base.httpRequest",
"position": [
460,
0
],
"parameters": {
"url": "https://api.notion.com/v1/blocks/2255b6e0c94f80e7951df98d53ce2c39/children",
"method": "PATCH",
"options": {
"batching": {
"batch": {
"batchSize": 100
}
}
},
"sendBody": true,
"sendHeaders": true,
"authentication": "predefinedCredentialType",
"bodyParameters": {
"parameters": [
{
"name": "children",
"value": "={{ $json.blocks }}"
}
]
},
"headerParameters": {
"parameters": [
{
"name": "Notion-Version",
"value": "2022-06-28"
}
]
},
"nodeCredentialType": "notionApi"
},
"credentials": {
"notionApi": {
"id": "80",
"name": "Notion david-internal"
}
},
"typeVersion": 4.2
},
{
"id": "4f94864f-5669-4c00-aa05-b95b8bcbb7a6",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
160,
-280
],
"parameters": {
"width": 220,
"height": 440,
"content": "# Conversion\n\nThis code converts the markdown string into the block format required by Notion."
},
"typeVersion": 1
},
{
"id": "f88266c9-faaa-481c-821d-5fab70823ef0",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
400,
-280
],
"parameters": {
"color": 4,
"width": 220,
"height": 440,
"content": "# Update\n\nThis node updates a Notion page with the blocks generated in the previous step. Replace the page ID in the URL field with your actual Notion page ID or an expression that returns the page ID."
},
"typeVersion": 1
}
],
"pinData": {},
"connections": {
"Mock data": {
"main": [
[
{
"node": "Convert into Notion blocks",
"type": "main",
"index": 0
}
]
]
},
"Convert into Notion blocks": {
"main": [
[
{
"node": "Insert Notion page content",
"type": "main",
"index": 0
}
]
]
},
"When clicking ‘Execute workflow’": {
"main": [
[
{
"node": "Mock data",
"type": "main",
"index": 0
}
]
]
}
}
}