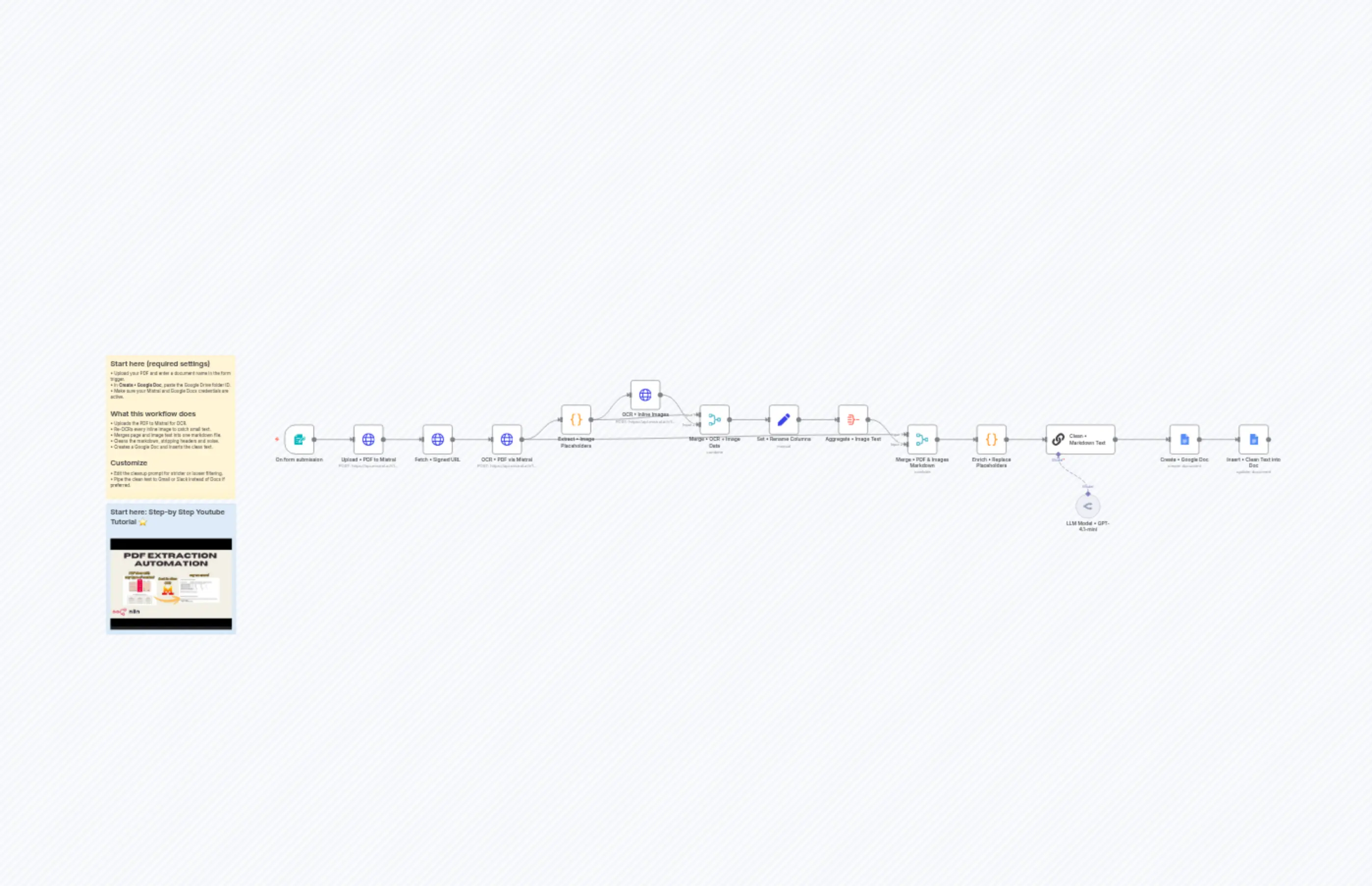
Turn Any PDF into a Clean Google Doc with Mistral OCR
Description
Categories
🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.setn8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.mergen8n-nodes-base.mergen8n-nodes-base.aggregaten8n-nodes-base.googleDocsn8n-nodes-base.googleDocsn8n-nodes-base.stickyNoten8n-nodes-base.stickyNote
PriceFree
Views0
Last Updated11/28/2025
workflow.json
{
"id": "evPxNVkJ3vVScGsS",
"meta": {
"instanceId": "36fee986cc83112881fb12ec7cc2d0221d7bddd71c11715c196899b114e8b0d2",
"templateCredsSetupCompleted": true
},
"name": "Turn Any PDF into a Clean Google Doc with Mistral OCR",
"tags": [],
"nodes": [
{
"id": "f5199976-f999-4552-9943-3a1a25d34eeb",
"name": "On form submission",
"type": "n8n-nodes-base.formTrigger",
"position": [
-1440,
80
],
"webhookId": "81573452-f871-4eb1-b13e-60eabde2e012",
"parameters": {
"options": {},
"formTitle": "Document Scanner",
"formFields": {
"values": [
{
"fieldType": "file",
"fieldLabel": "file",
"requiredField": true,
"acceptFileTypes": ".pdf"
},
{
"fieldLabel": "Document Name",
"placeholder": "NVIDIA Annual Report Doc",
"requiredField": true
}
]
},
"formDescription": "Insert the google drive url that stores your image PDFs"
},
"typeVersion": 2.2
},
{
"id": "863d40f4-01a5-4989-99a5-ba2ba2e2ab92",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-2016,
-144
],
"parameters": {
"width": 416,
"height": 464,
"content": "## Start here (required settings)\n• Upload your PDF and enter a document name in the form trigger.\n• In **Create • Google Doc**, paste the Google Drive folder ID.\n• Make sure your Mistral and Google Docs credentials are active.\n\n## What this workflow does\n• Uploads the PDF to Mistral for OCR.\n• Re-OCRs every inline image to catch small text.\n• Merges page and image text into one markdown file.\n• Cleans the markdown, stripping headers and noise.\n• Creates a Google Doc and inserts the clean text.\n\n## Customize\n• Edit the cleanup prompt for stricter or looser filtering.\n• Pipe the clean text to Gmail or Slack instead of Docs if preferred."
},
"typeVersion": 1
},
{
"id": "b0f99739-aed6-45bc-a0f0-818a6a5523a0",
"name": "Upload • PDF to Mistral",
"type": "n8n-nodes-base.httpRequest",
"position": [
-1216,
80
],
"parameters": {
"url": "https://api.mistral.ai/v1/files",
"method": "POST",
"options": {},
"sendBody": true,
"contentType": "multipart-form-data",
"authentication": "predefinedCredentialType",
"bodyParameters": {
"parameters": [
{
"name": "purpose",
"value": "ocr"
},
{
"name": "file",
"parameterType": "formBinaryData",
"inputDataFieldName": "file"
}
]
},
"nodeCredentialType": "mistralCloudApi"
},
"credentials": {
"mistralCloudApi": {
"id": "Xmws9BgP1rH4wzpK",
"name": "Mistral Cloud account"
}
},
"typeVersion": 4.2
},
{
"id": "b508b895-52d6-4060-b409-97b6bb18aee0",
"name": "Fetch • Signed URL",
"type": "n8n-nodes-base.httpRequest",
"position": [
-992,
80
],
"parameters": {
"url": "=https://api.mistral.ai/v1/files/{{ $json.id }}/url",
"options": {},
"sendQuery": true,
"sendHeaders": true,
"authentication": "predefinedCredentialType",
"queryParameters": {
"parameters": [
{
"name": "expiry",
"value": "24"
}
]
},
"headerParameters": {
"parameters": [
{
"name": "Accept",
"value": "application/json"
}
]
},
"nodeCredentialType": "mistralCloudApi"
},
"credentials": {
"mistralCloudApi": {
"id": "Xmws9BgP1rH4wzpK",
"name": "Mistral Cloud account"
}
},
"typeVersion": 4.2
},
{
"id": "ca574ffa-2e18-49b3-a4d5-a456ce3cc2bf",
"name": "OCR • PDF via Mistral",
"type": "n8n-nodes-base.httpRequest",
"position": [
-768,
80
],
"parameters": {
"url": "https://api.mistral.ai/v1/ocr",
"method": "POST",
"options": {},
"jsonBody": "={\n \"model\": \"mistral-ocr-latest\",\n \"document\": {\n \"type\": \"document_url\",\n \"document_url\": \"{{ $json.url }}\"\n },\n \"include_image_base64\": true\n}",
"sendBody": true,
"sendHeaders": true,
"specifyBody": "json",
"authentication": "predefinedCredentialType",
"headerParameters": {
"parameters": [
{}
]
},
"nodeCredentialType": "mistralCloudApi"
},
"credentials": {
"mistralCloudApi": {
"id": "Xmws9BgP1rH4wzpK",
"name": "Mistral Cloud account"
}
},
"typeVersion": 4.2
},
{
"id": "af8dcda4-7928-401f-acab-a58091564c2b",
"name": "Extract • Image Placeholders",
"type": "n8n-nodes-base.code",
"position": [
-544,
16
],
"parameters": {
"jsCode": "// Input: one item with ocrResponse at items[0].json\nconst out = [];\nconst res = items[0].json;\n\nfor (const page of res.pages || []) {\n const md = page.markdown || \"\";\n const imgs = page.images || [];\n // Build a quick lookup by id: \"img-0.jpeg\" -> image object\n const byId = Object.fromEntries(imgs.map(im => [im.id, im]));\n // Find placeholders in markdown\n const re = /!\\[(.*?)\\]\\((img-\\d+\\.(?:jpe?g|png|webp|avif))\\)/g;\n let m;\n while ((m = re.exec(md)) !== null) {\n const id = m[2];\n const im = byId[id];\n if (!im || !im.image_base64) continue;\n out.push({\n json: {\n pageIndex: page.index,\n imageId: id,\n // This is already a full data URI like \"data:image/jpeg;base64,...\"\n imageDataUri: im.image_base64\n }\n });\n }\n}\nreturn out.length ? out : [{ json: { note: \"no-embedded-images\" } }];\n"
},
"typeVersion": 2
},
{
"id": "7fdaedc6-bf1b-46cd-831f-db3298b96f15",
"name": "OCR • Inline Images",
"type": "n8n-nodes-base.httpRequest",
"position": [
-320,
-64
],
"parameters": {
"url": "https://api.mistral.ai/v1/ocr",
"method": "POST",
"options": {
"response": {}
},
"jsonBody": "={\n \"model\": \"mistral-ocr-latest\",\n \"document\": {\n \"type\": \"image_url\",\n \"image_url\": \"{{ $json.imageDataUri }}\"\n },\n \"include_image_base64\": true\n} ",
"sendBody": true,
"specifyBody": "json",
"authentication": "predefinedCredentialType",
"nodeCredentialType": "mistralCloudApi"
},
"credentials": {
"mistralCloudApi": {
"id": "Xmws9BgP1rH4wzpK",
"name": "Mistral Cloud account"
}
},
"typeVersion": 4.2
},
{
"id": "8f7fa9a4-a328-4e02-bc99-01132c180873",
"name": "Merge • OCR + Image Data",
"type": "n8n-nodes-base.merge",
"position": [
-96,
16
],
"parameters": {
"mode": "combine",
"options": {},
"combineBy": "combineByPosition"
},
"typeVersion": 3.2
},
{
"id": "5e0e12d2-0985-48e3-89e6-e62824d7edb6",
"name": "Set • Rename Columns",
"type": "n8n-nodes-base.set",
"position": [
128,
16
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "558c0d83-7dfe-412f-927f-82c37551b910",
"name": "pageIndex",
"type": "number",
"value": "={{ $json.pageIndex }}"
},
{
"id": "a7df3b1e-a851-4b83-a811-bd58a2ad3253",
"name": "imageId",
"type": "string",
"value": "={{ $json.imageId }}"
},
{
"id": "2cba94bc-7d32-4098-ac1a-e1ee9d27e587",
"name": "imageDataUri",
"type": "string",
"value": "={{ $json.imageDataUri }}"
},
{
"id": "69b97aab-6822-4d88-ab57-75b4a5aa861e",
"name": "imagePages",
"type": "array",
"value": "={{ $json.pages }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "1b6c4a20-276c-44b1-8dfe-bb9f9e5df91d",
"name": "Aggregate • Image Text",
"type": "n8n-nodes-base.aggregate",
"position": [
352,
16
],
"parameters": {
"options": {},
"fieldsToAggregate": {
"fieldToAggregate": [
{
"fieldToAggregate": "imagePages[0].markdown"
}
]
}
},
"typeVersion": 1
},
{
"id": "03f08eba-80a5-429c-8584-cf9f40dd4e7f",
"name": "Merge • PDF & Images Markdown",
"type": "n8n-nodes-base.merge",
"position": [
576,
80
],
"parameters": {
"mode": "combine",
"options": {},
"combineBy": "combineByPosition"
},
"typeVersion": 3.2
},
{
"id": "7e02c3cc-68e0-4bda-ad41-8a67b2aee2a5",
"name": "Enrich • Replace Placeholders",
"type": "n8n-nodes-base.code",
"position": [
800,
80
],
"parameters": {
"jsCode": "// n8n Code node: merge main page markdown with OCR text for each img-N / imageN\nconst rows = $input.all().map(i => i.json);\n\n// ───────────────────────── config ─────────────────────────\nconst MERGE_MODE = 'replace'; // 'replace' or 'append'\nconst EXTS = '(?:jpeg|jpg|png|gif|webp|avif)';\n\n// ───────────────────────── helpers ────────────────────────\nconst asString = v => (v == null ? '' : String(v));\nconst isStringArray = a => Array.isArray(a) && a.every(x => typeof x === 'string');\n\n// Strip any image tokens from OCR text so we do not re-insert placeholders\nconst stripImageTokens = s =>\n asString(s)\n .replace(/!\\[[^\\]]*]\\([^)]+\\)/gi, '') // remove markdown image tags\n .replace(/\\b(?:img[-_]?|image[-_]?)\\d+\\.(?:jpeg|jpg|png|gif|webp|avif)\\b/gi, '')\n .trim();\n\n// Try to locate the \"main\" document row (has page-level markdown)\nconst main =\n rows.find(r => typeof r['pages[0].markdown'] === 'string' && r['pages[0].markdown'].length) ||\n rows.find(r => Array.isArray(r.pages) && r.pages.length && typeof r.pages[0]?.markdown === 'string') ||\n rows.find(r => typeof r.documentMarkdown === 'string' && r.documentMarkdown.length);\n\nif (!main) {\n return [{ json: { error: 'No main document row with pages[].markdown or pages[0].markdown found', rows } }];\n}\n\n// Build the starting document markdown\nlet doc = main['pages[0].markdown'] ||\n (Array.isArray(main.pages) ? main.pages.map(p => p?.markdown || '').join('\\n\\n') : '') ||\n main.documentMarkdown ||\n '';\n\n// ────────────────── build idx → text map ──────────────────\nconst idxToText = new Map();\n\n// 1) Per-image rows: derive index from imageId like \"img-12.jpg\" or \"image12.jpg\"\nfor (const r of rows) {\n if (r === main) continue;\n\n let imageId = r.imageId || (Array.isArray(r.images) && r.images[0]?.id) || '';\n imageId = asString(imageId);\n\n // Accept both \"img-12.jpg\" and \"image12.jpg\"\n let m = imageId.match(/(?:img[-_]?|image[-_]?)(\\d+)\\./i);\n if (!m) continue;\n const idx = Number(m[1]);\n\n // Prefer r.markdown[0], then r['markdown[0]'], then r.imagePages[0].markdown, then r.markdown (string)\n let text = null;\n if (Array.isArray(r.markdown) && r.markdown.length) text = r.markdown[0];\n else if (typeof r['markdown[0]'] === 'string') text = r['markdown[0]'];\n else if (Array.isArray(r.imagePages) && r.imagePages.length) text = r.imagePages[0]?.markdown || '';\n else if (typeof r.markdown === 'string') text = r.markdown;\n\n if (text != null && !idxToText.has(idx)) {\n idxToText.set(idx, stripImageTokens(text));\n }\n}\n\n// 2) Aggregated array case: r['imagePages[0].markdown'] is an array OR r.markdown is an array (your screenshot)\nfor (const r of rows) {\n const agg =\n (Array.isArray(r['imagePages[0].markdown']) && r['imagePages[0].markdown']) ||\n (isStringArray(r.markdown) && r.markdown);\n\n if (!agg) continue;\n\n agg.forEach((t, i) => {\n if (t == null) return;\n if (!idxToText.has(i)) idxToText.set(i, stripImageTokens(t));\n });\n}\n\n// If we still have no mapping, bail with debug\nif (idxToText.size === 0) {\n return [{\n json: {\n ...main,\n error: 'No OCR mapping built. Neither per-image rows nor aggregated markdown[] found.',\n debug_keys: rows.map(r => Object.keys(r)),\n sample_row: rows[0],\n }\n }];\n}\n\n// ────────────────── replace or append ─────────────────────\nlet placeholdersFound = 0;\nlet placeholdersReplaced = 0;\nconst missing = [];\n\nconst sorted = [...idxToText.entries()].sort((a, b) => a[0] - b[0]);\nfor (const [idx, textRaw] of sorted) {\n const text = asString(textRaw).trim();\n const nameGroup = `(?:img[-_]?${idx}|image[-_]?${idx})`;\n\n const patterns = [\n // markdown image:  or \n new RegExp(`!\\\\[[^\\\\]]*\\\\]\\\\(\\\\s*${nameGroup}\\\\.${EXTS}\\\\s*\\\\)`, 'gi'),\n // link style: [img-0.jpg](img-0.jpg)\n new RegExp(`\\\\[\\\\s*${nameGroup}\\\\.${EXTS}\\\\s*\\\\]\\\\(\\\\s*${nameGroup}\\\\.${EXTS}\\\\s*\\\\)`, 'gi'),\n // bare token somewhere in text\n new RegExp(`\\\\b${nameGroup}\\\\.${EXTS}\\\\b`, 'gi'),\n ];\n\n let localFound = 0;\n for (const rx of patterns) {\n const matches = doc.match(rx);\n if (!matches) continue;\n localFound += matches.length;\n\n if (MERGE_MODE === 'replace') {\n doc = doc.replace(rx, () => text);\n } else {\n // append under the image/link\n doc = doc.replace(rx, (m) => `${m}\\n\\n${text}\\n`);\n }\n }\n\n placeholdersFound += localFound;\n placeholdersReplaced += localFound;\n if (localFound === 0) missing.push({ idx, note: 'no placeholder found for this index' });\n}\n\n// ───────────────────────── output ─────────────────────────\nreturn [{\n json: {\n ...main,\n markdown: doc,\n enrichment_debug: {\n placeholdersFound,\n placeholdersReplaced,\n missing,\n mappedCount: idxToText.size,\n },\n },\n}];\n"
},
"typeVersion": 2
},
{
"id": "d8b064fb-ede2-47ea-b1a0-d964f04e6ab1",
"name": "Clean • Markdown Text",
"type": "@n8n/n8n-nodes-langchain.chainLlm",
"position": [
1024,
80
],
"parameters": {
"text": "=You are a careful assistant trained to clean raw text extracted from any file type (docs, PDFs, web pages, OCR, spreadsheets, slides, logs).\n\nThe input may contain:\n\n* Placeholder or boilerplate text (“Lorem ipsum…”, template notes)\n* Broken or noisy formatting (excess asterisks, stray symbols, HTML/XML tags, Markdown artifacts)\n* OCR or export debris (headers, footers, page numbers, hyphenated line breaks)\n* Gibberish or data dumps (meaningless numbers, repeated years, fake tables)\n* Duplicates or irrelevant lines\n\nYour task:\n\n* **Remove** placeholders, boilerplate, headers/footers, page numbers, repeated dates or numbers with no context, broken tables, tracking strings, and formatting noise.\n* **Normalize** spacing, line breaks, and list structure. Fix obviously broken sentences or words split by line-wrap.\n* **Preserve** substantive content: real sentences, section headings, lists, quotes, citations, code blocks that appear intentional, figures or formulas that are meaningful, and the original tone.\n* **Do not rewrite or summarize** valid content. Only repair text that is clearly malformed.\n* Keep the **original language** of the input.\n* Return the result as clean **markdown-style text**.\n\nInput:\n\n```\n{{ $json[\"markdown\"] }}\n```\n\nOutput:\n\n* Only the cleaned, concise markdown text. No extra commentary.\n",
"batching": {},
"promptType": "define"
},
"typeVersion": 1.7
},
{
"id": "8e461ca0-b9a0-4158-9b56-51885ee183c8",
"name": "Create • Google Doc",
"type": "n8n-nodes-base.googleDocs",
"position": [
1424,
80
],
"parameters": {
"title": "={{ $('On form submission').item.json['Document Name'] }}",
"folderId": "16ooKdLhm5GzzKSSZl1wMGTHJOfJ3-r13"
},
"credentials": {
"googleDocsOAuth2Api": {
"id": "FAyP7uzcbNGZpjFI",
"name": "Google Docs account"
}
},
"typeVersion": 2
},
{
"id": "46219fff-1f07-4ac1-896e-81fccf5821ce",
"name": "Insert • Clean Text into Doc",
"type": "n8n-nodes-base.googleDocs",
"position": [
1648,
80
],
"parameters": {
"actionsUi": {
"actionFields": [
{
"text": "={{ $('Clean • Markdown Text').item.json.text }}",
"action": "insert"
}
]
},
"operation": "update",
"documentURL": "={{ $json.id }}"
},
"credentials": {
"googleDocsOAuth2Api": {
"id": "FAyP7uzcbNGZpjFI",
"name": "Google Docs account"
}
},
"typeVersion": 2
},
{
"id": "0a8010b7-c2bd-41bf-93f5-d39221721836",
"name": "LLM Model • GPT-4.1-mini",
"type": "@n8n/n8n-nodes-langchain.lmChatOpenRouter",
"position": [
1120,
304
],
"parameters": {
"options": {}
},
"credentials": {
"openRouterApi": {
"id": "9H6tnWvfT2T0cL3J",
"name": "OpenRouter account (Augra)"
}
},
"typeVersion": 1
},
{
"id": "f9deb8d7-51c4-495d-a895-d89821a96af5",
"name": "Sticky Note8",
"type": "n8n-nodes-base.stickyNote",
"position": [
-2016,
336
],
"parameters": {
"color": 5,
"width": 419,
"height": 422,
"content": "## Start here: Step-by Step Youtube Tutorial :star:\n\n[](https://youtu.be/VjIoAqvRPGs)\n"
},
"typeVersion": 1
}
],
"active": false,
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"versionId": "3cba0804-300f-4b73-b62b-1da49d68031b",
"connections": {
"On form submission": {
"main": [
[
{
"node": "Upload • PDF to Mistral",
"type": "main",
"index": 0
}
]
]
},
"Fetch • Signed URL": {
"main": [
[
{
"node": "OCR • PDF via Mistral",
"type": "main",
"index": 0
}
]
]
},
"Create • Google Doc": {
"main": [
[
{
"node": "Insert • Clean Text into Doc",
"type": "main",
"index": 0
}
]
]
},
"OCR • Inline Images": {
"main": [
[
{
"node": "Merge • OCR + Image Data",
"type": "main",
"index": 1
}
]
]
},
"Set • Rename Columns": {
"main": [
[
{
"node": "Aggregate • Image Text",
"type": "main",
"index": 0
}
]
]
},
"Clean • Markdown Text": {
"main": [
[
{
"node": "Create • Google Doc",
"type": "main",
"index": 0
}
]
]
},
"OCR • PDF via Mistral": {
"main": [
[
{
"node": "Extract • Image Placeholders",
"type": "main",
"index": 0
},
{
"node": "Merge • PDF & Images Markdown",
"type": "main",
"index": 0
}
]
]
},
"Aggregate • Image Text": {
"main": [
[
{
"node": "Merge • PDF & Images Markdown",
"type": "main",
"index": 1
}
]
]
},
"Upload • PDF to Mistral": {
"main": [
[
{
"node": "Fetch • Signed URL",
"type": "main",
"index": 0
}
]
]
},
"LLM Model • GPT-4.1-mini": {
"ai_languageModel": [
[
{
"node": "Clean • Markdown Text",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Merge • OCR + Image Data": {
"main": [
[
{
"node": "Set • Rename Columns",
"type": "main",
"index": 0
}
]
]
},
"Extract • Image Placeholders": {
"main": [
[
{
"node": "OCR • Inline Images",
"type": "main",
"index": 0
},
{
"node": "Merge • OCR + Image Data",
"type": "main",
"index": 0
}
]
]
},
"Enrich • Replace Placeholders": {
"main": [
[
{
"node": "Clean • Markdown Text",
"type": "main",
"index": 0
}
]
]
},
"Merge • PDF & Images Markdown": {
"main": [
[
{
"node": "Enrich • Replace Placeholders",
"type": "main",
"index": 0
}
]
]
}
}
}