AI-Powered RAG Document Processing & Chatbot with Google Drive, Supabase, OpenAI
Description
Categories
🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.setn8n-nodes-base.setn8n-nodes-base.coden8n-nodes-base.limitn8n-nodes-base.switchn8n-nodes-base.splitOutn8n-nodes-base.summarizen8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNote
PriceGratis
Views1
Last Updated1/26/2026
workflow.json
{
"meta": {
"instanceId": "d1786ab0d745a7498abf13a9c2cdabb1374c006e889b79eef64ce0386b8f8a41",
"templateCredsSetupCompleted": true
},
"nodes": [
{
"id": "f13af0a4-02e8-41b4-9ad8-55443604f031",
"name": "Loop Over Items",
"type": "n8n-nodes-base.splitInBatches",
"position": [
540,
-80
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "3a3a9bee-fd2c-48fb-a946-850bdd574b21",
"name": "Extract from PDF",
"type": "n8n-nodes-base.extractFromFile",
"position": [
1720,
-120
],
"parameters": {
"options": {},
"operation": "pdf"
},
"typeVersion": 1
},
{
"id": "42a44446-4cd9-4b8f-bcc8-dc912954e515",
"name": "Extract from CSV",
"type": "n8n-nodes-base.extractFromFile",
"position": [
1720,
80
],
"parameters": {
"options": {}
},
"typeVersion": 1
},
{
"id": "2141dbdd-4fce-4306-a852-581b138864e4",
"name": "Default Data Loader",
"type": "@n8n/n8n-nodes-langchain.documentDefaultDataLoader",
"position": [
3800,
80
],
"parameters": {
"options": {
"metadata": {
"metadataValues": [
{
"name": "file_id",
"value": "={{ $('Set File ID').first().json.file_id}}"
},
{
"name": "title",
"value": "={{ $('Create Metadata Title & Description').item.json.output.title }}"
},
{
"name": "description",
"value": "={{ $('Create Metadata Title & Description').item.json.output.description }}"
}
]
}
},
"jsonData": "={{ $json.concatenated_text }}",
"jsonMode": "expressionData"
},
"typeVersion": 1
},
{
"id": "af8b85b1-1cfa-4b76-b94e-48213ae232d8",
"name": "Google Drive Trigger File Created",
"type": "n8n-nodes-base.googleDriveTrigger",
"position": [
280,
-80
],
"parameters": {
"event": "fileCreated",
"options": {},
"pollTimes": {
"item": [
{
"mode": "everyMinute"
}
]
},
"triggerOn": "specificFolder",
"folderToWatch": {
"__rl": true,
"mode": "url",
"value": "https://drive.google.com/drive/u/0/folders/1B-Wl-ktVFbTmX685DB978jNvs9Ihnxiv"
}
},
"credentials": {
"googleDriveOAuth2Api": {
"id": "SEUhrgz30NMJS3cH",
"name": "Google Drive account"
}
},
"typeVersion": 1
},
{
"id": "97304af3-3a09-4724-8e87-7fff0ece6eca",
"name": "Character Text Splitter",
"type": "@n8n/n8n-nodes-langchain.textSplitterCharacterTextSplitter",
"position": [
3900,
260
],
"parameters": {
"separator": "###SPLIT###"
},
"typeVersion": 1
},
{
"id": "af31206c-94e6-48fe-895e-f8a000486457",
"name": "Set File ID",
"type": "n8n-nodes-base.set",
"position": [
800,
-60
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "0144a9a7-6e73-46c4-979f-838ad5c62b89",
"name": "file_id",
"type": "string",
"value": "={{ $json.id }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "580b1192-be67-46f1-aea4-ae1aaeab10ea",
"name": "Download FIle",
"type": "n8n-nodes-base.googleDrive",
"position": [
1040,
-60
],
"parameters": {
"fileId": {
"__rl": true,
"mode": "id",
"value": "={{ $('Set File ID').item.json.file_id }}"
},
"options": {
"googleFileConversion": {
"conversion": {
"docsToFormat": "application/pdf"
}
}
},
"operation": "download"
},
"credentials": {
"googleDriveOAuth2Api": {
"id": "SEUhrgz30NMJS3cH",
"name": "Google Drive account"
}
},
"typeVersion": 3
},
{
"id": "af92c035-f1f0-47e4-b542-c13a7386892b",
"name": "Switch",
"type": "n8n-nodes-base.switch",
"position": [
1320,
-60
],
"parameters": {
"rules": {
"values": [
{
"outputKey": "application/pdf",
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "e959d5a8-d311-4a29-b400-7c07468a72fe",
"operator": {
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $binary.data.mimeType }}",
"rightValue": "application/pdf"
}
]
},
"renameOutput": true
},
{
"outputKey": "text/csv",
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "d5ae6f2d-e62d-4e08-aa06-629e6dfa7ee8",
"operator": {
"name": "filter.operator.equals",
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $binary.data.mimeType }}",
"rightValue": "text/csv"
}
]
},
"renameOutput": true
}
]
},
"options": {}
},
"typeVersion": 3.2
},
{
"id": "1a2575ef-8792-4389-84ea-a016c5ba535e",
"name": "Structured Output Parser",
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"position": [
2540,
160
],
"parameters": {
"jsonSchemaExample": "{\n\t\"title\": \"Test Title (Replace it with real title\",\n \"description\":\"Test Description (Replace it with real description)\"\n}"
},
"typeVersion": 1.2
},
{
"id": "0c8ba080-daab-493d-8c7d-4f1c7e9fb1e7",
"name": "Google Gemini Chat Model",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
3320,
40
],
"parameters": {
"options": {},
"modelName": "models/gemini-1.5-flash"
},
"credentials": {
"googlePalmApi": {
"id": "gdaO8lU3HwsldifM",
"name": "Google Gemini(PaLM) Api account"
}
},
"typeVersion": 1
},
{
"id": "e12a0a90-a1d7-4de0-901a-58ce35b95675",
"name": "Process Context",
"type": "@n8n/n8n-nodes-langchain.chainLlm",
"position": [
3160,
-120
],
"parameters": {
"text": "=<document> \n{{ $('Document Data').first().json.data }}\n</document> \n\nHere is the chunk we want to situate within the overall document:\n\n<chunk> \n{{ $json.chunk }}\n</chunk> \n\nPlease:\n- Provide a short and succinct **context** to situate this chunk within the document for improved search retrieval.\n- Return the **original chunk** exactly as provided unless a correction is necessary.\n- If the chunk contains an **incomplete number, percentage, or entity**, correct it using the full document.\n- If part of a **sentence is cut off**, reconstruct the missing words only if necessary for clarity.\n- If the chunk is part of a table, include the complete table entry to maintain data integrity\n- Do not add any additional explanations or formatting beyond the required output.\n\nFill in the following format:\n[succinct context] : [original chunk or corrected version if necessary]\n\nYour response should contain only the text that replaces these placeholders, without including the placeholder labels themselves.",
"promptType": "define"
},
"typeVersion": 1.6
},
{
"id": "d6f500ba-c0f3-4cc8-af60-e2c38307582c",
"name": "Document Data",
"type": "n8n-nodes-base.set",
"position": [
1980,
-120
],
"parameters": {
"mode": "raw",
"options": {},
"jsonOutput": "={\n \"data\": {{ JSON.stringify($json.text) }}\n} "
},
"typeVersion": 3.4
},
{
"id": "de223e76-1d95-41a9-b1ff-961d8b744044",
"name": "Split Out",
"type": "n8n-nodes-base.splitOut",
"position": [
2780,
-120
],
"parameters": {
"options": {
"destinationFieldName": "chunk"
},
"fieldToSplitOut": "chunks"
},
"typeVersion": 1
},
{
"id": "7d2eb334-a73c-4777-b4a9-757356201311",
"name": "Limit",
"type": "n8n-nodes-base.limit",
"position": [
2960,
-120
],
"parameters": {
"maxItems": 20
},
"typeVersion": 1
},
{
"id": "d8f88a96-bed6-461a-ae5f-6924c655ba84",
"name": "Summarize",
"type": "n8n-nodes-base.summarize",
"position": [
3480,
-120
],
"parameters": {
"options": {},
"fieldsToSummarize": {
"values": [
{
"field": "text",
"separateBy": "other",
"aggregation": "concatenate",
"customSeparator": "###SPLIT###"
}
]
}
},
"typeVersion": 1.1
},
{
"id": "820dda10-a369-4415-a739-16f197d0b1ad",
"name": "Embeddings OpenAI",
"type": "@n8n/n8n-nodes-langchain.embeddingsOpenAi",
"position": [
3680,
80
],
"parameters": {
"options": {}
},
"credentials": {
"openAiApi": {
"id": "MGwGMKEkdcjzlYCw",
"name": "OpenAi account"
}
},
"typeVersion": 1.2
},
{
"id": "1a622d78-d5f1-498d-8882-1cbc9166e4b4",
"name": "Add Data to Supabase Vector Store",
"type": "@n8n/n8n-nodes-langchain.vectorStoreSupabase",
"position": [
3680,
-120
],
"parameters": {
"mode": "insert",
"options": {},
"tableName": {
"__rl": true,
"mode": "list",
"value": "documents",
"cachedResultName": "documents"
}
},
"credentials": {
"supabaseApi": {
"id": "XijKo1j1EsG3XUhz",
"name": "Supabase account"
}
},
"typeVersion": 1.1
},
{
"id": "51d8e196-8752-4fe7-a182-c4a00d3caefa",
"name": "Google Gemini Chat Model1",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
2340,
180
],
"parameters": {
"options": {},
"modelName": "models/gemini-1.5-flash"
},
"credentials": {
"googlePalmApi": {
"id": "gdaO8lU3HwsldifM",
"name": "Google Gemini(PaLM) Api account"
}
},
"typeVersion": 1
},
{
"id": "23b491e1-3732-46eb-a62b-c86b975df894",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
200,
-260
],
"parameters": {
"color": 4,
"width": 1960,
"height": 560,
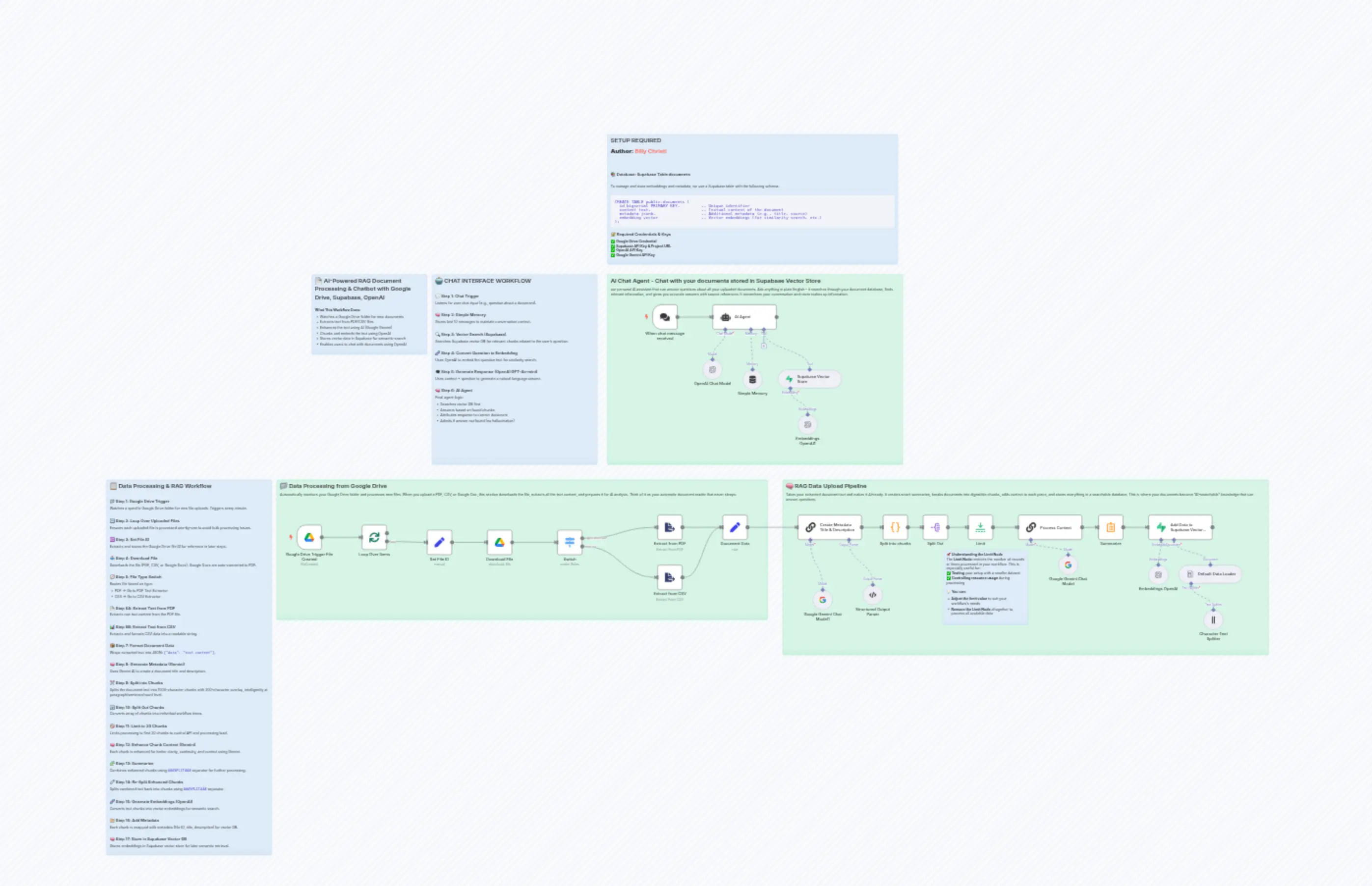
"content": "## 📁 Data Processing from Google Drive\nAutomatically monitors your Google Drive folder and processes new files. When you upload a PDF, CSV, or Google Doc, this section downloads the file, extracts all the text content, and prepares it for AI analysis. Think of it as your automatic document reader that never sleeps."
},
"typeVersion": 1
},
{
"id": "5d95cc1c-5dec-4238-8ecc-d47d5c107e53",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
2220,
-260
],
"parameters": {
"color": 4,
"width": 1940,
"height": 700,
"content": "## 🧠 RAG Data Upload Pipeline\nTakes your extracted document text and makes it AI-ready. It creates smart summaries, breaks documents into digestible chunks, adds context to each piece, and stores everything in a searchable database. This is where your documents become \"AI-searchable\" knowledge that can answer questions."
},
"typeVersion": 1
},
{
"id": "d5ab29ee-d9a6-48c6-a2d5-20374cda6296",
"name": "Create Metadata Title & Description",
"type": "@n8n/n8n-nodes-langchain.chainLlm",
"position": [
2280,
-120
],
"parameters": {
"text": "=Create metadata title and metadata description based on the document specified below (below ##Document). Metadata title and metadata description will be used to seperate data in vector DB that will be used for RAG.\n\n##Document\n{{ $('Document Data').item.json.data }}",
"promptType": "define",
"hasOutputParser": true
},
"typeVersion": 1.6
},
{
"id": "8eddba99-f77b-4b85-b2ef-0aa68762b851",
"name": "Split into chunks",
"type": "n8n-nodes-base.code",
"position": [
2620,
-120
],
"parameters": {
"jsCode": "const chunkSize = 1000;\nconst chunkOverlap = 200;\n//const text = $node[\"ABC\"].json.data.replace(/\\n/, '');\nconst text = $items(\"Document Data\")[0].json.data.replace(/\\n/, '');\n\nconst chunks = [];\nlet remainingText = text;\n\nwhile (remainingText.length > 0) {\n let splitPoint;\n\n // Try splitting at paragraph level first\n splitPoint = remainingText.lastIndexOf(\"\\n\\n\", chunkSize);\n \n // If no paragraph split, try splitting at sentence level\n if (splitPoint === -1) {\n splitPoint = remainingText.lastIndexOf(\". \", chunkSize);\n }\n\n // If no sentence split, try splitting at word level\n if (splitPoint === -1) {\n splitPoint = remainingText.lastIndexOf(\" \", chunkSize);\n }\n\n // If still no split point, force cut at chunkSize\n if (splitPoint === -1 || splitPoint < chunkSize * 0.5) { \n splitPoint = chunkSize; // Hard split if no good split point\n }\n\n // Extract chunk and adjust remaining text with overlap\n let chunk = remainingText.substring(0, splitPoint).trim();\n chunks.push(chunk);\n\n // Move the pointer forward while keeping the overlap\n remainingText = remainingText.substring(Math.max(0, splitPoint - chunkOverlap)).trim();\n\n // Break if remaining text is too small to form another chunk\n if (remainingText.length < chunkSize * 0.2) {\n chunks.push(remainingText);\n break;\n }\n}\n\nreturn { chunks };"
},
"typeVersion": 2
},
{
"id": "2cd80097-3f90-441a-b0ef-08b43c30981b",
"name": "OpenAI Chat Model",
"type": "@n8n/n8n-nodes-langchain.lmChatOpenAi",
"position": [
1900,
-740
],
"parameters": {
"model": {
"__rl": true,
"mode": "list",
"value": "gpt-4o-mini"
},
"options": {}
},
"credentials": {
"openAiApi": {
"id": "MGwGMKEkdcjzlYCw",
"name": "OpenAi account"
}
},
"typeVersion": 1.2
},
{
"id": "03ae06b7-c804-4e35-bac5-17836123771a",
"name": "Supabase Vector Store",
"type": "@n8n/n8n-nodes-langchain.vectorStoreSupabase",
"position": [
2200,
-700
],
"parameters": {
"mode": "retrieve-as-tool",
"topK": 20,
"options": {},
"toolName": "documents",
"tableName": {
"__rl": true,
"mode": "list",
"value": "documents",
"cachedResultName": "documents"
},
"toolDescription": "Work with your data in Supabase Vector Store"
},
"credentials": {
"supabaseApi": {
"id": "XijKo1j1EsG3XUhz",
"name": "Supabase account"
}
},
"typeVersion": 1.1
},
{
"id": "c22f1100-86b0-4d49-b0b5-baa3f997c0a0",
"name": "AI Agent",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
1940,
-960
],
"parameters": {
"text": "=User Input:\n{{ $json.chatInput }}",
"options": {
"systemMessage": "=You're an internal company knowledge assistants. Your job is to answer questions using the files in the Vector Database. Here's how to do it:\n\nCheck Vector Database First\n- Search for similar test chunks using RAG.\n- If you find matches, use them to answer the question. \n- If you find relevant matches and need additional context to support the answer, prioritize retrieving it from documents that share the same metadata \"file_id\" & \"title\" before exploring other sources.\"\n\nNo Answer Found?\n- Clearly say: \"I couldn't find this in the databases\"\n- Never guess or invent answers.\n\nExample Response:\n\"Netflix grew revenue in Streaming services by 20% in 2024.\""
},
"promptType": "define"
},
"typeVersion": 1.8
},
{
"id": "8ff3b246-2078-4c69-934a-fde989c5dbda",
"name": "Embeddings OpenAI1",
"type": "@n8n/n8n-nodes-langchain.embeddingsOpenAi",
"position": [
2280,
-520
],
"parameters": {
"options": {}
},
"credentials": {
"openAiApi": {
"id": "MGwGMKEkdcjzlYCw",
"name": "OpenAi account"
}
},
"typeVersion": 1.2
},
{
"id": "4fc4edb9-b5a1-4d4b-b571-cf665cf4eae1",
"name": "When chat message received",
"type": "@n8n/n8n-nodes-langchain.chatTrigger",
"position": [
1700,
-960
],
"webhookId": "2d4c41cb-c8b7-49c7-a8eb-ebd3dd9ff46d",
"parameters": {
"options": {}
},
"typeVersion": 1.1
},
{
"id": "3fc29837-d177-4af0-a842-57705ef8b97d",
"name": "Simple Memory",
"type": "@n8n/n8n-nodes-langchain.memoryBufferWindow",
"position": [
2060,
-700
],
"parameters": {
"contextWindowLength": 10
},
"typeVersion": 1.3
},
{
"id": "27ca3852-baac-41fa-a8bc-620dd36fac2d",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
1520,
-1080
],
"parameters": {
"color": 4,
"width": 1180,
"height": 760,
"content": "## AI Chat Agent - Chat with your documents stored in Supabase Vector Store\nour personal AI assistant that can answer questions about all your uploaded documents. Ask anything in plain English - it searches through your document database, finds relevant information, and gives you accurate answers with source references. It remembers your conversation and never makes up information."
},
"typeVersion": 1
},
{
"id": "ee2b6e9d-a49b-435e-bc38-7d3a4e989ca5",
"name": "Sticky Note7",
"type": "n8n-nodes-base.stickyNote",
"position": [
340,
-1080
],
"parameters": {
"color": 5,
"width": 460,
"height": 320,
"content": "## 📄 AI-Powered RAG Document Processing & Chatbot with Google Drive, Supabase, OpenAI\n\n**What This Workflow Does:**\n- Watches a Google Drive folder for new documents\n- Extracts text from PDF/CSV files\n- Enhances the text using AI (Google Gemini)\n- Chunks and embeds the text using OpenAI\n- Stores vector data in Supabase for semantic search\n- Enables users to chat with documents using OpenAI"
},
"typeVersion": 1
},
{
"id": "f533c790-36d0-4f7e-a004-1ab64fdbd046",
"name": "Sticky Note8",
"type": "n8n-nodes-base.stickyNote",
"position": [
-480,
-260
],
"parameters": {
"color": 5,
"width": 660,
"height": 1500,
"content": "## 📋 Data Processing & RAG Workflow\n\n### 📁 Step 1: Google Drive Trigger \nWatches a specific Google Drive folder for new file uploads. Triggers every minute.\n\n### 🔁 Step 2: Loop Over Uploaded Files \nEnsures each uploaded file is processed one-by-one to avoid bulk processing issues.\n\n### 🆔 Step 3: Set File ID \nExtracts and stores the Google Drive file ID for reference in later steps.\n\n### 📥 Step 4: Download File \nDownloads the file (PDF, CSV, or Google Docs). Google Docs are auto-converted to PDF.\n\n### 🧭 Step 5: File Type Switch \nRoutes file based on type:\n- PDF → Go to PDF Text Extractor\n- CSV → Go to CSV Extractor\n\n### 📄 Step 6A: Extract Text from PDF \nExtracts raw text content from the PDF file.\n\n### 📊 Step 6B: Extract Text from CSV \nExtracts and formats CSV data into a readable string.\n\n### 📦 Step 7: Format Document Data \nWraps extracted text into JSON: `{\"data\": \"text content\"}`.\n\n### 🧠 Step 8: Generate Metadata (Gemini) \nUses Gemini AI to create a document title and description.\n\n### ✂️ Step 9: Split into Chunks \nSplits the document text into 1000-character chunks with 200-character overlap, intelligently at paragraph/sentence/word level.\n\n### 🔄 Step 10: Split Out Chunks \nConverts array of chunks into individual workflow items.\n\n### 🚫 Step 11: Limit to 20 Chunks \nLimits processing to first 20 chunks to control API and processing load.\n\n### 🧠 Step 12: Enhance Chunk Context (Gemini) \nEach chunk is enhanced for better clarity, continuity, and context using Gemini.\n\n### 🧩 Step 13: Summarize \nCombines enhanced chunks using `###SPLIT###` separator for further processing.\n\n### 🧷 Step 14: Re-Split Enhanced Chunks \nSplits combined text back into chunks using `###SPLIT###` separator.\n\n### 🧬 Step 15: Generate Embeddings (OpenAI) \nConverts text chunks into vector embeddings for semantic search.\n\n### 🗂️ Step 16: Add Metadata \nEach chunk is wrapped with metadata (file ID, title, description) for vector DB.\n\n### 🧠 Step 17: Store in Supabase Vector DB \nStores embeddings in Supabase vector store for later semantic retrieval.\n\n"
},
"typeVersion": 1
},
{
"id": "2090caca-8fff-461b-a9b5-5460b8978c3c",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
1520,
-1640
],
"parameters": {
"color": 5,
"width": 1160,
"height": 520,
"content": "\n## SETUP REQUIRED \n**Author:** [Billy Christi](https://n8n.io/creators/billy/)\n\n---\n\n### 📚 Database: Supabase Table `documents`\n\nTo manage and store embeddings and metadata, we use a Supabase table with the following schema:\n\n```sql\nCREATE TABLE public.documents (\n id bigserial PRIMARY KEY, -- Unique identifier\n content text, -- Textual content of the document\n metadata jsonb, -- Additional metadata (e.g., title, source)\n embedding vector -- Vector embeddings (for similarity search, etc.)\n);\n````\n### 🔐 Required Credentials & Keys\n✅ **Google Drive Credential** \n✅ **Supabase API Key & Project URL** \n✅ **OpenAI API Key**\n✅ **Google Gemini API Key**\n\n\n"
},
"typeVersion": 1
},
{
"id": "989d4cef-fae3-4163-a51e-58cf9aafac61",
"name": "Sticky Note9",
"type": "n8n-nodes-base.stickyNote",
"position": [
820,
-1080
],
"parameters": {
"color": 5,
"width": 660,
"height": 760,
"content": "\n## 🤖 CHAT INTERFACE WORKFLOW\n\n### 💬 Step 1: Chat Trigger \nListens for user chat input (e.g., question about a document).\n\n### 🧠 Step 2: Simple Memory \nStores last 10 messages to maintain conversation context.\n\n### 🔍 Step 3: Vector Search (Supabase) \nSearches Supabase vector DB for relevant chunks related to the user's question.\n\n### 🧬 Step 4: Convert Question to Embedding \nUses OpenAI to embed the question text for similarity search.\n\n### 🗨️ Step 5: Generate Response (OpenAI GPT-4o-mini) \nUses context + question to generate a natural language answer.\n\n### 🧠 Step 6: AI Agent \nFinal agent logic:\n- Searches vector DB first\n- Answers based on found chunks\n- Attributes response to correct document\n- Admits if answer not found (no hallucination)"
},
"typeVersion": 1
},
{
"id": "8d2661d4-3bdc-456e-bba0-766d89ab3ece",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
2860,
20
],
"parameters": {
"color": 5,
"width": 340,
"height": 300,
"content": "📌 **Understanding the Limit Node**\nThe **Limit Node** restricts the number of records or items processed in your workflow. This is especially useful for:\n✅ **Testing** your setup with a smaller dataset\n✅ **Controlling resource usage** during processing\n\n💡 **You can**:\n* **Adjust the limit value** to suit your workflow's needs\n* **Remove the Limit Node** altogether to process all available data"
},
"typeVersion": 1
}
],
"pinData": {},
"connections": {
"Limit": {
"main": [
[
{
"node": "Process Context",
"type": "main",
"index": 0
}
]
]
},
"Switch": {
"main": [
[
{
"node": "Extract from PDF",
"type": "main",
"index": 0
}
],
[
{
"node": "Extract from CSV",
"type": "main",
"index": 0
}
]
]
},
"AI Agent": {
"main": [
[]
]
},
"Split Out": {
"main": [
[
{
"node": "Limit",
"type": "main",
"index": 0
}
]
]
},
"Summarize": {
"main": [
[
{
"node": "Add Data to Supabase Vector Store",
"type": "main",
"index": 0
}
]
]
},
"Set File ID": {
"main": [
[
{
"node": "Download FIle",
"type": "main",
"index": 0
}
]
]
},
"Document Data": {
"main": [
[
{
"node": "Create Metadata Title & Description",
"type": "main",
"index": 0
}
]
]
},
"Download FIle": {
"main": [
[
{
"node": "Switch",
"type": "main",
"index": 0
}
]
]
},
"Simple Memory": {
"ai_memory": [
[
{
"node": "AI Agent",
"type": "ai_memory",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[],
[
{
"node": "Set File ID",
"type": "main",
"index": 0
}
]
]
},
"Process Context": {
"main": [
[
{
"node": "Summarize",
"type": "main",
"index": 0
}
]
]
},
"Extract from CSV": {
"main": [
[
{
"node": "Document Data",
"type": "main",
"index": 0
}
]
]
},
"Extract from PDF": {
"main": [
[
{
"node": "Document Data",
"type": "main",
"index": 0
}
]
]
},
"Embeddings OpenAI": {
"ai_embedding": [
[
{
"node": "Add Data to Supabase Vector Store",
"type": "ai_embedding",
"index": 0
}
]
]
},
"OpenAI Chat Model": {
"ai_languageModel": [
[
{
"node": "AI Agent",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Split into chunks": {
"main": [
[
{
"node": "Split Out",
"type": "main",
"index": 0
}
]
]
},
"Embeddings OpenAI1": {
"ai_embedding": [
[
{
"node": "Supabase Vector Store",
"type": "ai_embedding",
"index": 0
}
]
]
},
"Default Data Loader": {
"ai_document": [
[
{
"node": "Add Data to Supabase Vector Store",
"type": "ai_document",
"index": 0
}
]
]
},
"Supabase Vector Store": {
"ai_tool": [
[
{
"node": "AI Agent",
"type": "ai_tool",
"index": 0
}
]
]
},
"Character Text Splitter": {
"ai_textSplitter": [
[
{
"node": "Default Data Loader",
"type": "ai_textSplitter",
"index": 0
}
]
]
},
"Google Gemini Chat Model": {
"ai_languageModel": [
[
{
"node": "Process Context",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Structured Output Parser": {
"ai_outputParser": [
[
{
"node": "Create Metadata Title & Description",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"Google Gemini Chat Model1": {
"ai_languageModel": [
[
{
"node": "Create Metadata Title & Description",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"When chat message received": {
"main": [
[
{
"node": "AI Agent",
"type": "main",
"index": 0
}
]
]
},
"Google Drive Trigger File Created": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Create Metadata Title & Description": {
"main": [
[
{
"node": "Split into chunks",
"type": "main",
"index": 0
}
]
]
}
}
}