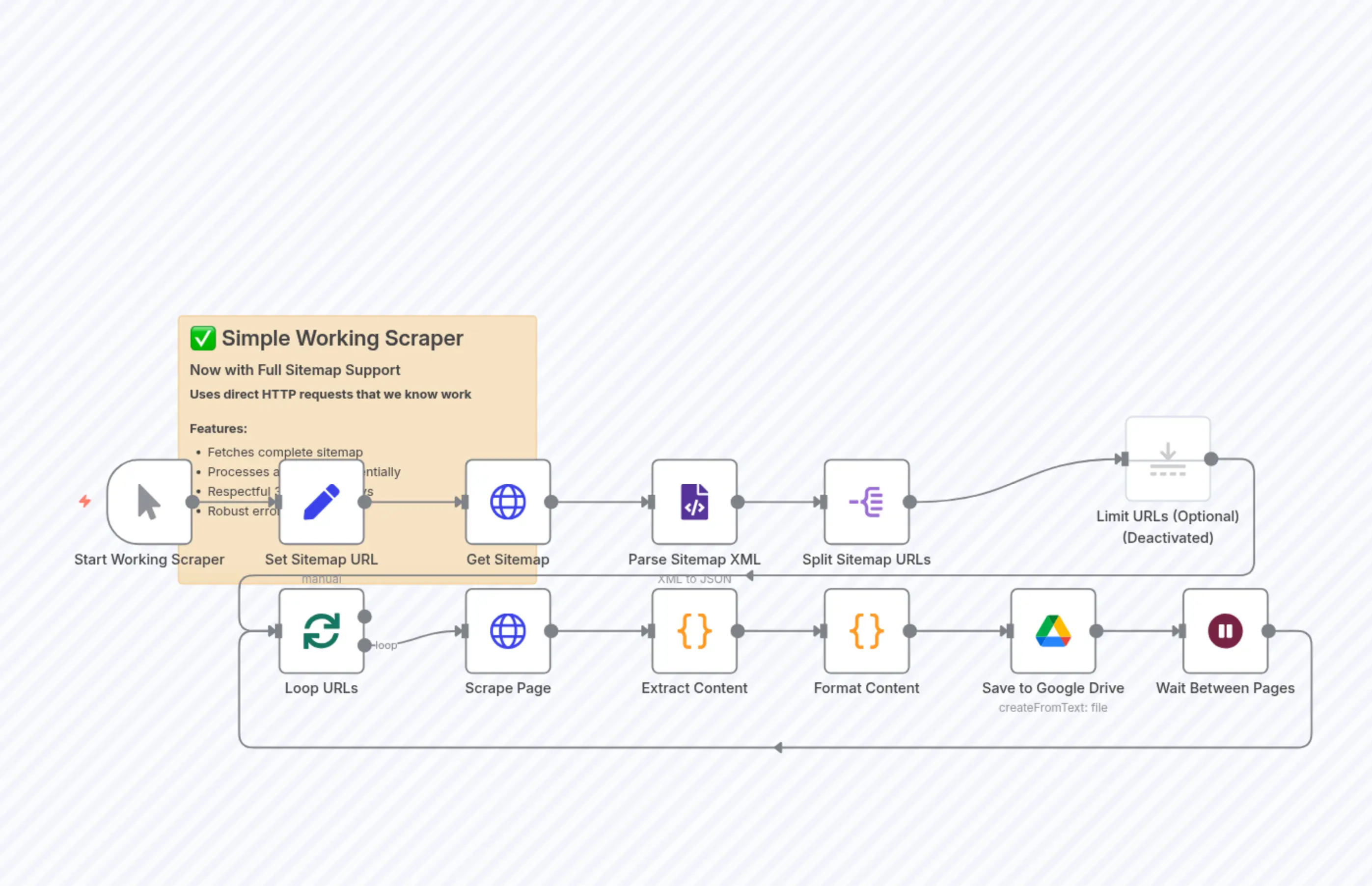
Simple Working Scraper
Description
Categories
📢 Marketing🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.setn8n-nodes-base.xmln8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.waitn8n-nodes-base.limitn8n-nodes-base.splitOutn8n-nodes-base.stickyNoten8n-nodes-base.googleDriven8n-nodes-base.httpRequest
PriceGratuit
Views0
Last Updated11/28/2025
workflow.json
{
"id": "YOUR_WORKFLOW_ID_HERE",
"meta": {
"instanceId": "YOUR_INSTANCE_ID_HERE"
},
"name": "Simple Working Scraper",
"tags": [],
"nodes": [
{
"id": "86320ce4-511d-4c6d-84c9-5e98de444130",
"name": "Working Scraper Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-304,
-32
],
"parameters": {
"color": 2,
"width": 400,
"height": 300,
"content": "## ✅ Simple Working Scraper\n### Now with Full Sitemap Support\n**Uses direct HTTP requests that we know work**\n\n**Features:**\n- Fetches complete sitemap\n- Processes all pages sequentially\n- Respectful 3-second delays\n- Robust error handling"
},
"typeVersion": 1
},
{
"id": "0d6bb0ea-4090-43ce-828f-f05b5571d2e8",
"name": "Start Working Scraper",
"type": "n8n-nodes-base.manualTrigger",
"position": [
-384,
128
],
"parameters": {},
"typeVersion": 1
},
{
"id": "3bee3b45-8b82-4017-bae3-fb1026fd9792",
"name": "Set Sitemap URL",
"type": "n8n-nodes-base.set",
"position": [
-192,
128
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "sitemap-url-id",
"name": "sitemap_url",
"type": "string",
"value": "https://yourwebsitehere.com/page-sitemap.xml"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "92a93278-e61b-4860-b0a6-73b2821dacbb",
"name": "Get Sitemap",
"type": "n8n-nodes-base.httpRequest",
"position": [
16,
128
],
"parameters": {
"url": "={{ $json.sitemap_url }}",
"options": {
"timeout": 15000,
"response": {
"response": {
"neverError": true
}
}
}
},
"typeVersion": 4.2
},
{
"id": "3aa79508-fe19-428b-91d8-77c1e7a7e012",
"name": "Parse Sitemap XML",
"type": "n8n-nodes-base.xml",
"position": [
224,
128
],
"parameters": {
"options": {}
},
"typeVersion": 1
},
{
"id": "f797b739-60eb-478e-b4d8-958dfe51b37a",
"name": "Split Sitemap URLs",
"type": "n8n-nodes-base.splitOut",
"position": [
416,
128
],
"parameters": {
"options": {},
"fieldToSplitOut": "urlset.url"
},
"typeVersion": 1
},
{
"id": "a311732e-68fa-4e96-989e-207565a499d5",
"name": "Limit URLs (Optional)",
"type": "n8n-nodes-base.limit",
"disabled": true,
"position": [
752,
80
],
"parameters": {
"maxItems": 20
},
"typeVersion": 1
},
{
"id": "cfb6df8a-a753-41c2-9983-22fea4bb0b2e",
"name": "Loop URLs",
"type": "n8n-nodes-base.splitInBatches",
"position": [
-192,
272
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "7ae29bfa-f197-447b-a5de-283db54aedf9",
"name": "Scrape Page",
"type": "n8n-nodes-base.httpRequest",
"position": [
16,
272
],
"parameters": {
"url": "={{ $json.loc }}",
"options": {
"timeout": 20000,
"response": {
"response": {
"neverError": true
}
}
},
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "User-Agent",
"value": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
},
{
"name": "Accept",
"value": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
},
{
"name": "Accept-Language",
"value": "en-US,en;q=0.9"
},
{
"name": "Accept-Encoding",
"value": "gzip, deflate, br"
},
{
"name": "Cache-Control",
"value": "no-cache"
},
{
"name": "Pragma",
"value": "no-cache"
}
]
}
},
"typeVersion": 4.2
},
{
"id": "4581c231-86ab-42ae-b57a-a9656a22cf1a",
"name": "Extract Content",
"type": "n8n-nodes-base.code",
"position": [
224,
272
],
"parameters": {
"jsCode": "// Extract content from HTML - handle all response types safely\nconst url = $('Loop URLs').item.json.loc;\nlet html = '';\nlet statusCode = 'Unknown';\n\n// Handle different response formats\nif (typeof $json === 'string') {\n html = $json;\n statusCode = 200; // Assume success if we got a string\n} else if ($json && $json.body) {\n html = $json.body;\n statusCode = $json.statusCode || 200;\n} else if ($json && typeof $json === 'object') {\n // Try to find HTML content in the object\n const possibleHtml = Object.values($json).find(val => \n typeof val === 'string' && (val.includes('<html') || val.includes('<div') || val.length > 100)\n );\n html = possibleHtml || '';\n statusCode = $json.statusCode || 'Unknown';\n}\n\nconsole.log('Processing URL:', url);\nconsole.log('Response type:', typeof $json);\nconsole.log('HTML length:', html ? html.length : 0);\nconsole.log('Status code:', statusCode);\n\nfunction extractTitle(html) {\n if (!html) return 'No Title';\n \n // Try multiple methods\n const titlePatterns = [\n /<title[^>]*>([^<]+)<\\/title>/i,\n /<meta[^>]*property=[\"']og:title[\"'][^>]*content=[\"']([^\"']+)[\"']/i,\n /<h1[^>]*>([^<]+)<\\/h1>/i\n ];\n \n for (const pattern of titlePatterns) {\n const match = html.match(pattern);\n if (match && match[1]) {\n return match[1].trim().replace(/\\s+/g, ' ');\n }\n }\n \n return 'Untitled Page';\n}\n\nfunction extractContent(html) {\n if (!html) return 'No content available';\n \n // Remove scripts, styles, and comments\n let content = html\n .replace(/<script[^>]*>[\\s\\S]*?<\\/script>/gi, '')\n .replace(/<style[^>]*>[\\s\\S]*?<\\/style>/gi, '')\n .replace(/<!--[\\s\\S]*?-->/g, '')\n .replace(/<noscript[^>]*>[\\s\\S]*?<\\/noscript>/gi, '');\n \n // Convert HTML to readable text\n content = content\n .replace(/<h[1-6][^>]*>([^<]+)<\\/h[1-6]>/gi, '\\n\\n## $1\\n\\n')\n .replace(/<p[^>]*>([^<]+)<\\/p>/gi, '\\n\\n$1\\n\\n')\n .replace(/<br\\s*\\/?>/gi, '\\n')\n .replace(/<div[^>]*>([^<]*)<\\/div>/gi, '\\n$1\\n')\n .replace(/<a[^>]*href=[\"']([^\"']*)[\"'][^>]*>([^<]+)<\\/a>/gi, '$2 [$1]')\n .replace(/<li[^>]*>([^<]+)<\\/li>/gi, '\\n• $1')\n .replace(/<[^>]+>/g, ' ')\n .replace(/\\s+/g, ' ')\n .replace(/\\n\\s+/g, '\\n')\n .replace(/\\s+\\n/g, '\\n')\n .replace(/\\n{3,}/g, '\\n\\n')\n .trim();\n \n return content || 'No readable content found';\n}\n\nconst title = extractTitle(html);\nconst content = extractContent(html);\nconst wordCount = content.split(/\\s+/).filter(w => w.length > 0).length;\n\n// Check for framework indicators\nconst isDivi = html.toLowerCase().includes('divi') || html.includes('et_pb_');\nconst isWordPress = html.toLowerCase().includes('wp-') || html.includes('wp_');\nconst hasJavaScript = html.includes('<script');\n\nreturn {\n url: url,\n title: title,\n content: content,\n wordCount: wordCount,\n htmlLength: html.length,\n statusCode: statusCode,\n isDivi: isDivi,\n isWordPress: isWordPress,\n hasJavaScript: hasJavaScript,\n timestamp: new Date().toISOString(),\n success: html.length > 0\n};"
},
"typeVersion": 2
},
{
"id": "f48d870e-9566-4b7c-bd8d-f1b3cb310325",
"name": "Format Content",
"type": "n8n-nodes-base.code",
"position": [
416,
272
],
"parameters": {
"jsCode": "// Format content for Google Drive\nconst data = $json;\n\nif (!data.success) {\n return {\n title: 'Scraping Failed',\n formatted: `# Scraping Failed\\n\\n**URL:** ${data.url}\\n**Error:** No content retrieved\\n**Status Code:** ${data.statusCode}\\n**Timestamp:** ${data.timestamp}\\n\\nThe page may be JavaScript-dependent or blocking automated requests.`\n };\n}\n\nconst sections = [];\n\n// YAML frontmatter\nsections.push('---');\nsections.push(`title: \"${data.title.replace(/\"/g, '\\\\\"')}\"`); \nsections.push(`url: ${data.url}`);\nsections.push(`scraped_at: ${data.timestamp}`);\nsections.push(`word_count: ${data.wordCount}`);\nsections.push(`html_length: ${data.htmlLength}`);\nsections.push(`status_code: ${data.statusCode}`);\nsections.push(`is_divi: ${data.isDivi}`);\nsections.push(`is_wordpress: ${data.isWordPress}`);\nsections.push(`has_javascript: ${data.hasJavaScript}`);\nsections.push('scraper_type: \"simple_direct_sitemap\"');\nsections.push('---');\nsections.push('');\n\n// Main content\nsections.push(`# ${data.title}`);\nsections.push('');\nsections.push(`**Source URL:** ${data.url}`);\nsections.push(`**Scraped:** ${new Date(data.timestamp).toLocaleString()}`);\nsections.push(`**Word Count:** ${data.wordCount.toLocaleString()}`);\nsections.push(`**HTML Size:** ${data.htmlLength.toLocaleString()} characters`);\nsections.push(`**Status Code:** ${data.statusCode}`);\nsections.push('');\n\nif (data.isDivi) {\n sections.push('🎨 **Divi Theme Detected** - This WordPress site uses dynamic content loading');\n sections.push('');\n}\n\nif (data.hasJavaScript && data.wordCount < 100) {\n sections.push('⚠️ **Limited Content** - This page likely requires JavaScript rendering for full content');\n sections.push('');\n}\n\nsections.push('---');\nsections.push('');\nsections.push('## Content');\nsections.push('');\n\nif (data.content && data.content !== 'No readable content found') {\n sections.push(data.content);\n} else {\n sections.push('*No readable content could be extracted from this page.*');\n sections.push('');\n sections.push('**Possible reasons:**');\n sections.push('- Page content is loaded dynamically with JavaScript');\n sections.push('- Site has anti-bot protection');\n sections.push('- Content is behind authentication');\n sections.push('- Page structure is complex or non-standard');\n}\n\nsections.push('');\nsections.push('---');\nsections.push('');\nsections.push('**Technical Details:**');\nsections.push(`- Framework detected: ${data.isDivi ? 'Divi' : (data.isWordPress ? 'WordPress' : 'Unknown')}`);\nsections.push(`- JavaScript present: ${data.hasJavaScript ? 'Yes' : 'No'}`);\nsections.push(`- Content extraction: ${data.wordCount > 50 ? 'Successful' : 'Limited'}`);\nsections.push('');\nsections.push('*Scraped with n8n Simple Working Scraper (Full Sitemap)*');\n\nreturn {\n title: data.title,\n formatted: sections.join('\\n')\n};"
},
"typeVersion": 2
},
{
"id": "306d986f-6e37-4726-a17d-64f867d51d3e",
"name": "Save to Google Drive",
"type": "n8n-nodes-base.googleDrive",
"position": [
624,
272
],
"parameters": {
"name": "={{ $('Loop URLs').item.json.loc.replace(/https?:\\/\\//, '').replace(/\\//g, '_') }}_sitemap.md",
"content": "={{ $json.formatted }}",
"driveId": {
"__rl": true,
"mode": "list",
"value": "My Drive"
},
"options": {},
"folderId": {
"__rl": true,
"mode": "list",
"value": "YOUR_GOOGLE_DRIVE_FOLDER_ID_HERE",
"cachedResultUrl": "https://drive.google.com/drive/folders/YOUR_GOOGLE_DRIVE_FOLDER_ID_HERE",
"cachedResultName": "YOUR_FOLDER_NAME_HERE"
},
"operation": "createFromText"
},
"credentials": {
"googleDriveOAuth2Api": {
"id": "YOUR_GOOGLE_DRIVE_CREDENTIAL_ID",
"name": "Google Drive account"
}
},
"typeVersion": 3
},
{
"id": "e62e8040-db5c-4a59-8b31-c589aa2c7d0e",
"name": "Wait Between Pages",
"type": "n8n-nodes-base.wait",
"position": [
816,
272
],
"webhookId": "YOUR_WEBHOOK_ID_HERE",
"parameters": {
"amount": 3
},
"typeVersion": 1.1
}
],
"active": false,
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"versionId": "YOUR_VERSION_ID_HERE",
"connections": {
"Loop URLs": {
"main": [
[],
[
{
"node": "Scrape Page",
"type": "main",
"index": 0
}
]
]
},
"Get Sitemap": {
"main": [
[
{
"node": "Parse Sitemap XML",
"type": "main",
"index": 0
}
]
]
},
"Scrape Page": {
"main": [
[
{
"node": "Extract Content",
"type": "main",
"index": 0
}
]
]
},
"Format Content": {
"main": [
[
{
"node": "Save to Google Drive",
"type": "main",
"index": 0
}
]
]
},
"Extract Content": {
"main": [
[
{
"node": "Format Content",
"type": "main",
"index": 0
}
]
]
},
"Set Sitemap URL": {
"main": [
[
{
"node": "Get Sitemap",
"type": "main",
"index": 0
}
]
]
},
"Parse Sitemap XML": {
"main": [
[
{
"node": "Split Sitemap URLs",
"type": "main",
"index": 0
}
]
]
},
"Split Sitemap URLs": {
"main": [
[
{
"node": "Limit URLs (Optional)",
"type": "main",
"index": 0
}
]
]
},
"Wait Between Pages": {
"main": [
[
{
"node": "Loop URLs",
"type": "main",
"index": 0
}
]
]
},
"Save to Google Drive": {
"main": [
[
{
"node": "Wait Between Pages",
"type": "main",
"index": 0
}
]
]
},
"Limit URLs (Optional)": {
"main": [
[
{
"node": "Loop URLs",
"type": "main",
"index": 0
}
]
]
},
"Start Working Scraper": {
"main": [
[
{
"node": "Set Sitemap URL",
"type": "main",
"index": 0
}
]
]
}
}
}