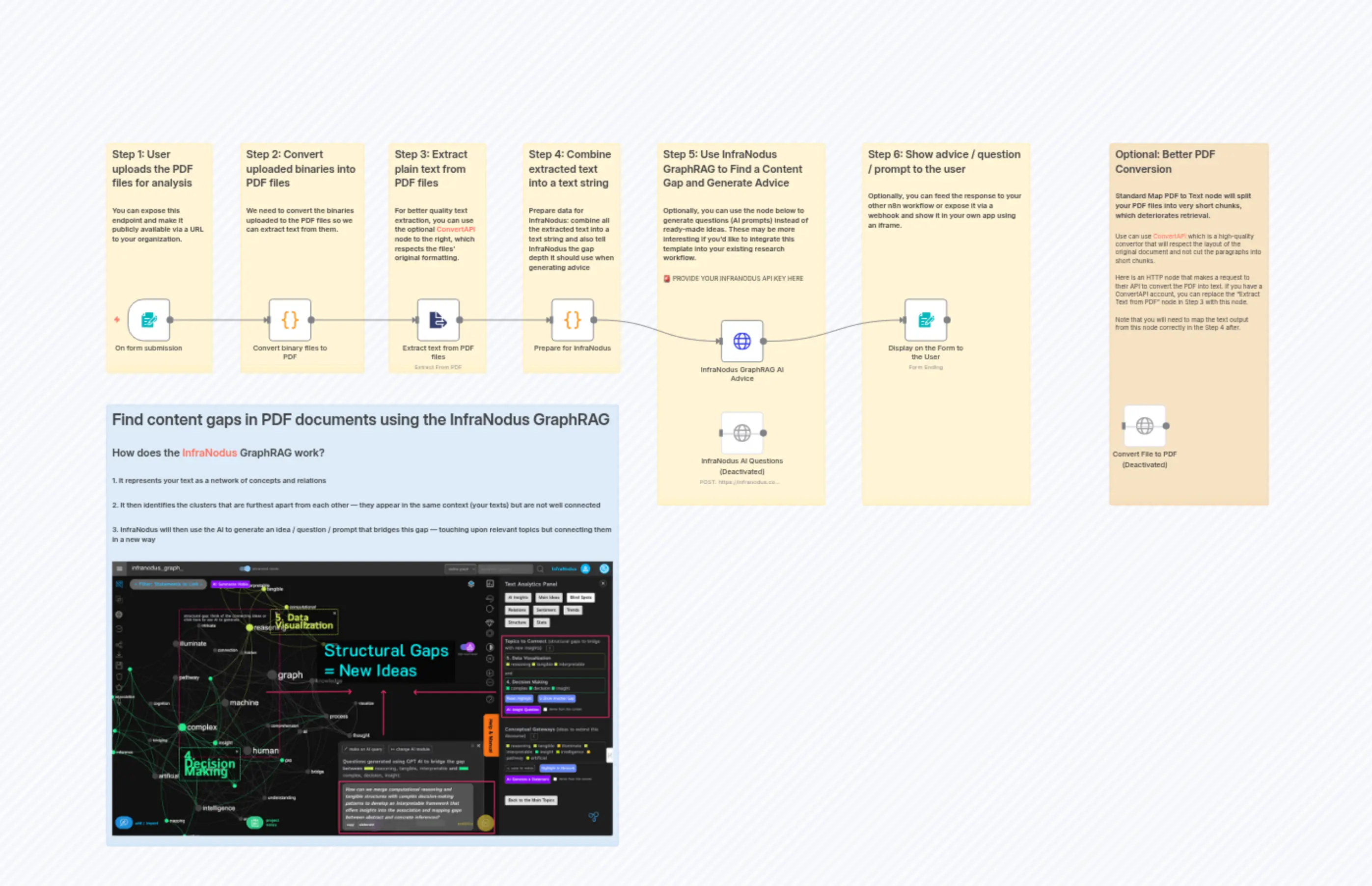
Generate Content Ideas from PDF Documents using GraphRAG
Description
Categories
🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.formn8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNote
PriceFree
Views0
Last Updated11/28/2025
workflow.json
{
"id": "5wnJMLkwYeOXdFkE",
"meta": {
"instanceId": "2a26454b0172ffcb8d70ba77c235b1209f92cd71bf06c79ba609c7173b416d68",
"templateCredsSetupCompleted": true
},
"name": "Generate Content Ideas from PDF Documents using GraphRAG",
"tags": [
{
"id": "66wgFoDi9Xjl74M3",
"name": "Support",
"createdAt": "2025-05-21T17:06:32.355Z",
"updatedAt": "2025-05-21T17:06:32.355Z"
},
{
"id": "kRM0hQV2zw7VxrON",
"name": "Research",
"createdAt": "2025-05-21T19:44:19.136Z",
"updatedAt": "2025-05-21T19:44:19.136Z"
},
{
"id": "sJk9cUvmMU8FkJXv",
"name": "AI",
"createdAt": "2025-05-20T13:16:15.636Z",
"updatedAt": "2025-05-20T13:16:15.636Z"
}
],
"nodes": [
{
"id": "212126f1-2a06-4211-814d-6b5a46df31ad",
"name": "Convert File to PDF",
"type": "n8n-nodes-base.httpRequest",
"disabled": true,
"position": [
1880,
180
],
"parameters": {
"url": "https://v2.convertapi.com/convert/pdf/to/txt",
"method": "POST",
"options": {
"response": {
"response": {
"responseFormat": "text"
}
}
},
"sendBody": true,
"contentType": "multipart-form-data",
"sendHeaders": true,
"authentication": "genericCredentialType",
"bodyParameters": {
"parameters": [
{
"name": "file",
"parameterType": "formBinaryData",
"inputDataFieldName": "data"
}
]
},
"genericAuthType": "httpBearerAuth",
"headerParameters": {
"parameters": [
{
"name": "Accept",
"value": "application/octet-stream"
}
]
}
},
"credentials": {
"httpBearerAuth": {
"id": "9fXf9Np7XsCWgxhg",
"name": "Perplexity"
}
},
"notesInFlow": true,
"typeVersion": 4.2
},
{
"id": "d0a606d8-c62e-42aa-8d82-e9adcc33f5f5",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
1840,
-400
],
"parameters": {
"color": 2,
"width": 360,
"height": 820,
"content": "## Optional: Better PDF Conversion\n\n### Standard Map PDF to Text node will split your PDF files into very short chunks, which deteriorates retrieval. \n\nUse can use [ConvertAPI](https://convertapi.com?ref=4l54n) which is a high-quality convertor that will respect the layout of the original document and not cut the paragraphs into short chunks. \n\nHere is an HTTP node that makes a request to their API to convert the PDF into text. If you have a ConvertAPI account, you can replace the \"Extract Text from PDF\" node in Step 3 with this node. \n\nNote that you will need to map the text output from this node correctly in the Step 4 after.\n"
},
"typeVersion": 1
},
{
"id": "f31d316f-d10a-47a4-b715-635cd58b996d",
"name": "On form submission",
"type": "n8n-nodes-base.formTrigger",
"position": [
-380,
-60
],
"webhookId": "baea8339-e0c0-43e1-acdf-d41bb25b2b85",
"parameters": {
"options": {
"appendAttribution": false
},
"formTitle": "Find Content Gaps in Your PDF Files",
"formFields": {
"values": [
{
"fieldType": "file",
"fieldLabel": "Add Your Files",
"acceptFileTypes": ".pdf"
}
]
},
"formDescription": "Upload the files you'd like to analyze and we will extract content gaps and interesting questions based on them."
},
"typeVersion": 2.2
},
{
"id": "56bae190-80e7-4fff-a06c-ee9ac74e5262",
"name": "InfraNodus AI Questions",
"type": "n8n-nodes-base.httpRequest",
"disabled": true,
"position": [
960,
200
],
"parameters": {
"url": "https://infranodus.com/api/v1/graphAndAdvice?doNotSave=true&optimize=develop&includeGraph=false&includeGraphSummary=true&gapDepth={{ $json.randomNum }}",
"method": "POST",
"options": {},
"sendBody": true,
"authentication": "genericCredentialType",
"bodyParameters": {
"parameters": [
{
"name": "aiTopics",
"value": "true"
},
{
"name": "requestMode",
"value": "question"
},
{
"name": "text",
"value": "={{ $json.text }}"
}
]
},
"genericAuthType": "httpBearerAuth"
},
"credentials": {
"httpBearerAuth": {
"id": "FPDx6PA5CtzGEIQc",
"name": "InfraNodus DeeMeeTree API Key"
}
},
"typeVersion": 4.2
},
{
"id": "d546371b-c109-4273-9fb8-8abc5b89c4c1",
"name": "Convert binary files to PDF",
"type": "n8n-nodes-base.code",
"position": [
-60,
-60
],
"parameters": {
"jsCode": "let results = [];\n\nfor (let item of items) {\n if (item.binary) {\n // If there's binary data in the item, process each binary file\n for (let key in item.binary) {\n // Use the key as the file name\n let binaryKey = key.replace(/\\s/g, '_'); // Replace spaces with underscores for the key\n results.push({\n json: {\n fileName: binaryKey\n },\n binary: {\n [binaryKey]: item.binary[key] // Use the modified key for the binary data\n }\n });\n }\n }\n}\n\nreturn results;\n"
},
"typeVersion": 2
},
{
"id": "e4b0147b-c49e-4acc-90e8-976d6e0b177b",
"name": "Extract text from PDF files",
"type": "n8n-nodes-base.extractFromFile",
"position": [
280,
-60
],
"parameters": {
"options": {},
"operation": "pdf",
"binaryPropertyName": "={{ $json.fileName }}"
},
"typeVersion": 1
},
{
"id": "404f2c2b-0e97-4b49-96d4-16cb23c1d82e",
"name": "Prepare for InfraNodus",
"type": "n8n-nodes-base.code",
"position": [
580,
-60
],
"parameters": {
"jsCode": "\nlet plainText = '' // we send plain text from all the PDFs to InfraNodus for analysis\n\nconst randomNum = Math.floor(Math.random() * 3); // replace this with a 0 if you'd like to address the biggest gap in the knowledge graph\n\nfor (let item of items) {\n plainText += item.json.text + '\\n\\n' \n}\n\n\nreturn {text: plainText, randomNum};"
},
"typeVersion": 2
},
{
"id": "8d12370c-aa4a-41ad-a3dc-39090779abd0",
"name": "Display on the Form to the User",
"type": "n8n-nodes-base.form",
"position": [
1380,
-60
],
"webhookId": "05cde493-a003-4979-9bf0-2b09c77a4044",
"parameters": {
"operation": "completion",
"respondWith": "showText",
"responseText": "=<br>\n<h3>{{ $json.aiAdvice[0].text }}</h3>\n<br>\n"
},
"typeVersion": 1
},
{
"id": "d4b56485-ae4f-40a6-a69e-6362fa224cc5",
"name": "InfraNodus GraphRAG AI Advice",
"type": "n8n-nodes-base.httpRequest",
"position": [
960,
0
],
"parameters": {
"url": "=https://infranodus.com/api/v1/graphAndAdvice?doNotSave=true&optimize=develop&includeGraph=false&includeGraphSummary=true&gapDepth={{ $json.randomNum }}",
"method": "POST",
"options": {},
"sendBody": true,
"authentication": "genericCredentialType",
"bodyParameters": {
"parameters": [
{
"name": "aiTopics",
"value": "true"
},
{
"name": "requestMode",
"value": "idea"
},
{
"name": "text",
"value": "={{ $json.text }}"
}
]
},
"genericAuthType": "httpBearerAuth"
},
"credentials": {
"httpBearerAuth": {
"id": "FPDx6PA5CtzGEIQc",
"name": "InfraNodus DeeMeeTree API Key"
}
},
"typeVersion": 4.2
},
{
"id": "30da3a64-5020-44fb-8e56-38b68e66d342",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-420,
-400
],
"parameters": {
"height": 520,
"content": "## Step 1: User uploads the PDF files for analysis\n\n### You can expose this endpoint and make it publicly available via a URL to your organization."
},
"typeVersion": 1
},
{
"id": "90c0fb6f-cc11-43c7-bc06-2794968204ee",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-120,
-400
],
"parameters": {
"width": 280,
"height": 520,
"content": "## Step 2: Convert uploaded binaries into PDF files\n\n### We need to convert the binaries uploaded to the PDF files so we can extract text from them."
},
"typeVersion": 1
},
{
"id": "96d48573-5cb9-4ebe-8c64-ba7e14113a2e",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
220,
-400
],
"parameters": {
"width": 220,
"height": 520,
"content": "## Step 3: Extract plain text from PDF files\n\n### For better quality text extraction, you can use the optional [ConvertAPI](https://convertapi.com?ref=4l54n) node to the right, which respects the files' original formatting."
},
"typeVersion": 1
},
{
"id": "8f1fcffa-1738-4e84-9552-742bb563ab9d",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
520,
-400
],
"parameters": {
"width": 220,
"height": 520,
"content": "## Step 4: Combine extracted text into a text string\n\n### Prepare data for InfraNodus: combine all the extracted text into a text string and also tell InfraNodus the gap depth it should use when generating advice"
},
"typeVersion": 1
},
{
"id": "945f7df6-2b1e-44e9-ba89-0acf52b4b26e",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
820,
-400
],
"parameters": {
"width": 380,
"height": 820,
"content": "## Step 5: Use InfraNodus GraphRAG to Find a Content Gap and Generate Advice\n\n### Optionally, you can use the node below to generate questions (AI prompts) instead of ready-made ideas. These may be more interesting if you'd like to integrate this template into your existing research workflow.\n\n🚨 PROVIDE YOUR INFRANODUS API KEY HERE"
},
"typeVersion": 1
},
{
"id": "3ffd5445-7e0b-43b5-85ab-790407ece21b",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
1280,
-400
],
"parameters": {
"width": 380,
"height": 820,
"content": "## Step 6: Show advice / question / prompt to the user\n\n### Optionally, you can feed the response to your other n8n workflow or expose it via a webhook and show it in your own app using an iframe."
},
"typeVersion": 1
},
{
"id": "9320b872-4eea-4b70-942f-ec2688d250de",
"name": "Sticky Note7",
"type": "n8n-nodes-base.stickyNote",
"position": [
-420,
180
],
"parameters": {
"color": 5,
"width": 1160,
"height": 1000,
"content": "# Find content gaps in PDF documents using the InfraNodus GraphRAG\n\n## How does the [InfraNodus](https://infranodus.com) GraphRAG work?\n\n### 1. It represents your text as a network of concepts and relations\n\n### 2. It then identifies the clusters that are furthest apart from each other — they appear in the same context (your texts) but are not well connected\n\n### 3. InfraNodus will then use the AI to generate an idea / question / prompt that bridges this gap — touching upon relevant topics but connecting them in a new way\n\n"
},
"typeVersion": 1
}
],
"active": false,
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"versionId": "4cacd2c9-73cf-433d-ab20-a1226355c502",
"connections": {
"On form submission": {
"main": [
[
{
"node": "Convert binary files to PDF",
"type": "main",
"index": 0
}
]
]
},
"Prepare for InfraNodus": {
"main": [
[
{
"node": "InfraNodus GraphRAG AI Advice",
"type": "main",
"index": 0
}
]
]
},
"Convert binary files to PDF": {
"main": [
[
{
"node": "Extract text from PDF files",
"type": "main",
"index": 0
}
]
]
},
"Extract text from PDF files": {
"main": [
[
{
"node": "Prepare for InfraNodus",
"type": "main",
"index": 0
}
]
]
},
"InfraNodus GraphRAG AI Advice": {
"main": [
[
{
"node": "Display on the Form to the User",
"type": "main",
"index": 0
}
]
]
}
}
}