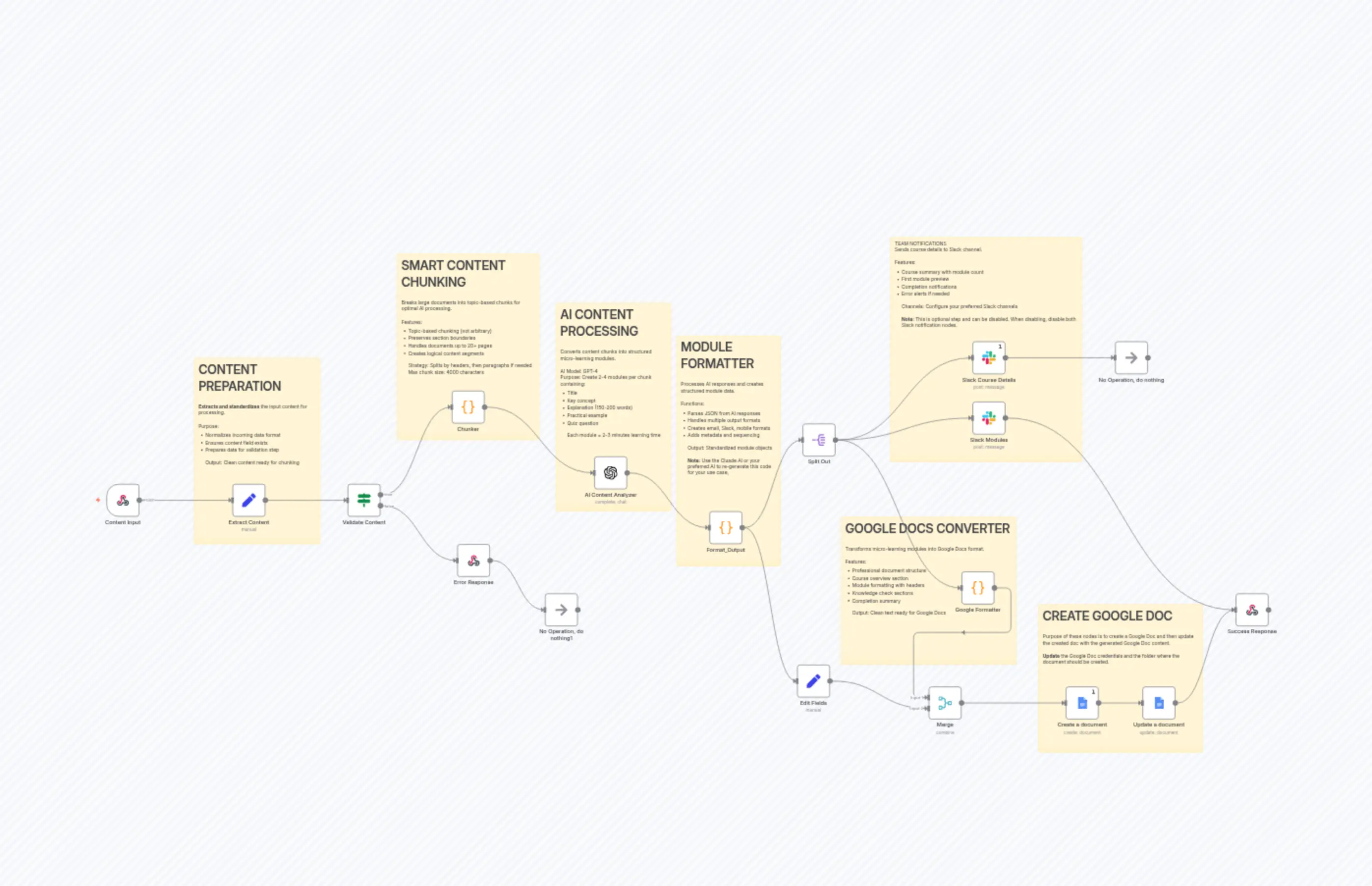
Micro-Learning Creator (Improved)
Description
Categories
🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.ifn8n-nodes-base.setn8n-nodes-base.setn8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.noOpn8n-nodes-base.noOpn8n-nodes-base.mergen8n-nodes-base.slack
PriceGratuit
Views0
Last Updated11/28/2025
workflow.json
{
"id": "nH6lZ9ACSB5XxZ4K",
"meta": {
"instanceId": "3c35a703d75886d08705c211ee107a7513430dd05494ec0c569f28570a3768fa",
"templateCredsSetupCompleted": true
},
"name": "Micro-Learning Creator (Improved)",
"tags": [],
"nodes": [
{
"id": "webhook-input",
"name": "Content Input",
"type": "n8n-nodes-base.webhook",
"position": [
-992,
144
],
"webhookId": "cbafb9f0-76e2-4fb4-be9d-c5872093c0d8",
"parameters": {
"path": "micro-learning-v2",
"options": {},
"httpMethod": "POST",
"responseMode": "lastNode"
},
"typeVersion": 1
},
{
"id": "validate",
"name": "Validate Content",
"type": "n8n-nodes-base.if",
"position": [
-288,
144
],
"parameters": {
"conditions": {
"string": [
{
"value1": "={{ $json.body.content }}",
"operation": "isNotEmpty"
}
]
}
},
"typeVersion": 1
},
{
"id": "ai-analyzer",
"name": "AI Content Analyzer",
"type": "n8n-nodes-base.openAi",
"position": [
432,
64
],
"parameters": {
"model": "gpt-4.1",
"prompt": {
"messages": [
{
"content": "=Break down this content into micro-learning modules: {{ $json.body.content }}"
},
{
"role": "system",
"content": "=You are a micro-learning expert. You're receiving a section of a larger document about: \"{{ $json.chunker.topic_hint }}\".\n\nAnalyze this content section and create 2-4 focused micro-learning modules that:\n1. Cover the specific topics in this section (don't create modules about topics not mentioned)\n2. Are each 2-3 minutes to consume\n3. Use the section's actual content (don't add external information)\n4. Include practical examples from the provided text\n5. Create questions that test understanding of THIS section's content\n6. Do not Hallucinate\n\nThis is chunk {{ $json.chunker.chunk_id }} of {{ $json.chunker.total_chunks }} from a larger document.\n\nDo not include any text before or after the JSON array.\nReturn ONLY a valid JSON array with modules containing: \n\ntitle, \nkey_concept, \nexplanation (150-200 words), \npractical_example, \nquick_quiz_question. "
}
]
},
"options": {
"topP": 1,
"temperature": 0.5,
"frequency_penalty": 0
},
"resource": "chat",
"requestOptions": {}
},
"credentials": {
"openAiApi": {
"id": "PzzLblAykQPFIDZf",
"name": "OpenAi account"
}
},
"typeVersion": 1
},
{
"id": "success",
"name": "Success Response",
"type": "n8n-nodes-base.respondToWebhook",
"position": [
2304,
464
],
"parameters": {
"options": {},
"respondWith": "json",
"responseBody": "={{ $json }}"
},
"typeVersion": 1
},
{
"id": "error",
"name": "Error Response",
"type": "n8n-nodes-base.respondToWebhook",
"position": [
32,
320
],
"parameters": {
"options": {},
"respondWith": "json",
"responseBody": "{\"error\": \"Missing content field. Please provide content to analyze.\", \"example\": {\"content\": \"Your learning content here...\"}}"
},
"typeVersion": 1
},
{
"id": "8f2cb4de-e2cf-4c7b-85c5-da1ad294850f",
"name": "Extract Content",
"type": "n8n-nodes-base.set",
"position": [
-624,
144
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "d1a1f21c-61ec-43d3-817d-4503eba6d3f3",
"name": "body.content",
"type": "string",
"value": "={{ $json.body.content }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "d6f42e5d-c52b-4863-9274-5d7523a17802",
"name": "Chunker",
"type": "n8n-nodes-base.code",
"position": [
16,
-128
],
"parameters": {
"jsCode": "// Topic-Based Document Chunker - Smart Content Division\nconst content = $input.first().json.body.content;\nconst maxChunkSize = 4000; // Larger chunks for complete topics\nconst minChunkSize = 1000; // Minimum viable chunk size\n\nconsole.log('Original content length:', content.length, 'characters');\n\n// If content is small enough, don't chunk\nif (content.length <= maxChunkSize) {\n console.log('Content is small enough, no chunking needed');\n return items;\n}\n\nconsole.log('Content is large, applying topic-based chunking');\n\nfunction topicBasedChunk(text, maxSize, minSize) {\n const chunks = [];\n \n // Strategy 1: Split by clear section headers (most common in business docs)\n let sections = [];\n \n // Look for various header patterns\n const headerPatterns = [\n /\\n\\s*(?:\\d+\\.|Chapter \\d+|Section \\d+|Part \\d+)[\\s:]/gi, // 1. Section 1: or Chapter 1:\n /\\n\\s*[A-Z][A-Z\\s]{10,}(?:\\n|$)/g, // UPPERCASE HEADERS\n /\\n\\s*#{1,3}\\s+[^\\n]+/g, // # Markdown headers\n /\\n\\s*[^\\n]*(?:Policy|Procedure|Guidelines|Rules)[\\s:]/gi, // Policy headers\n /\\n\\s*[^\\n]*(?:Overview|Introduction|Summary|Conclusion)[\\s:]?/gi // Common section names\n ];\n \n // Try each pattern to find the best split\n for (const pattern of headerPatterns) {\n const matches = text.match(pattern);\n if (matches && matches.length >= 2) {\n console.log(`Found ${matches.length} sections using pattern:`, pattern.toString().substring(0, 50));\n sections = text.split(pattern);\n break;\n }\n }\n \n // Fallback: Split by paragraph breaks if no clear headers\n if (sections.length < 2) {\n console.log('No clear headers found, splitting by paragraphs');\n sections = text.split(/\\n\\s*\\n\\s*\\n/); // Double line breaks\n }\n \n // Strategy 2: Group sections into logical chunks\n let currentChunk = '';\n let chunkStartIndex = 0;\n \n for (let i = 0; i < sections.length; i++) {\n const section = sections[i].trim();\n if (!section) continue;\n \n const sectionWithNewline = (currentChunk ? '\\n\\n' : '') + section;\n const potentialChunk = currentChunk + sectionWithNewline;\n \n // Decision logic for chunk boundaries\n if (potentialChunk.length > maxSize && currentChunk.length >= minSize) {\n // Current chunk is full and viable - save it\n chunks.push({\n chunk_id: chunks.length + 1,\n content: currentChunk.trim(),\n topic_hint: extractTopicHint(currentChunk),\n sections_count: i - chunkStartIndex,\n length: currentChunk.length\n });\n \n console.log(`Created chunk ${chunks.length}: \"${chunks[chunks.length-1].topic_hint}\" (${currentChunk.length} chars)`);\n \n // Start new chunk\n currentChunk = section;\n chunkStartIndex = i;\n \n } else {\n // Add section to current chunk\n currentChunk = potentialChunk;\n }\n }\n \n // Don't forget the last chunk\n if (currentChunk.trim()) {\n chunks.push({\n chunk_id: chunks.length + 1,\n content: currentChunk.trim(),\n topic_hint: extractTopicHint(currentChunk),\n sections_count: sections.length - chunkStartIndex,\n length: currentChunk.length\n });\n \n console.log(`Created final chunk ${chunks.length}: \"${chunks[chunks.length-1].topic_hint}\" (${currentChunk.length} chars)`);\n }\n \n return chunks;\n}\n\n// Helper function to extract topic hints from content\nfunction extractTopicHint(text) {\n const firstLine = text.split('\\n')[0].trim();\n \n // Look for clear topic indicators\n const topicPatterns = [\n /(?:policy|procedure|guideline|rule|protocol)s?\\s+(?:for|on|about)\\s+([^.]+)/gi,\n /(?:section|chapter|part)\\s+\\d+[:\\s]+([^.\\n]+)/gi,\n /^([^.\\n]{10,50})(?:\\.|:|\\n)/, // First substantial line\n /([A-Z][^.\\n]{10,40})/ // Capitalized phrases\n ];\n \n for (const pattern of topicPatterns) {\n const match = firstLine.match(pattern);\n if (match && match[1]) {\n return match[1].trim().substring(0, 40);\n }\n }\n \n // Fallback: first meaningful words\n const words = text.split(/\\s+/).slice(0, 6).join(' ');\n return words.length > 50 ? words.substring(0, 47) + '...' : words;\n}\n\n// Apply the chunking\nconst chunks = topicBasedChunk(content, maxChunkSize, minChunkSize);\n\nconsole.log('=== CHUNKING RESULTS ===');\nconsole.log(`Created ${chunks.length} topic-based chunks:`);\nchunks.forEach((chunk, i) => {\n console.log(` ${i+1}. \"${chunk.topic_hint}\" - ${chunk.length} chars, ${chunk.sections_count} sections`);\n});\n\n// Return chunks with enhanced metadata\nconst result = chunks.map(chunk => ({\n json: {\n ...items[0].json, // Keep original metadata\n content: chunk.content,\n chunk_info: {\n chunk_id: chunk.chunk_id,\n total_chunks: chunks.length,\n chunk_size: chunk.length,\n topic_hint: chunk.topic_hint,\n sections_in_chunk: chunk.sections_count,\n chunking_strategy: 'topic-based'\n },\n is_chunked: chunks.length > 1,\n original_content_length: content.length\n }\n}));\n\nconsole.log('Returning', result.length, 'topic-based chunks for AI processing');\nreturn result;"
},
"typeVersion": 2
},
{
"id": "ce7acd35-9c73-430c-976a-9384e6da9174",
"name": "Split Out",
"type": "n8n-nodes-base.splitOut",
"position": [
1040,
-32
],
"parameters": {
"options": {},
"fieldToSplitOut": "modules"
},
"typeVersion": 1
},
{
"id": "a9eb5bf0-761d-4e38-b6ae-f86499e50d26",
"name": "Update a document",
"type": "n8n-nodes-base.googleDocs",
"position": [
2032,
736
],
"parameters": {
"actionsUi": {
"actionFields": [
{
"text": "={{ $('Merge').item.json.google_docs_content }}",
"action": "insert"
}
]
},
"operation": "update",
"documentURL": "={{ $json.id }}"
},
"credentials": {
"googleDocsOAuth2Api": {
"id": "I3SWEhEVJoaLogmU",
"name": "Google Docs account"
}
},
"typeVersion": 2
},
{
"id": "2dd7a638-7d51-47fc-8203-945d7c336874",
"name": "Create a document",
"type": "n8n-nodes-base.googleDocs",
"position": [
1808,
736
],
"parameters": {
"title": "={{ $('Format_Output').item.json.course_id }}",
"folderId": "default"
},
"credentials": {
"googleDocsOAuth2Api": {
"id": "I3SWEhEVJoaLogmU",
"name": "Google Docs account"
}
},
"executeOnce": true,
"typeVersion": 2
},
{
"id": "e1019640-d08a-476b-91d1-80c1905556ef",
"name": "Format_Output",
"type": "n8n-nodes-base.code",
"position": [
768,
224
],
"parameters": {
"jsCode": "// Fixed merge code for OpenAI message format\nconsole.log('=== MERGE PROCESSING ===');\nconsole.log('Total items received:', items.length);\n\nlet allModules = [];\nlet processingErrors = [];\n\n// Process each item from the AI Content Analyzer\nfor (let i = 0; i < items.length; i++) {\n const item = items[i];\n console.log('Processing item', i + 1);\n \n if (item && item.json && item.json.message && item.json.message.content) {\n const aiResponseString = item.json.message.content;\n console.log('Found AI response string, length:', aiResponseString.length);\n \n try {\n // Parse the JSON string from the AI response\n const parsedModules = JSON.parse(aiResponseString);\n \n if (Array.isArray(parsedModules)) {\n console.log('Successfully parsed', parsedModules.length, 'modules from item', i + 1);\n allModules = allModules.concat(parsedModules);\n } else {\n console.log('Parsed content is not an array for item', i + 1);\n processingErrors.push('Item ' + (i + 1) + ' - Not an array');\n }\n \n } catch (error) {\n console.log('JSON parse error for item', i + 1, ':', error.message);\n processingErrors.push('Item ' + (i + 1) + ' - Parse error: ' + error.message);\n }\n \n } else {\n console.log('Item', i + 1, 'missing expected structure');\n processingErrors.push('Item ' + (i + 1) + ' - Missing message.content');\n }\n}\n\nconsole.log('=== PROCESSING SUMMARY ===');\nconsole.log('Total modules extracted:', allModules.length);\nconsole.log('Processing errors:', processingErrors.length);\n\n// Remove duplicates based on title\nconst uniqueModules = [];\nconst seenTitles = new Set();\n\nfor (let i = 0; i < allModules.length; i++) {\n const module = allModules[i];\n const normalizedTitle = (module.title || 'untitled').toLowerCase().trim();\n \n if (!seenTitles.has(normalizedTitle)) {\n seenTitles.add(normalizedTitle);\n uniqueModules.push(module);\n } else {\n console.log('Skipping duplicate module:', module.title);\n }\n}\n\nconsole.log('Unique modules after deduplication:', uniqueModules.length);\n\n// Create final result with all modules\nconst result = {\n course_id: 'course_' + Date.now(),\n total_modules: uniqueModules.length,\n estimated_total_time: uniqueModules.length * 3 + ' minutes',\n difficulty_level: uniqueModules.length <= 3 ? 'beginner' : uniqueModules.length <= 5 ? 'intermediate' : 'advanced',\n created_at: new Date().toISOString(),\n \n processing_info: {\n chunks_processed: items.length,\n modules_found: allModules.length,\n modules_after_dedup: uniqueModules.length,\n processing_errors: processingErrors\n },\n \n modules: uniqueModules.map((module, index) => ({\n id: 'module_' + (index + 1),\n sequence: index + 1,\n title: module.title || 'Module ' + (index + 1),\n key_concept: module.key_concept || 'Key concept not provided',\n content: module.explanation || 'Content not provided',\n example: module.practical_example || 'Example not provided',\n quiz: module.quick_quiz_question || 'Question not provided',\n estimated_minutes: 3,\n \n // Multi-channel formats\n formats: {\n email: {\n subject: '📚 Module ' + (index + 1) + ': ' + (module.title || 'Untitled'),\n body: '🎯 **Key Concept**: ' + (module.key_concept || 'N/A') + '\\n\\n📖 **Learn This**:\\n' + (module.explanation || 'N/A') + '\\n\\n💡 **Real Example**: ' + (module.practical_example || 'N/A') + '\\n\\n❓ **Quick Check**: ' + (module.quick_quiz_question || 'N/A') + '\\n\\n⏱️ **Time**: 3 minutes'\n },\n \n slack: {\n text: '📚 *Module ' + (index + 1) + ': ' + (module.title || 'Untitled') + '*\\n\\n🎯 *Key*: ' + (module.key_concept || 'N/A') + '\\n\\n' + (module.explanation || 'N/A') + '\\n\\n💡 *Example*: ' + (module.practical_example || 'N/A') + '\\n\\n❓ *Quiz*: ' + (module.quick_quiz_question || 'N/A') + '\\n\\n⏱️ 3 min read'\n },\n \n mobile: '📚 ' + (module.title || 'Untitled') + '\\n\\n🎯 ' + (module.key_concept || 'N/A') + '\\n\\n' + (module.explanation || 'N/A') + '\\n\\n💡 ' + (module.practical_example || 'N/A') + '\\n\\n❓ ' + (module.quick_quiz_question || 'N/A') + '\\n\\n⏱️ 3 min'\n }\n }))\n};\n\nconsole.log('=== FINAL RESULT ===');\nconsole.log('Returning course with', result.total_modules, 'modules');\nconsole.log('Module titles:', result.modules.map(m => m.title));\n\nreturn [{ json: result }];"
},
"typeVersion": 2
},
{
"id": "cd6e38e3-64c6-4c9d-9d87-9f79a29fa195",
"name": "Edit Fields",
"type": "n8n-nodes-base.set",
"position": [
1024,
672
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "e63b0306-2fc5-4d8c-bde0-87f1c450762d",
"name": "course_id",
"type": "string",
"value": "={{ $json.course_id }}"
},
{
"id": "b823595a-0e14-4c0a-9965-9d429735ba3b",
"name": "total_modules",
"type": "number",
"value": "={{ $json.total_modules }}"
},
{
"id": "582ab2a2-4a88-4cfa-9e16-253f10cc9d0f",
"name": "estimated_total_time",
"type": "string",
"value": "={{ $json.estimated_total_time }}"
},
{
"id": "959c51e8-e588-4a20-ae1c-bd79e17e1941",
"name": "difficulty_level",
"type": "string",
"value": "={{ $json.difficulty_level }}"
},
{
"id": "750c4608-acc1-4097-bb6d-6c66ade37be0",
"name": "created_at",
"type": "string",
"value": "={{ $json.created_at }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "709671a3-a263-46b2-9d29-7ffb77894f37",
"name": "Merge",
"type": "n8n-nodes-base.merge",
"position": [
1408,
736
],
"parameters": {
"mode": "combine",
"options": {},
"combineBy": "combineByPosition"
},
"typeVersion": 3.2
},
{
"id": "2fe4d651-6820-4a04-a080-a593cf74221e",
"name": "No Operation, do nothing",
"type": "n8n-nodes-base.noOp",
"position": [
1952,
-272
],
"parameters": {},
"typeVersion": 1
},
{
"id": "4152f8e3-fad2-4f29-b6fb-9c5c14204067",
"name": "No Operation, do nothing1",
"type": "n8n-nodes-base.noOp",
"position": [
288,
464
],
"parameters": {},
"typeVersion": 1
},
{
"id": "adb4236e-2b96-4eab-b42e-de6c13696232",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-736,
-224
],
"parameters": {
"width": 368,
"height": 544,
"content": "# CONTENT PREPARATION\n\n**Extracts and standardizes** the input content for processing.\n\nPurpose:\n- Normalizes incoming data format\n- Ensures content field exists\n- Prepares data for validation step\n\nOutput: Clean content ready for chunking"
},
"typeVersion": 1
},
{
"id": "slack-notify",
"name": "Slack Modules",
"type": "n8n-nodes-base.slack",
"position": [
1536,
-96
],
"webhookId": "88b71c18-bb46-4fc1-a464-c33f5da4505e",
"parameters": {
"text": "=Title: {{ $json.title }}\nModule: {{ $json.sequence }}\nID: {{ $json.id }}\nTime: {{ $json.estimated_minutes }} minutes\n\n{{ $json.formats.slack.text }}\n-------------------------------------",
"select": "channel",
"channelId": {
"__rl": true,
"mode": "list",
"value": "C0963H18JCX",
"cachedResultName": "all-mytest2025"
},
"otherOptions": {
"mrkdwn": true
}
},
"credentials": {
"slackApi": {
"id": "TjO2nAExXHrUpUIC",
"name": "Slack account"
}
},
"typeVersion": 2
},
{
"id": "12566e4f-2759-4d8f-b597-8320fbd38b49",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-144,
-528
],
"parameters": {
"width": 416,
"height": 544,
"content": "# SMART CONTENT CHUNKING\n\nBreaks large documents into topic-based chunks for optimal AI processing.\n\nFeatures:\n- Topic-based chunking (not arbitrary)\n- Preserves section boundaries\n- Handles documents up to 20+ pages\n- Creates logical content segments\n\nStrategy: Splits by headers, then paragraphs if needed\nMax chunk size: 4000 characters"
},
"typeVersion": 1
},
{
"id": "bc48247f-6ba3-452b-8f0f-868000abc254",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
320,
-384
],
"parameters": {
"width": 336,
"height": 608,
"content": "# AI CONTENT PROCESSING\n\nConverts content chunks into structured micro-learning modules.\n\nAI Model: GPT-4\nPurpose: Create 2-4 modules per chunk containing:\n- Title\n- Key concept\n- Explanation (150-200 words)\n- Practical example\n- Quiz question\n\nEach module = 2-3 minutes learning time"
},
"typeVersion": 1
},
{
"id": "dd2956a1-1a92-4ff0-b935-ce2de38b4191",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
672,
-288
],
"parameters": {
"width": 304,
"height": 672,
"content": "# MODULE FORMATTER\n\nProcesses AI responses and creates structured module data.\n\nFunctions:\n- Parses JSON from AI responses\n- Handles multiple output formats\n- Creates email, Slack, mobile formats\n- Adds metadata and sequencing\n\nOutput: Standardized module objects\n\n**Note**: Use the Cluade AI or your preferred AI to re-generate this code for your use case,"
},
"typeVersion": 1
},
{
"id": "1c7ead8b-a53f-47a2-9a01-f30aff48dc08",
"name": "Google Formatter",
"type": "n8n-nodes-base.code",
"position": [
1504,
400
],
"parameters": {
"jsCode": "// Google Docs Formatter - Handles Individual Modules\nconsole.log('Processing', items.length, 'module items');\n\n// Check if we have individual modules or course data\nlet modules = [];\nlet courseMetadata = {};\n\nif (items.length === 1 && items[0].json.modules) {\n // Single course object with modules array\n const courseData = items[0].json;\n modules = courseData.modules;\n courseMetadata = courseData;\n} else {\n // Multiple individual module objects\n modules = items.map(item => item.json);\n \n // Extract course metadata from first module or create defaults\n courseMetadata = {\n course_id: 'Generated Course',\n total_modules: modules.length,\n estimated_total_time: `${modules.length * 3} minutes`,\n difficulty_level: modules.length <= 3 ? 'beginner' : modules.length <= 5 ? 'intermediate' : 'advanced',\n created_at: new Date().toISOString()\n };\n}\n\n// Sort modules by sequence\nmodules.sort((a, b) => (a.sequence || 0) - (b.sequence || 0));\n\nconsole.log('Found', modules.length, 'modules to process');\n\n// Extract course metadata with fallbacks\nconst courseTitle = \"Template Submission Guidelines - Micro-Learning Course\";\nconst courseId = courseMetadata.course_id || 'Generated Course';\nconst totalModules = courseMetadata.total_modules || modules.length;\nconst estimatedTime = courseMetadata.estimated_total_time || `${modules.length * 3} minutes`;\nconst difficultyLevel = courseMetadata.difficulty_level || 'intermediate';\nconst createdDate = courseMetadata.created_at ? new Date(courseMetadata.created_at).toLocaleDateString() : new Date().toLocaleDateString();\n\n// Start building the Google Docs formatted content\nlet googleDocsContent = `${courseTitle}\n\nCOURSE OVERVIEW\nCourse ID: ${courseId}\nTotal Modules: ${totalModules}\nEstimated Completion Time: ${estimatedTime}\nDifficulty Level: ${difficultyLevel.toUpperCase()}\nCreated: ${createdDate}\n\n===============================================\n\n`;\n\n// Process each module\nmodules.forEach((module, index) => {\n const moduleNum = module.sequence || (index + 1);\n const title = module.title || `Module ${moduleNum}`;\n const duration = module.estimated_minutes || 3;\n const keyConcept = module.key_concept || 'Key concept not provided';\n const content = module.content || 'Content not provided';\n const example = module.example || module.practical_example || 'Example not provided';\n const quiz = module.quiz || module.quick_quiz_question || 'Quiz question not provided';\n\n googleDocsContent += `MODULE ${moduleNum}: ${title}\nDuration: ${duration} minutes\n\nKEY CONCEPT\n${keyConcept}\n\nCONTENT\n${content}\n\nPRACTICAL EXAMPLE\n${example}\n\nKNOWLEDGE CHECK\n${quiz}\n\n---\n\n`;\n});\n\n// Add completion section\ngoogleDocsContent += `COURSE COMPLETION\nCongratulations! You have completed all ${totalModules} modules of the Template Submission Guidelines course.\n\nTotal time invested: ${estimatedTime}\nKnowledge areas covered:\n`;\n\n// Add module summary\nmodules.forEach((module, index) => {\n const title = module.title || `Module ${index + 1}`;\n googleDocsContent += `• ${title}\\n`;\n});\n\ngoogleDocsContent += `\nFor additional questions or clarification on template submission guidelines, please refer to the official documentation or contact support.\n\nDocument generated: ${new Date().toLocaleString()}`;\n\n// Return the formatted content\nconst result = {\n google_docs_content: googleDocsContent,\n metadata: {\n original_course_id: courseId,\n modules_processed: modules.length,\n formatted_at: new Date().toISOString(),\n content_length: googleDocsContent.length,\n estimated_pages: Math.ceil(googleDocsContent.length / 2500)\n },\n debug_info: {\n input_items: items.length,\n modules_found: modules.length,\n first_module_title: modules[0]?.title || 'N/A',\n data_format: items.length === 1 ? 'single_course' : 'individual_modules'\n }\n};\n\nconsole.log('Google Docs format generated successfully');\nconsole.log('Content length:', googleDocsContent.length, 'characters');\nconsole.log('Modules processed:', modules.length);\n\nreturn [{ json: result }];"
},
"typeVersion": 2
},
{
"id": "d73fc192-416b-4d81-b993-8381ceffae80",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
1152,
240
],
"parameters": {
"width": 512,
"height": 432,
"content": "# GOOGLE DOCS CONVERTER\n\nTransforms micro-learning modules into Google Docs format.\n\nFeatures:\n- Professional document structure\n- Course overview section\n- Module formatting with headers\n- Knowledge check sections\n- Completion summary\n\nOutput: Clean text ready for Google Docs"
},
"typeVersion": 1
},
{
"id": "6b4acc67-8681-46b9-9ae4-973274e2c2a3",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
1296,
-576
],
"parameters": {
"width": 560,
"height": 656,
"content": "TEAM NOTIFICATIONS\nSends course details to Slack channel.\n\nFeatures:\n- Course summary with module count\n- First module preview\n- Completion notifications\n- Error alerts if needed\n\nChannels: Configure your preferred Slack channels\n\n**Note**: This is optional step and can be disabled. When disabling, disable both Slack notification nodes."
},
"typeVersion": 1
},
{
"id": "bd6f3caf-736a-4ef3-a3a9-4c9a98a552d7",
"name": "Slack Course Details",
"type": "n8n-nodes-base.slack",
"position": [
1536,
-272
],
"webhookId": "88b71c18-bb46-4fc1-a464-c33f5da4505e",
"parameters": {
"text": "=🎉 *New Micro-Learning Course Created!*📊 \n**Course Details**: \nCourse ID: {{ $('Format_Output').item.json.course_id }}\nTotal Modules: {{ $('Format_Output').item.json.total_modules }}\nTotal Estimated Time: {{ $('Format_Output').item.json.estimated_total_time }}\n",
"select": "channel",
"channelId": {
"__rl": true,
"mode": "list",
"value": "C0963H18JCX",
"cachedResultName": "all-mytest2025"
},
"otherOptions": {
"mrkdwn": true
}
},
"credentials": {
"slackApi": {
"id": "TjO2nAExXHrUpUIC",
"name": "Slack account"
}
},
"executeOnce": true,
"typeVersion": 2
},
{
"id": "f3f9b3fb-662d-466d-9961-91dd57622eb7",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
1728,
496
],
"parameters": {
"width": 480,
"height": 432,
"content": "# CREATE GOOGLE DOC\n\nPurpose of these nodes is to create a Google Doc and then update the created doc with the generated Google Doc content.\n\n**Update** the Google Doc credentials and the folder where the document should be created."
},
"typeVersion": 1
}
],
"active": true,
"pinData": {},
"settings": {
"executionOrder": "v1",
"saveManualExecutions": true,
"saveExecutionProgress": true,
"saveDataErrorExecution": "all",
"saveDataSuccessExecution": "all"
},
"versionId": "b2e4b490-199e-48e5-8c70-6311cd94c066",
"connections": {
"Merge": {
"main": [
[
{
"node": "Create a document",
"type": "main",
"index": 0
}
]
]
},
"Chunker": {
"main": [
[
{
"node": "AI Content Analyzer",
"type": "main",
"index": 0
}
]
]
},
"Split Out": {
"main": [
[
{
"node": "Google Formatter",
"type": "main",
"index": 0
},
{
"node": "Slack Modules",
"type": "main",
"index": 0
},
{
"node": "Slack Course Details",
"type": "main",
"index": 0
}
]
]
},
"Edit Fields": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 1
}
]
]
},
"Content Input": {
"main": [
[
{
"node": "Extract Content",
"type": "main",
"index": 0
}
]
]
},
"Format_Output": {
"main": [
[
{
"node": "Split Out",
"type": "main",
"index": 0
},
{
"node": "Edit Fields",
"type": "main",
"index": 0
}
]
]
},
"Slack Modules": {
"main": [
[
{
"node": "Success Response",
"type": "main",
"index": 0
}
]
]
},
"Error Response": {
"main": [
[
{
"node": "No Operation, do nothing1",
"type": "main",
"index": 0
}
]
]
},
"Extract Content": {
"main": [
[
{
"node": "Validate Content",
"type": "main",
"index": 0
}
]
]
},
"Google Formatter": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 0
}
]
]
},
"Success Response": {
"main": [
[]
]
},
"Validate Content": {
"main": [
[
{
"node": "Chunker",
"type": "main",
"index": 0
}
],
[
{
"node": "Error Response",
"type": "main",
"index": 0
}
]
]
},
"Create a document": {
"main": [
[
{
"node": "Update a document",
"type": "main",
"index": 0
}
]
]
},
"Update a document": {
"main": [
[
{
"node": "Success Response",
"type": "main",
"index": 0
}
]
]
},
"AI Content Analyzer": {
"main": [
[
{
"node": "Format_Output",
"type": "main",
"index": 0
}
]
]
},
"Slack Course Details": {
"main": [
[
{
"node": "No Operation, do nothing",
"type": "main",
"index": 0
}
]
]
}
}
}