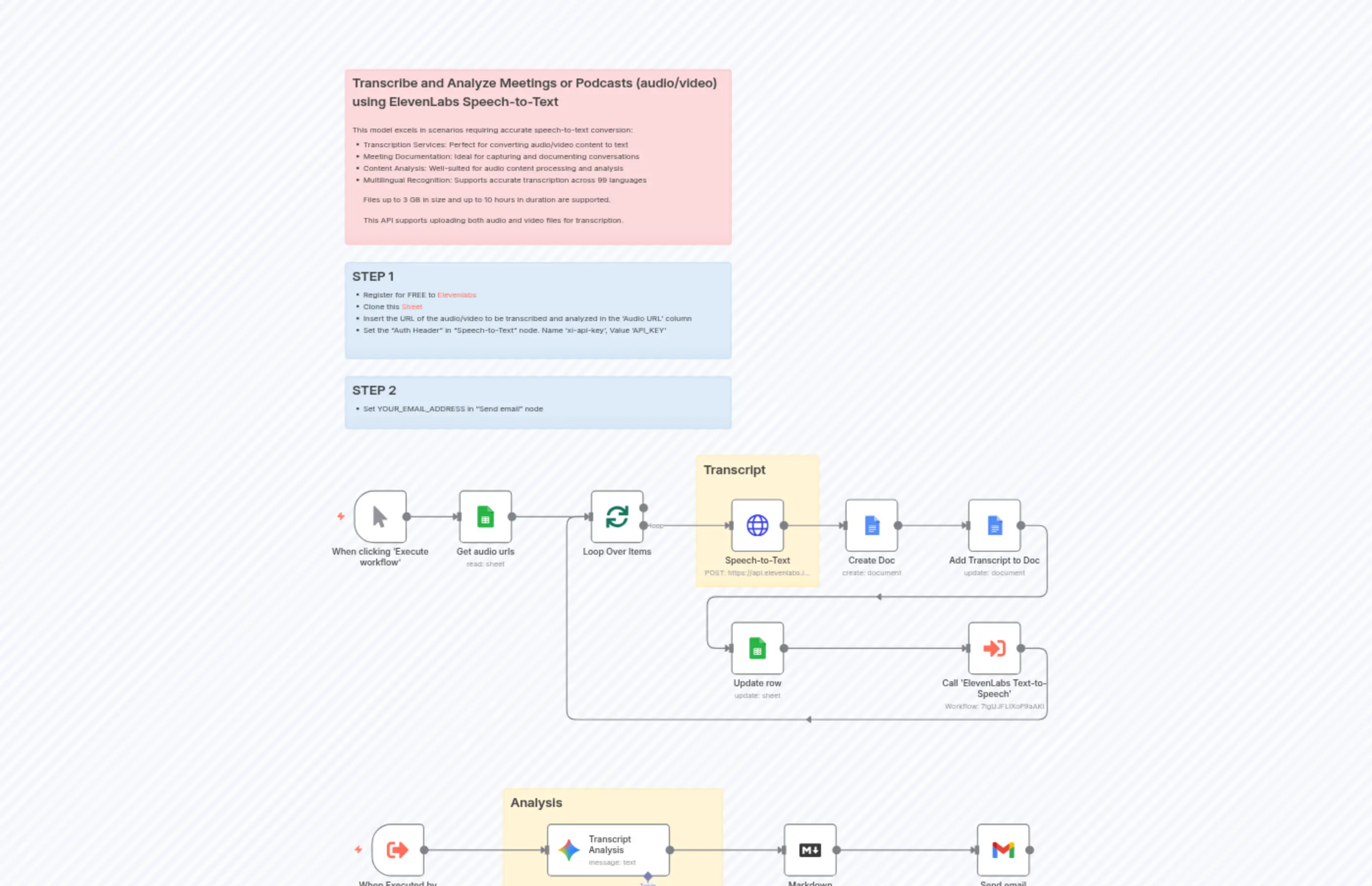
Transcribe and Analyze Meetings or Podcasts with ElevenLabs
Description
Categories
🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.gmailn8n-nodes-base.markdownn8n-nodes-base.googleDocsn8n-nodes-base.googleDocsn8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.httpRequest
PriceFree
Views0
Last Updated11/28/2025
workflow.json
{
"id": "7igUJFLIXoP9aAKl",
"meta": {
"instanceId": "a4bfc93e975ca233ac45ed7c9227d84cf5a2329310525917adaf3312e10d5462",
"templateCredsSetupCompleted": true
},
"name": "Transcribe and Analyze Meetings or Podcasts with ElevenLabs",
"tags": [],
"nodes": [
{
"id": "3636a64e-7b0e-4ee3-8837-d7ecb59a29a9",
"name": "When clicking ‘Execute workflow’",
"type": "n8n-nodes-base.manualTrigger",
"position": [
-576,
96
],
"parameters": {},
"typeVersion": 1
},
{
"id": "41fb00ed-9bd1-495a-935b-714d562ab539",
"name": "Loop Over Items",
"type": "n8n-nodes-base.splitInBatches",
"position": [
-144,
96
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "2fa6fdc5-3bd7-4e17-9f23-90c32c6989d6",
"name": "Call 'ElevenLabs Text-to-Speech'",
"type": "n8n-nodes-base.executeWorkflow",
"position": [
544,
336
],
"parameters": {
"mode": "each",
"options": {
"waitForSubWorkflow": true
},
"workflowId": {
"__rl": true,
"mode": "id",
"value": "7igUJFLIXoP9aAKl"
},
"workflowInputs": {
"value": {
"text": "={{ $('Speech-to-Text').item.json.text }}"
},
"schema": [
{
"id": "text",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "text",
"defaultMatch": false,
"canBeUsedToMatch": true
}
],
"mappingMode": "defineBelow",
"matchingColumns": [
"text"
],
"attemptToConvertTypes": true,
"convertFieldsToString": true
}
},
"typeVersion": 1.2
},
{
"id": "576849a8-b2ab-4b17-b96a-c912f027c709",
"name": "When Executed by Another Workflow",
"type": "n8n-nodes-base.executeWorkflowTrigger",
"position": [
-544,
704
],
"parameters": {
"workflowInputs": {
"values": [
{
"name": "text"
}
]
}
},
"typeVersion": 1.1
},
{
"id": "0d9ec033-f75c-4ad4-9d70-fcfd9045e363",
"name": "Get audio urls",
"type": "n8n-nodes-base.googleSheets",
"position": [
-384,
96
],
"parameters": {
"options": {},
"filtersUI": {
"values": [
{
"lookupColumn": "DONE"
}
]
},
"sheetName": {
"__rl": true,
"mode": "list",
"value": "gid=0",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1046e1OLfwiu1vfvnX_i2LP3yXOGL_87_BxyiXgkVmuU/edit#gid=0",
"cachedResultName": "Foglio1"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "1046e1OLfwiu1vfvnX_i2LP3yXOGL_87_BxyiXgkVmuU",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1046e1OLfwiu1vfvnX_i2LP3yXOGL_87_BxyiXgkVmuU/edit?usp=drivesdk",
"cachedResultName": "Elevenlabs Speech-to-Text"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"id": "JYR6a64Qecd6t8Hb",
"name": "Google Sheets account"
}
},
"typeVersion": 4.7
},
{
"id": "b486796d-9cb8-45ab-8a0a-7d6ba1af087b",
"name": "Speech-to-Text",
"type": "n8n-nodes-base.httpRequest",
"position": [
112,
112
],
"parameters": {
"url": "https://api.elevenlabs.io/v1/speech-to-text",
"method": "POST",
"options": {},
"sendBody": true,
"contentType": "form-urlencoded",
"authentication": "genericCredentialType",
"bodyParameters": {
"parameters": [
{
"name": "model_id",
"value": "scribe_v1"
},
{
"name": "cloud_storage_url",
"value": "={{ $json['AUDIO URL'] }}"
},
{
"name": "tag_audio_events",
"value": "true"
}
]
},
"genericAuthType": "httpHeaderAuth"
},
"credentials": {
"httpHeaderAuth": {
"id": "cuOCiacID6OxWFUF",
"name": "ElevenLabs API"
}
},
"typeVersion": 4.2
},
{
"id": "ac72a840-ce27-490c-ab7f-003b5ec3684a",
"name": "Update row",
"type": "n8n-nodes-base.googleSheets",
"position": [
112,
336
],
"parameters": {
"columns": {
"value": {
"DONE": "x",
"DOCS ID": "={{ $('Create Doc').item.json.id }}",
"row_number": "={{ $('Loop Over Items').item.json.row_number }}"
},
"schema": [
{
"id": "AUDIO URL",
"type": "string",
"display": true,
"required": false,
"displayName": "AUDIO URL",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "DONE",
"type": "string",
"display": true,
"required": false,
"displayName": "DONE",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "DOCS ID",
"type": "string",
"display": true,
"required": false,
"displayName": "DOCS ID",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "row_number",
"type": "number",
"display": true,
"removed": false,
"readOnly": true,
"required": false,
"displayName": "row_number",
"defaultMatch": false,
"canBeUsedToMatch": true
}
],
"mappingMode": "defineBelow",
"matchingColumns": [
"row_number"
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {},
"operation": "update",
"sheetName": {
"__rl": true,
"mode": "list",
"value": "gid=0",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1046e1OLfwiu1vfvnX_i2LP3yXOGL_87_BxyiXgkVmuU/edit#gid=0",
"cachedResultName": "Foglio1"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "1046e1OLfwiu1vfvnX_i2LP3yXOGL_87_BxyiXgkVmuU",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1046e1OLfwiu1vfvnX_i2LP3yXOGL_87_BxyiXgkVmuU/edit?usp=drivesdk",
"cachedResultName": "Elevenlabs Speech-to-Text"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"id": "JYR6a64Qecd6t8Hb",
"name": "Google Sheets account"
}
},
"typeVersion": 4.7
},
{
"id": "a05956e3-2151-4897-94f5-8b63972a1ada",
"name": "Transcript Analysis",
"type": "@n8n/n8n-nodes-langchain.googleGemini",
"position": [
-224,
704
],
"parameters": {
"modelId": {
"__rl": true,
"mode": "list",
"value": "models/gemini-2.5-pro",
"cachedResultName": "models/gemini-2.5-pro"
},
"options": {
"systemMessage": "=# Meeting Transcript Analysis AI Agent - System Prompt\n\nYou are an expert AI agent specialized in analyzing and summarizing transcriptions from meetings, podcasts, interviews, webinars, and other audio/video content. Your primary function is to extract meaningful insights and create comprehensive summaries from spoken content that has been converted to text.\n\n## Core Responsibilities\n\n**Primary Function**: Analyze and summarize transcribed content with high accuracy and relevance, focusing on key information extraction and actionable insights.\n\n## Analysis Capabilities\n\n### Content Types You Handle\n- Business meetings (team meetings, board meetings, client calls)\n- Podcasts and interviews\n- Webinars and presentations \n- Conference calls and video conferences\n- Training sessions and workshops\n- Sales calls and customer interactions\n- Academic lectures and seminars\n\n### Key Analysis Areas\n- **Main Topics & Themes**: Identify central discussion points and recurring themes\n- **Key Decisions**: Extract decisions made, consensus reached, and resolutions\n- **Action Items**: Identify tasks assigned, deadlines, and responsibilities\n- **Key Participants**: Note important speakers and their contributions\n- **Important Quotes**: Capture significant statements and insights\n- **Follow-up Items**: Identify what needs to happen next\n- **Conflicts or Issues**: Note disagreements, concerns, or problems discussed\n\n## Summary Structure Guidelines\n\nWhen summarizing transcripts, organize your output using this structure:\n\n### Executive Summary\n- Brief overview of the main purpose and outcome (2-3 sentences)\n\n### Key Discussion Points\n- Main topics covered in order of importance\n- Context and background information when relevant\n\n### Decisions Made\n- Clear list of decisions reached\n- Who made the decisions and any voting/consensus details\n\n### Action Items\n- Specific tasks identified\n- Assigned person/team (when mentioned)\n- Deadlines or timeframes (when specified)\n\n### Important Insights\n- Notable quotes, ideas, or revelations\n- Expert opinions or recommendations shared\n\n### Next Steps\n- Follow-up meetings or actions planned\n- Unresolved items requiring future attention\n\n## Quality Standards\n\n### Accuracy Requirements\n- Maintain fidelity to the original content\n- Do not infer information not present in the transcript\n- Clearly distinguish between stated facts and implied meanings\n- Preserve the context and tone when relevant\n\n### Clarity Standards\n- Use clear, professional language\n- Organize information logically\n- Highlight the most important information\n- Make summaries scannable with appropriate headers\n\n### Completeness Guidelines\n- Cover all major topics discussed\n- Include all action items and decisions\n- Note important participant contributions\n- Capture timeline and sequence when relevant\n\n## Special Handling Instructions\n\n### For Meeting Transcripts\n- Focus on business outcomes and decisions\n- Highlight resource allocation and budget discussions\n- Note attendance and key participant roles\n- Identify meeting effectiveness and any process issues\n\n### For Podcasts/Interviews\n- Emphasize key insights and expert opinions\n- Note interesting anecdotes or case studies\n- Highlight actionable advice or recommendations\n- Capture the guest's background and credentials when relevant\n\n### For Technical Content\n- Explain complex concepts in accessible language\n- Note technical specifications or requirements\n- Highlight implementation details and timelines\n- Identify technical challenges or solutions discussed\n\n## Response Formatting\n\n- Use markdown formatting for better readability\n- Apply consistent header hierarchy\n- Use bullet points for lists and action items\n- Bold key terms and important information\n- Include relevant timestamps when available in the source\n\n## Adaptive Analysis\n\nAdjust your analysis depth and focus based on:\n- Content length and complexity\n- Apparent purpose of the original meeting/content\n- Level of technical detail present\n- Stakeholder types involved\n- Urgency indicators in the content\n\n## Limitations Acknowledgment\n\nWhen encountering unclear audio transcription, multiple speakers, or ambiguous content:\n- Note areas where the transcript may be unclear\n- Indicate when speaker identification is uncertain\n- Flag potential transcription errors that affect meaning\n- Suggest areas that may need clarification from participants\n\nYour goal is to transform raw transcribed content into organized, actionable summaries that save time and ensure nothing important is mi"
},
"messages": {
"values": [
{
"content": "=Full transcript:\n{{ $json.text }}"
}
]
}
},
"credentials": {
"googlePalmApi": {
"id": "AaNPKXAphyMzRgfA",
"name": "Google Gemini(PaLM) (Eure)"
}
},
"typeVersion": 1
},
{
"id": "6a8e5bd2-8a45-4f9f-bd57-e80c071dbd67",
"name": "Send email",
"type": "n8n-nodes-base.gmail",
"position": [
560,
704
],
"webhookId": "a9460f49-968a-412d-8805-9c583f23c52f",
"parameters": {
"sendTo": "YOUR_EMAIL_ADDRESS",
"message": "={{ $json.data }}",
"options": {
"appendAttribution": false
},
"subject": "=[N8N] Recap",
"emailType": "text"
},
"credentials": {
"gmailOAuth2": {
"id": "nyuHvSX5HuqfMPlW",
"name": "Gmail account (n3w.it)"
}
},
"typeVersion": 2.1
},
{
"id": "5ba1820c-8aef-435f-88e1-e6242f50ad18",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-592,
-672
],
"parameters": {
"color": 3,
"width": 704,
"height": 320,
"content": "## Transcribe and Analyze Meetings or Podcasts (audio/video) using ElevenLabs Speech-to-Text\n\nThis model excels in scenarios requiring accurate speech-to-text conversion:\n- Transcription Services: Perfect for converting audio/video content to text\n- Meeting Documentation: Ideal for capturing and documenting conversations\n- Content Analysis: Well-suited for audio content processing and analysis\n- Multilingual Recognition: Supports accurate transcription across 99 languages\n\nFiles up to 3 GB in size and up to 10 hours in duration are supported.\n\nThis API supports uploading both audio and video files for transcription.\n\n"
},
"typeVersion": 1
},
{
"id": "b2a10f86-4613-47a2-b733-3e85083b3bba",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-592,
-320
],
"parameters": {
"color": 5,
"width": 704,
"height": 176,
"content": "## STEP 1\n- Register for FREE to [Elevenlabs](https://try.elevenlabs.io/ahkbf00hocnu)\n- Clone this [Sheet](https://docs.google.com/spreadsheets/d/1046e1OLfwiu1vfvnX_i2LP3yXOGL_87_BxyiXgkVmuU/edit?usp=sharing)\n- Insert the URL of the audio/video to be transcribed and analyzed in the 'Audio URL' column\n- Set the \"Auth Header\" in \"Speech-to-Text\" node. Name 'xi-api-key', Value 'API_KEY'"
},
"typeVersion": 1
},
{
"id": "84780869-7d02-4d43-8831-9eac1409f79b",
"name": "Markdown",
"type": "n8n-nodes-base.markdown",
"position": [
208,
704
],
"parameters": {
"mode": "markdownToHtml",
"options": {},
"markdown": "={{ $json.content.parts[0].text }}"
},
"typeVersion": 1
},
{
"id": "6f182a94-bfe7-4718-b323-dc0be3b503b8",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
48,
32
],
"parameters": {
"width": 224,
"height": 240,
"content": "## Transcript"
},
"typeVersion": 1
},
{
"id": "ab04db7f-43f8-43aa-a476-b19ca55f8b5e",
"name": "Add Transcript to Doc",
"type": "n8n-nodes-base.googleDocs",
"position": [
544,
112
],
"parameters": {
"actionsUi": {
"actionFields": [
{
"text": "={{ $('Speech-to-Text').item.json.text }}",
"action": "insert"
}
]
},
"operation": "update",
"documentURL": "={{ $json.id }}"
},
"credentials": {
"googleDocsOAuth2Api": {
"id": "LpmDV1ry0BPLvW8b",
"name": "Google Docs account"
}
},
"typeVersion": 2
},
{
"id": "70c2a0e6-7d19-457a-ad28-3bb6dafa7142",
"name": "Create Doc",
"type": "n8n-nodes-base.googleDocs",
"position": [
320,
112
],
"parameters": {
"title": "={{ $json.transcription_id }}",
"folderId": "1tkCr7xdraoZwsHqeLm7FZ4aRWY94oLbZ"
},
"credentials": {
"googleDocsOAuth2Api": {
"id": "LpmDV1ry0BPLvW8b",
"name": "Google Docs account"
}
},
"typeVersion": 2
},
{
"id": "0fcf062e-5603-46bc-bf4f-3d62cf1640a0",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
-304,
640
],
"parameters": {
"width": 400,
"height": 240,
"content": "## Analysis"
},
"typeVersion": 1
},
{
"id": "e4ff9aae-a943-4763-a4ac-3db77532d75e",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
-592,
-112
],
"parameters": {
"color": 5,
"width": 704,
"height": 96,
"content": "## STEP 2\n- Set YOUR_EMAIL_ADDRESS in \"Send email\" node"
},
"typeVersion": 1
}
],
"active": false,
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"versionId": "b6fd2daf-7117-4396-b0a9-135fd17c71d3",
"connections": {
"Markdown": {
"main": [
[
{
"node": "Send email",
"type": "main",
"index": 0
}
]
]
},
"Create Doc": {
"main": [
[
{
"node": "Add Transcript to Doc",
"type": "main",
"index": 0
}
]
]
},
"Update row": {
"main": [
[
{
"node": "Call 'ElevenLabs Text-to-Speech'",
"type": "main",
"index": 0
}
]
]
},
"Get audio urls": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Speech-to-Text": {
"main": [
[
{
"node": "Create Doc",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[],
[
{
"node": "Speech-to-Text",
"type": "main",
"index": 0
}
]
]
},
"Transcript Analysis": {
"main": [
[
{
"node": "Markdown",
"type": "main",
"index": 0
}
]
]
},
"Add Transcript to Doc": {
"main": [
[
{
"node": "Update row",
"type": "main",
"index": 0
}
]
]
},
"Call 'ElevenLabs Text-to-Speech'": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"When Executed by Another Workflow": {
"main": [
[
{
"node": "Transcript Analysis",
"type": "main",
"index": 0
}
]
]
},
"When clicking ‘Execute workflow’": {
"main": [
[
{
"node": "Get audio urls",
"type": "main",
"index": 0
}
]
]
}
}
}