X (Twitter) Brand Sentiment Analysis with Gemini AI & Slack Alerts
Description
Categories
⚙️ Automation
Nodes Used
n8n-nodes-base.ifn8n-nodes-base.setn8n-nodes-base.setn8n-nodes-base.setn8n-nodes-base.setn8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.code
PriceFree
Views0
Last Updated11/28/2025
workflow.json
{
"meta": {
"instanceId": "12b5738dbe70639f3b7d069a122c5f581ca4347fcd62ddef39ad5c33b40e7e5e",
"templateCredsSetupCompleted": true
},
"nodes": [
{
"id": "59dc116b-2c89-4dd0-a65d-707c9c19a7d0",
"name": "Code",
"type": "n8n-nodes-base.code",
"position": [
656,
-1104
],
"parameters": {
"jsCode": "// Get the input data from the first item\nconst inputData = items[0].json;\n\n// This will hold our final list of individual items\nconst outputItems = [];\n\nconst nextCursor = inputData.next_cursor;\n\n// Loop through each tweet in the 'tweets' array from the input\nfor (const tweet of inputData.tweets) {\n // 1. Create the clean object for a single tweet\n const cleanTweet = {\n id:tweet.id,\n text: tweet.text,\n url: tweet.url,\n authorUsername: tweet.author.userName,\n authorName: tweet.author.name,\n createdAt: tweet.createdAt,\n likeCount: tweet.likeCount,\n retweetCount: tweet.retweetCount,\n replyCount: tweet.replyCount,\n quoteCount: tweet.quoteCount,\n viewCount: tweet.viewCount,\n isReply: tweet.isReply,\n nextCursor: nextCursor \n };\n\n if (tweet.isReply) {\n cleanTweet.inReplyToUsername = tweet.inReplyToUsername;\n cleanTweet.inReplyToId = tweet.inReplyToId;\n }\n\n // 2. Wrap this single tweet object in the required N8N item structure\n const n8nItem = {\n json: cleanTweet\n };\n\n // 3. Add this new item to our output list\n outputItems.push(n8nItem);\n}\n\n// Return the array of individual items\nreturn outputItems;"
},
"typeVersion": 2
},
{
"id": "4a4011b2-34e4-460d-aeaa-16f7d268387e",
"name": "Append row in sheet",
"type": "n8n-nodes-base.googleSheets",
"position": [
880,
-1104
],
"parameters": {
"columns": {
"value": {
"URL": "={{ $json.url }}",
"Date": "={{ $json.createdAt }}",
"Likes": "={{ $json.likeCount }}",
"Views": "={{ $json.viewCount }}",
"Quotes": "={{ $json.quoteCount }}",
"Content": "={{ $json.text }}",
"Replies": "={{ $json.replyCount }}",
"isreply": "={{ $json.isReply }}",
"Retweets": "={{ $json.retweetCount }}",
"Tweet_ID": "={{ $json.id }}",
"Author_Name": "={{ $json.authorName }}",
"next_cursor": "={{ $json.nextCursor }}",
"Author_Username": "={{ $json.authorUsername }}"
},
"schema": [
{
"id": "Tweet_ID",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "Tweet_ID",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "URL",
"type": "string",
"display": true,
"required": false,
"displayName": "URL",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Content",
"type": "string",
"display": true,
"required": false,
"displayName": "Content",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Author_Username",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "Author_Username",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Author_Name",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "Author_Name",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Likes",
"type": "string",
"display": true,
"required": false,
"displayName": "Likes",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Views",
"type": "string",
"display": true,
"required": false,
"displayName": "Views",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Retweets",
"type": "string",
"display": true,
"required": false,
"displayName": "Retweets",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "next_cursor",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "next_cursor",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Replies",
"type": "string",
"display": true,
"required": false,
"displayName": "Replies",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Quotes",
"type": "string",
"display": true,
"required": false,
"displayName": "Quotes",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Date",
"type": "string",
"display": true,
"required": false,
"displayName": "Date",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "isreply",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "isreply",
"defaultMatch": false,
"canBeUsedToMatch": true
}
],
"mappingMode": "defineBelow",
"matchingColumns": [],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {
"useAppend": true
},
"operation": "append",
"sheetName": {
"__rl": true,
"mode": "list",
"value": "gid=0",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c/edit#gid=0",
"cachedResultName": "Sheet1"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c/edit?usp=drivesdk",
"cachedResultName": "Tweet Data"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"id": "6q55WdTedKPZERoF",
"name": "Google Sheets account 3"
}
},
"typeVersion": 4.7
},
{
"id": "86afb72d-92d7-460c-b9c0-5d96674c7931",
"name": "Count",
"type": "n8n-nodes-base.set",
"position": [
-240,
-1040
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "75e9cf42-928f-4dc2-a354-7b1edd7dfebb",
"name": "count",
"type": "number",
"value": 1
},
{
"id": "866e2004-3995-4431-b373-ac8b3b93c147",
"name": "query",
"type": "string",
"value": "emergentlabs"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "ae1ff19a-ff35-4cba-9269-1eeff32763ca",
"name": "counter",
"type": "n8n-nodes-base.set",
"position": [
-16,
-1040
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "f8c5768f-f465-42ca-b990-0f687ccc7805",
"name": "counter",
"type": "number",
"value": "={{ $json.count }}"
},
{
"id": "2290eb4e-938c-4b66-aefd-1b88a37f5f00",
"name": "cursor",
"type": "string",
"value": "={{ $json['next cursor'] }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "f0abc5af-dddc-48df-b916-0b7d79835171",
"name": "If",
"type": "n8n-nodes-base.if",
"position": [
1360,
-1120
],
"parameters": {
"options": {},
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "e80112e6-c902-4185-af64-8d706550886c",
"operator": {
"type": "number",
"operation": "equals"
},
"leftValue": "={{ $('counter').item.json.counter }}",
"rightValue": 1
}
]
}
},
"typeVersion": 2.2
},
{
"id": "38daa357-3e8f-46a5-8256-37717205b53d",
"name": "Limit",
"type": "n8n-nodes-base.limit",
"position": [
256,
-896
],
"parameters": {},
"typeVersion": 1
},
{
"id": "91a1fc06-52d9-4aef-af97-151199bded57",
"name": "set increase",
"type": "n8n-nodes-base.set",
"position": [
480,
-896
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "f2a3a921-640f-42b7-b455-4110cfc76f6e",
"name": "counter",
"type": "string",
"value": "={{ $('counter').item.json.counter }}"
},
{
"id": "8cad4530-b5b8-4a6f-b901-926f432b0ff3",
"name": "cursor",
"type": "string",
"value": "={{ $('Tweet Scraper').item.json.next_cursor }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "306f0c25-2e3a-4d2a-8d6a-4c50f3873ecf",
"name": "Code1",
"type": "n8n-nodes-base.code",
"position": [
704,
-896
],
"parameters": {
"jsCode": "const items = $input.all();\n\nreturn items.map(item => {\n // Default to 1 if no counter exists\n let newCount = 1;\n\n // 1. Correctly check if the counter EXISTS\n if (item.json && item.json.counter != null) {\n // 2. Convert the counter text to a number before adding\n newCount = parseInt(item.json.counter) + 1;\n }\n\n // Make sure the json object exists\n if (!item.json) {\n item.json = {};\n }\n\n // Add the new, calculated count to the item\n item.json.count = newCount;\n\n // 3. Return the single MODIFIED item, not the whole list\n return item;\n});"
},
"typeVersion": 2
},
{
"id": "639373f6-2282-49c6-bf3c-fe2fc14baf9b",
"name": "set count and cursor",
"type": "n8n-nodes-base.set",
"position": [
1152,
-848
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "42e55567-d8e4-4ee6-9649-a1299c09c2d3",
"name": "count",
"type": "string",
"value": "={{ $json.count }}"
},
{
"id": "c654e218-d1f6-49ef-b401-fb81ef428bbf",
"name": "cursor",
"type": "string",
"value": "={{ $json.cursor }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "143ba536-5062-4f1f-8930-8a3c1b1d0ac7",
"name": "Wait",
"type": "n8n-nodes-base.wait",
"position": [
208,
-1104
],
"webhookId": "792f7689-0419-41a5-9ccd-1bdd83002e48",
"parameters": {},
"typeVersion": 1.1
},
{
"id": "bcb717ef-5bd5-444b-8aa3-4921774b109a",
"name": "Switch",
"type": "n8n-nodes-base.switch",
"position": [
-272,
-448
],
"parameters": {
"rules": {
"values": [
{
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "4ed77836-9697-4a95-aa7a-ffbe4790f57b",
"operator": {
"type": "string",
"operation": "notExists",
"singleValue": true
},
"leftValue": "={{ $json.Content }}",
"rightValue": ""
}
]
}
}
]
},
"options": {
"fallbackOutput": "extra"
}
},
"typeVersion": 3.2
},
{
"id": "eda67442-2198-4692-bbdb-8db08dbf576f",
"name": "Google Gemini Chat Model",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
32,
-304
],
"parameters": {
"options": {}
},
"credentials": {
"googlePalmApi": {
"id": "sFPucaeaikoDAevM",
"name": "Google Gemini(PaLM) Api account 3"
}
},
"typeVersion": 1
},
{
"id": "e441a2b2-7abf-4c1f-a8d6-9a910474d85b",
"name": "getTweetsFromDatabase",
"type": "n8n-nodes-base.googleSheetsTool",
"position": [
448,
-320
],
"parameters": {
"options": {},
"sheetName": {
"__rl": true,
"mode": "list",
"value": "gid=0",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c/edit#gid=0",
"cachedResultName": "Sheet1"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c/edit?usp=drivesdk",
"cachedResultName": "Tweet Data"
},
"descriptionType": "manual",
"toolDescription": "Use this tool to get all recent tweets mentioning our brand from the Google Sheets database. It returns a complete list of tweets with details like content, author, likes, and retweets."
},
"credentials": {
"googleSheetsOAuth2Api": {
"id": "6q55WdTedKPZERoF",
"name": "Google Sheets account 3"
}
},
"typeVersion": 4.7
},
{
"id": "3edca455-922f-4956-8f45-6a47fd8024d2",
"name": "Append row in sheet1",
"type": "n8n-nodes-base.googleSheets",
"position": [
1136,
-480
],
"parameters": {
"columns": {
"value": {
"summary": "={{ $json.summary }}",
"tweetId": "={{ $json.tweetID }}",
"urgency": "={{ $json.urgency }}",
"keyTopic": "={{ $json.keyTopic }}",
"sentiment": "={{ $json.sentiment }}",
"action taken ": "Notmarked",
"date_analyzed": "={{ $now }}"
},
"schema": [
{
"id": "tweetId",
"type": "string",
"display": true,
"required": false,
"displayName": "tweetId",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "sentiment",
"type": "string",
"display": true,
"required": false,
"displayName": "sentiment",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "keyTopic",
"type": "string",
"display": true,
"required": false,
"displayName": "keyTopic",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "urgency",
"type": "string",
"display": true,
"required": false,
"displayName": "urgency",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "summary",
"type": "string",
"display": true,
"required": false,
"displayName": "summary",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "date_analyzed",
"type": "string",
"display": true,
"required": false,
"displayName": "date_analyzed",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "action taken ",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "action taken ",
"defaultMatch": false,
"canBeUsedToMatch": true
}
],
"mappingMode": "defineBelow",
"matchingColumns": [],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {},
"operation": "append",
"sheetName": {
"__rl": true,
"mode": "list",
"value": 454621199,
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c/edit#gid=454621199",
"cachedResultName": "Sheet2"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c/edit?usp=drivesdk",
"cachedResultName": "Tweet Data"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"id": "6q55WdTedKPZERoF",
"name": "Google Sheets account 3"
}
},
"typeVersion": 4.7
},
{
"id": "a9435786-bbe9-4f10-871c-97d1ccd314a0",
"name": "Aggregate",
"type": "n8n-nodes-base.aggregate",
"position": [
1728,
-688
],
"parameters": {
"options": {},
"fieldsToAggregate": {
"fieldToAggregate": [
{
"renameField": true,
"outputFieldName": "final",
"fieldToAggregate": "Content"
}
]
}
},
"typeVersion": 1
},
{
"id": "cd92a7ce-d58d-4291-b128-d67373128b2b",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1184,
-1120
],
"parameters": {
"width": 640,
"height": 320,
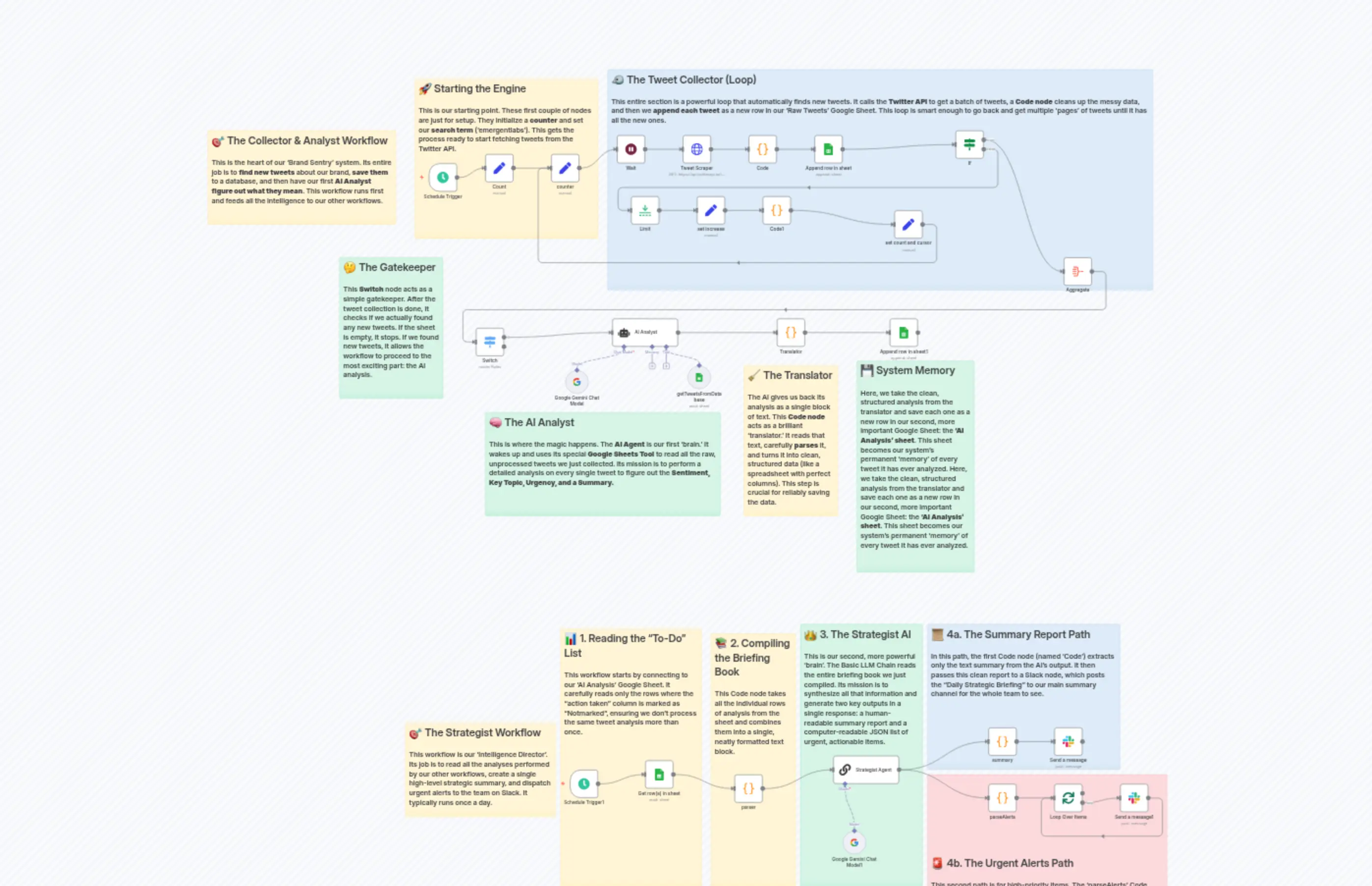
"content": "# 🎯 The Collector & Analyst Workflow\n\n## This is the heart of our 'Brand Sentry' system. Its entire job is to **find new tweets** about our brand, **save them** to a database, and then have our first **AI Analyst figure out what they mean**. This workflow runs first and feeds all the intelligence to our other workflows."
},
"typeVersion": 1
},
{
"id": "b41a6ef6-be6b-49a7-acd8-d335d07796d1",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-480,
-1296
],
"parameters": {
"width": 624,
"height": 544,
"content": "# 🚀 Starting the Engine\n\n\n## This is our starting point. These first couple of nodes are just for setup. They initialize a **counter** and set our **search term** ('emergentlabs'). This gets the process ready to start fetching tweets from the Twitter API."
},
"typeVersion": 1
},
{
"id": "5aeb7918-f3cd-4796-956d-b390ba82bca5",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
176,
-1328
],
"parameters": {
"color": 5,
"width": 1856,
"height": 752,
"content": "# 🐦 The Tweet Collector (Loop)\n\n## This entire section is a powerful loop that automatically finds new tweets. It calls the **Twitter API** to get a batch of tweets, a **Code node** cleans up the messy data, and then we **append each tweet** as a new row in our 'Raw Tweets' Google Sheet. This loop is smart enough to go back and get multiple 'pages' of tweets until it has all the new ones."
},
"typeVersion": 1
},
{
"id": "2fdc6db0-a947-42bf-ae04-f4869c7fd224",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
-736,
-688
],
"parameters": {
"color": 4,
"width": 352,
"height": 480,
"content": "# 🤔 The Gatekeeper\n\n## This **Switch** node acts as a simple gatekeeper. After the tweet collection is done, it checks if we actually found any new tweets. If the sheet is empty, it stops. If we found new tweets, it allows the workflow to proceed to the most exciting part: the AI analysis."
},
"typeVersion": 1
},
{
"id": "9277459d-8348-41a2-87fe-1c2fc3ca9bf8",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
-240,
-160
],
"parameters": {
"color": 4,
"width": 800,
"height": 352,
"content": "# 🧠 The AI Analyst\n\n## This is where the magic happens. The **AI Agent** is our first 'brain.' It wakes up and uses its special **Google Sheets Tool** to read all the raw, unprocessed tweets we just collected. Its mission is to perform a detailed analysis on every single tweet to figure out the **Sentiment, Key Topic, Urgency, and a Summary.**"
},
"typeVersion": 1
},
{
"id": "5a9c2c81-2b56-4f42-b606-0dff90cb5242",
"name": "Translator",
"type": "n8n-nodes-base.code",
"position": [
752,
-480
],
"parameters": {
"jsCode": "// Get the raw text output and remove any leading/trailing whitespace\nconst rawOutput = $input.first().json.output.trim();\nconst outputItems = [];\n\n// 1. Split the entire text into individual analysis blocks using \"---\"\nconst analyses = rawOutput.split('\\n---\\n');\n\n// 2. Loop through each text block\nfor (const chunk of analyses) {\n // Skip any empty blocks that might result from the split\n if (chunk.trim() === '') continue;\n\n const lines = chunk.trim().split('\\n');\n const cleanAnalysis = {};\n\n // 3. Loop through each line (e.g., \"Sentiment:: Positive\")\n for (const line of lines) {\n const parts = line.split('::');\n if (parts.length === 2) {\n // This part cleans up the key, e.g., \"Key Topic\" becomes \"keyTopic\"\n let key = parts[0].trim();\n key = key.charAt(0).toLowerCase() + key.slice(1).replace(/\\s+(\\w)/g, (match, letter) => letter.toUpperCase());\n \n const value = parts[1].trim();\n cleanAnalysis[key] = value;\n }\n }\n\n // 4. If we successfully built an object, add it to the output\n if (Object.keys(cleanAnalysis).length > 0) {\n outputItems.push({ json: cleanAnalysis });\n }\n}\n\nreturn outputItems;"
},
"typeVersion": 2
},
{
"id": "4c9bf29e-084e-47d1-8e69-c22b3bc34876",
"name": "Tweet Scraper",
"type": "n8n-nodes-base.httpRequest",
"position": [
432,
-1104
],
"parameters": {
"url": "https://api.twitterapi.io/twitter/tweet/advanced_search",
"options": {
"batching": {
"batch": {
"batchSize": 1,
"batchInterval": 2000
}
},
"pagination": {}
},
"sendQuery": true,
"authentication": "genericCredentialType",
"genericAuthType": "httpHeaderAuth",
"queryParameters": {
"parameters": [
{
"name": "query",
"value": "={{ $('Count').item.json.query }}"
},
{
"name": " queryType",
"value": "Latest"
},
{
"name": "cursor",
"value": "={{ $json.cursor }}"
}
]
}
},
"credentials": {
"httpHeaderAuth": {
"id": "wJgzPVfBYohOim1J",
"name": "twitter api io"
}
},
"typeVersion": 4.2
},
{
"id": "a2679e6f-eb6f-4e44-ac7f-a3f550a95976",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
640,
-320
],
"parameters": {
"width": 320,
"height": 512,
"content": "# 🧹 The Translator\n\n## The AI gives us back its analysis as a single block of text. This **Code node** acts as a brilliant 'translator.' It reads that text, carefully **parses** it, and turns it into clean, structured data (like a spreadsheet with perfect columns). This step is crucial for reliably saving the data."
},
"typeVersion": 1
},
{
"id": "5c4fe7a8-3747-4489-8829-0d91b15919ce",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
1024,
-336
],
"parameters": {
"color": 4,
"width": 400,
"height": 720,
"content": "# 💾 System Memory\n\n## Here, we take the clean, structured analysis from the translator and save each one as a new row in our second, more important Google Sheet: the **'AI Analysis' sheet**. This sheet becomes our system's permanent 'memory' of every tweet it has ever analyzed. Here, we take the clean, structured analysis from the translator and save each one as a new row in our second, more important Google Sheet: the **'AI Analysis' sheet**. This sheet becomes our system's permanent 'memory' of every tweet it has ever analyzed."
},
"typeVersion": 1
},
{
"id": "ec4bf437-8fdb-468f-abda-06f98fc6d37c",
"name": "Schedule Trigger",
"type": "n8n-nodes-base.scheduleTrigger",
"position": [
-432,
-1008
],
"parameters": {
"rule": {
"interval": [
{}
]
}
},
"typeVersion": 1.2
},
{
"id": "331ce67e-1830-4cc6-82c0-7e5ea2ccad26",
"name": "AI Analyst",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
192,
-480
],
"parameters": {
"text": "=For each distinct post, identify the following: 1. **Sentiment:** Is it Positive, Negative, or Neutral/Question? 2. **Key Topic:** What is the main subject (e.g., \"Product Quality,\" \"Customer Service,\" \"App Bug,\" \"Sales Inquiry\")? 3. **Urgency:** Is this something that requires an immediate response (High), a normal response (Medium), or no response (Low)? 4. **Summary:** 5. **Tweet ID::** \n6.Briefly summarize the post in one sentence.\n\n**CRITICAL FORMATTING RULES:**\n1. Your entire response must ONLY be the extracted data. Do not add any introductory or concluding text like \"Here's the summary...\".\n2. Format each post's analysis using the exact `Key:: Value` structure shown in the example. Use a double colon `::` with no extra formatting.\n3. Separate each distinct post analysis with a single line containing only three dashes `---`.\n\n**EXAMPLE OUTPUT:**\n\nTweet ID:: 1234567890\nSentiment:: Positive\nKey Topic:: Product Quality\nUrgency:: Low\nSummary:: The user is praising the new feature and says it works perfectly.\n---\nTweet ID:: 9876543210\nSentiment:: Negative\nKey Topic:: App Bug\nUrgency:: High\nSummary:: The user reports that the app crashes on startup after the latest update.",
"options": {
"systemMessage": "You are an expert Social Media Brand Analyst for \"EmergentLabs\". Your goal is to create a strategic summary of recent brand mentions. To do this, you must first use your available tools to fetch the latest tweets from the database."
},
"promptType": "define"
},
"typeVersion": 2.2
},
{
"id": "6ecb4d34-0fb5-4467-b298-09ddcc98bc65",
"name": "Google Gemini Chat Model1",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
976,
1264
],
"parameters": {
"options": {}
},
"credentials": {
"googlePalmApi": {
"id": "sFPucaeaikoDAevM",
"name": "Google Gemini(PaLM) Api account 3"
}
},
"typeVersion": 1
},
{
"id": "3aff36f1-2d9d-4d7a-836c-8c622bc8d67c",
"name": "Get row(s) in sheet",
"type": "n8n-nodes-base.googleSheets",
"position": [
304,
1024
],
"parameters": {
"options": {},
"filtersUI": {
"values": [
{
"lookupValue": "Notmarked",
"lookupColumn": "action taken "
}
]
},
"sheetName": {
"__rl": true,
"mode": "list",
"value": 454621199,
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c/edit#gid=454621199",
"cachedResultName": "Sheet2"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1SVkQU85XCFkr7KGvMxG61f9xuSD6qHf9CaSWo43LL3c/edit?usp=drivesdk",
"cachedResultName": "Tweet Data"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"id": "6q55WdTedKPZERoF",
"name": "Google Sheets account 3"
}
},
"typeVersion": 4.7
},
{
"id": "bc97d230-329b-46d0-ba78-525ac0b0f6dc",
"name": "parseAlerts",
"type": "n8n-nodes-base.code",
"position": [
1472,
1104
],
"parameters": {
"jsCode": "// Get the full text output from the AI\nconst aiOutput = $input.first().json.text;\n\n// Regex to find the JSON code block\nconst jsonRegex = /```json\\n([\\s\\S]*?)```/;\nconst match = aiOutput.match(jsonRegex);\n\n// If we found a JSON block, parse it and return each object as a separate item\nif (match && match[1]) {\n try {\n const jsonString = match[1];\n const actionableTweets = JSON.parse(jsonString);\n\n if (Array.isArray(actionableTweets)) {\n // This returns multiple items, one for each urgent tweet\n return actionableTweets.map(tweet => ({ json: tweet }));\n }\n } catch (error) {\n console.log(\"Failed to parse JSON:\", error);\n return []; // Return nothing if JSON is broken\n }\n}\n\n// Return nothing if no JSON block was found\nreturn [];"
},
"typeVersion": 2
},
{
"id": "cc2e2d5e-1f82-4cac-a8d8-6b5229ebde78",
"name": "Send a message",
"type": "n8n-nodes-base.slack",
"position": [
1696,
912
],
"webhookId": "fd363969-823b-440f-8f1d-429edcb9702f",
"parameters": {
"text": "=📈 *Brand Sentry: Daily Strategic Briefing* 📈 *Generated on: {{ new Date().toLocaleString('en-IN', { timeZone: 'Asia/Kolkata' }) }}* {{ $json.summaryReport }}",
"select": "channel",
"channelId": {
"__rl": true,
"mode": "list",
"value": "C09GMSQAHUP",
"cachedResultName": "brand-alerts"
},
"otherOptions": {
"includeLinkToWorkflow": false
},
"authentication": "oAuth2"
},
"credentials": {
"slackOAuth2Api": {
"id": "aTFdliaAoi5NenQp",
"name": "Slack account"
}
},
"typeVersion": 2.3
},
{
"id": "ede3bb3e-34b6-4a8f-b708-068cb54c5a87",
"name": "Send a message1",
"type": "n8n-nodes-base.slack",
"position": [
1920,
1104
],
"webhookId": "a50a8bd5-4016-4cb4-9920-3b51735ebc20",
"parameters": {
"text": "=🚨 *URGENT ACTION REQUIRED* 🚨 A social media mention has been flagged for immediate attention. *Urgency:* `{{ $json.urgency }}` *Reason:* {{ $json.reason }} *Tweet ID:* `{{ $json.tweetId }}` *Direct Link:* https://x.com/user/status/{{ $json.tweetId }}",
"select": "channel",
"channelId": {
"__rl": true,
"mode": "list",
"value": "C09HWHG5L8K",
"cachedResultName": "urgent"
},
"otherOptions": {
"includeLinkToWorkflow": false
},
"authentication": "oAuth2"
},
"credentials": {
"slackOAuth2Api": {
"id": "aTFdliaAoi5NenQp",
"name": "Slack account"
}
},
"typeVersion": 2.3
},
{
"id": "888243e5-3d56-4d5d-9e7b-9135e21282a2",
"name": "Loop Over Items",
"type": "n8n-nodes-base.splitInBatches",
"position": [
1696,
1104
],
"parameters": {
"options": {
"reset": false
}
},
"typeVersion": 3
},
{
"id": "0f91c2bf-c478-4c5b-8a7b-96e747347d87",
"name": "Strategist Agent",
"type": "@n8n/n8n-nodes-langchain.chainLlm",
"position": [
944,
1008
],
"parameters": {
"text": "=You are a Social Media Insights Expert. Your task is to analyze the provided social media data and generate a two-part report.\n\n**Part 1: The Summary Report**\nBased on all the posts, generate a summary report with these sections:\n1. Overall Sentiment\n2. Key Themes\n3. Positive Testimonials\n4. Most Influential Post\n\n**Part 2: Actionable Items JSON**\nAfter the summary report, you MUST provide a section titled \"--- ACTIONABLE TWEETS JSON ---\" followed by a valid JSON array. This array should contain objects ONLY for the tweets that have an Urgency of \"High\" or \"Medium\".\n\nEach JSON object must have the following keys: \"tweetId\", \"urgency\", \"reason\".\n- \"tweetId\": The ID of the tweet.\n- \"urgency\": The assessed urgency (High or Medium).\n- \"reason\": A brief, one-sentence explanation of why this tweet is actionable (e.g., \"User reports a critical bug,\" \"User is very angry about billing,\" \"User is asking a direct question about documentation.\").\n\nHere is the data:\n{{ $json.preparedText }}\n\n\nExample of the final JSON output format:\n--- ACTIONABLE TWEETS JSON ---\n```json\n[\n {\n \"tweetId\": \"1969737770261438710\",\n \"urgency\": \"High\",\n \"reason\": \"User is strongly criticizing the product's core functionality, stating it 'SUCKS'.\"\n },\n {\n \"tweetId\": \"1941086912703504401\",\n \"urgency\": \"Medium\",\n \"reason\": \"User is asking for more detailed product documentation, which could be a sales opportunity.\"\n }\n]\n\n",
"batching": {
"batchSize": 1
},
"promptType": "define"
},
"typeVersion": 1.7
},
{
"id": "4d2ec48f-415f-4fd4-824f-27506b8f0cb7",
"name": "parser",
"type": "n8n-nodes-base.code",
"position": [
608,
1072
],
"parameters": {
"jsCode": "const items = $input.all();\nlet combinedText = \"Here are the recent analyses to summarize:\\n\\n\";\nconst rowsToUpdate = [];\n\n// Loop through every row from the Google Sheet\nfor (const item of items) {\n const data = item.json;\n // Add the row number to our list for later\n rowsToUpdate.push({ rowNumber: item.json.rowNumber });\n \n // Create a neat summary for each analysis\n const entry = `\n---\nTweet ID: ${data.tweetId}\nSentiment: ${data.sentiment}\nKey Topic: ${data.keyTopic}\nUrgency: ${data.urgency}\nSummary: ${data.summary}\n---\n `;\n combinedText += entry;\n}\n\n// Return a SINGLE item with all the data we need\nreturn [{\n json: {\n preparedText: combinedText, // For the AI\n rowsToUpdate: rowsToUpdate // For the update step\n }\n}];"
},
"typeVersion": 2
},
{
"id": "55265036-18e2-44bb-8427-685219a56eea",
"name": "summary",
"type": "n8n-nodes-base.code",
"position": [
1472,
912
],
"parameters": {
"jsCode": "// Get the full text output from the AI\nconst aiOutput = $input.first().json.text;\n\n// Define the delimiter that separates the summary from the JSON\nconst summaryDelimiter = \"--- ACTIONABLE TWEETS JSON ---\";\n\n// Find where the summary text ends\nconst summaryEndIndex = aiOutput.indexOf(summaryDelimiter);\n\n// The summary is everything before the delimiter. If delimiter isn't found, use the whole text.\nconst summaryReport = summaryEndIndex !== -1 ? aiOutput.substring(0, summaryEndIndex).trim() : aiOutput.trim();\n\n// Return a single item with just the summary report\nreturn [{ json: { summaryReport: summaryReport } }];"
},
"typeVersion": 2
},
{
"id": "65f4b982-4196-4315-9b8f-caf5a2c03388",
"name": "Sticky Note8",
"type": "n8n-nodes-base.stickyNote",
"position": [
-512,
896
],
"parameters": {
"width": 512,
"height": 320,
"content": "# 🎯 The Strategist Workflow\n\n## This workflow is our 'Intelligence Director'. Its job is to read all the analyses performed by our other workflows, create a single high-level strategic summary, and dispatch urgent alerts to the team on Slack. It typically runs once a day."
},
"typeVersion": 1
},
{
"id": "15bd2e16-77cd-499a-9ca1-40b732a14a56",
"name": "Sticky Note9",
"type": "n8n-nodes-base.stickyNote",
"position": [
16,
576
],
"parameters": {
"width": 480,
"height": 880,
"content": "# 📊 1. Reading the \"To-Do\" List\n\n## This workflow starts by connecting to our 'AI Analysis' Google Sheet. It carefully reads only the rows where the \"action taken\" column is marked as \"Notmarked\", ensuring we don't process the same tweet analysis more than once."
},
"typeVersion": 1
},
{
"id": "b2f0cd05-fe05-486a-a7a6-604369ab4091",
"name": "Sticky Note10",
"type": "n8n-nodes-base.stickyNote",
"position": [
528,
592
],
"parameters": {
"width": 288,
"height": 864,
"content": "# 📚 2. Compiling the Briefing Book\n\n## This Code node takes all the individual rows of analysis from the sheet and combines them into a single, neatly formatted text block. "
},
"typeVersion": 1
},
{
"id": "7b62b892-025c-4d71-9673-5a1ab509fb09",
"name": "Sticky Note11",
"type": "n8n-nodes-base.stickyNote",
"position": [
832,
560
],
"parameters": {
"color": 4,
"width": 416,
"height": 896,
"content": "# 👑 3. The Strategist AI\n\n## This is our second, more powerful 'brain'. The Basic LLM Chain reads the entire briefing book we just compiled. Its mission is to synthesize all that information and generate two key outputs in a single response: a human-readable summary report and a computer-readable JSON list of urgent, actionable items."
},
"typeVersion": 1
},
{
"id": "71eb9e89-8314-4324-9b43-6441e9711b55",
"name": "Sticky Note12",
"type": "n8n-nodes-base.stickyNote",
"position": [
1264,
560
],
"parameters": {
"color": 5,
"width": 656,
"height": 496,
"content": "# 📜 4a. The Summary Report Path\n\n## In this path, the first Code node (named 'Code') extracts only the text summary from the AI's output. It then passes this clean report to a Slack node, which posts the \"Daily Strategic Briefing\" to our main summary channel for the whole team to see."
},
"typeVersion": 1
},
{
"id": "153bf685-006e-416c-aaf9-40b89625b2c1",
"name": "Sticky Note13",
"type": "n8n-nodes-base.stickyNote",
"position": [
1264,
1072
],
"parameters": {
"color": 3,
"width": 816,
"height": 496,
"content": "\n\n\n\n\n\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n# 🚨 4b. The Urgent Alerts Path\n\n## This second path is for high-priority items. The 'parseAlerts' Code node extracts the JSON list of urgent tweets. The 'Loop Over Items' node then processes each alert one-by-one, sending a separate, detailed message to our 'urgent' Slack channel for each item that needs immediate attention.\n\n"
},
"typeVersion": 1
},
{
"id": "a2d428b0-4ccd-4f74-a38e-35af8474022a",
"name": "Schedule Trigger1",
"type": "n8n-nodes-base.scheduleTrigger",
"position": [
48,
1056
],
"parameters": {
"rule": {
"interval": [
{
"triggerAtHour": 9
}
]
}
},
"typeVersion": 1.2
}
],
"pinData": {},
"connections": {
"If": {
"main": [
[
{
"node": "Aggregate",
"type": "main",
"index": 0
}
],
[
{
"node": "Limit",
"type": "main",
"index": 0
}
]
]
},
"Code": {
"main": [
[
{
"node": "Append row in sheet",
"type": "main",
"index": 0
}
]
]
},
"Wait": {
"main": [
[
{
"node": "Tweet Scraper",
"type": "main",
"index": 0
}
]
]
},
"Code1": {
"main": [
[
{
"node": "set count and cursor",
"type": "main",
"index": 0
}
]
]
},
"Count": {
"main": [
[
{
"node": "counter",
"type": "main",
"index": 0
}
]
]
},
"Limit": {
"main": [
[
{
"node": "set increase",
"type": "main",
"index": 0
}
]
]
},
"Switch": {
"main": [
[
{
"node": "AI Analyst",
"type": "main",
"index": 0
}
],
[]
]
},
"parser": {
"main": [
[
{
"node": "Strategist Agent",
"type": "main",
"index": 0
}
]
]
},
"counter": {
"main": [
[
{
"node": "Wait",
"type": "main",
"index": 0
}
]
]
},
"summary": {
"main": [
[
{
"node": "Send a message",
"type": "main",
"index": 0
}
]
]
},
"Aggregate": {
"main": [
[
{
"node": "Switch",
"type": "main",
"index": 0
}
]
]
},
"AI Analyst": {
"main": [
[
{
"node": "Translator",
"type": "main",
"index": 0
}
]
]
},
"Translator": {
"main": [
[
{
"node": "Append row in sheet1",
"type": "main",
"index": 0
}
]
]
},
"parseAlerts": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"set increase": {
"main": [
[
{
"node": "Code1",
"type": "main",
"index": 0
}
]
]
},
"Tweet Scraper": {
"main": [
[
{
"node": "Code",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[],
[
{
"node": "Send a message1",
"type": "main",
"index": 0
}
]
]
},
"Send a message1": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Schedule Trigger": {
"main": [
[
{
"node": "Count",
"type": "main",
"index": 0
}
]
]
},
"Strategist Agent": {
"main": [
[
{
"node": "summary",
"type": "main",
"index": 0
},
{
"node": "parseAlerts",
"type": "main",
"index": 0
}
]
]
},
"Schedule Trigger1": {
"main": [
[
{
"node": "Get row(s) in sheet",
"type": "main",
"index": 0
}
]
]
},
"Append row in sheet": {
"main": [
[
{
"node": "If",
"type": "main",
"index": 0
}
]
]
},
"Get row(s) in sheet": {
"main": [
[
{
"node": "parser",
"type": "main",
"index": 0
}
]
]
},
"Append row in sheet1": {
"main": [
[]
]
},
"set count and cursor": {
"main": [
[
{
"node": "counter",
"type": "main",
"index": 0
}
]
]
},
"getTweetsFromDatabase": {
"ai_tool": [
[
{
"node": "AI Analyst",
"type": "ai_tool",
"index": 0
}
]
]
},
"Google Gemini Chat Model": {
"ai_languageModel": [
[
{
"node": "AI Analyst",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Google Gemini Chat Model1": {
"ai_languageModel": [
[
{
"node": "Strategist Agent",
"type": "ai_languageModel",
"index": 0
}
]
]
}
}
}