AI-Powered GitHub Talent Sourcing (by Language & Location) to Google Sheet
Description
Categories
🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.coden8n-nodes-base.slackn8n-nodes-base.slackn8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNote
PriceKostenlos
Views0
Last Updated11/28/2025
workflow.json
{
"id": "Z9AisRCBwOHsODBb",
"meta": {
"instanceId": "88804d8e264d231c18413147cc92e4245b20ae7b97d774bad847556f645c8192",
"templateCredsSetupCompleted": true
},
"name": "AI-Powered GitHub Talent Sourcing (by Language & Location) to Google Sheet",
"tags": [],
"nodes": [
{
"id": "c83323e8-99b3-4c7f-982a-e2feb19b5cd4",
"name": "Schedule Trigger",
"type": "n8n-nodes-base.scheduleTrigger",
"position": [
-1248,
320
],
"parameters": {
"rule": {
"interval": [
{
"field": "hours"
}
]
}
},
"typeVersion": 1.2
},
{
"id": "9f9068c1-90c8-4379-897b-6bd3c0ac7d1d",
"name": "Run a workflow task",
"type": "n8n-nodes-browseract-workflows.browserAct",
"position": [
-1056,
320
],
"parameters": {
"workflowId": "56789612177594999",
"inputParameters": {
"parameters": [
{
"name": "Language",
"value": "Python"
},
{
"name": "Location",
"value": "Berlin"
},
{
"name": "Total_Page",
"value": "2"
},
{
"name": "Public_Repositories",
"value": "5"
}
]
},
"additionalFields": {
"saveBrowserData": false
}
},
"credentials": {
"browserActApi": {
"id": "AzKMhR2eAlOjzDiJ",
"name": "BrowserAct account"
}
},
"typeVersion": 1
},
{
"id": "cdf80447-589d-4a4e-accd-b707f5d57bb9",
"name": "Get details of a workflow task",
"type": "n8n-nodes-browseract-workflows.browserAct",
"onError": "continueErrorOutput",
"position": [
-880,
320
],
"parameters": {
"taskId": "={{ $json.id }}",
"operation": "getTask",
"maxWaitTime": 600,
"waitForFinish": true,
"pollingInterval": 20
},
"credentials": {
"browserActApi": {
"id": "AzKMhR2eAlOjzDiJ",
"name": "BrowserAct account"
}
},
"typeVersion": 1
},
{
"id": "d9eb5881-55d5-4c0a-b501-65146feb31d5",
"name": "Code in JavaScript",
"type": "n8n-nodes-base.code",
"position": [
-624,
320
],
"parameters": {
"jsCode": "// Get the JSON string using the exact path provided by the user.\nconst jsonString = $input.first().json.output.string;\n\nlet parsedData;\n\n// Check if the string exists before attempting to parse\nif (!jsonString) {\n // Return an empty array or throw an error if no string is found\n // Throwing an error is usually better to stop the workflow if data is missing.\n throw new Error(\"Input string is empty or missing at the specified path: $input.first().json.output.string\");\n}\n\ntry {\n // 1. Parse the JSON string into a JavaScript array of objects\n parsedData = JSON.parse(jsonString);\n} catch (error) {\n // Handle JSON parsing errors (e.g., if the string is malformed)\n throw new Error(`Failed to parse JSON string: ${error.message}`);\n}\n\n// 2. Ensure the parsed data is an array\nif (!Array.isArray(parsedData)) {\n throw new Error('Parsed data is not an array. It cannot be split into multiple items.');\n}\n\n// 3. Map the array of objects into the n8n item format { json: object }\n// Each element in this array will be treated as a new item by n8n, achieving the split.\nconst outputItems = parsedData.map(item => ({\n json: item,\n}));\n\n// 4. Return the new array of items\nreturn outputItems;"
},
"typeVersion": 2
},
{
"id": "29dc23d1-8a9b-4255-b286-919b6d74d105",
"name": "AI Agent",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
-464,
320
],
"parameters": {
"text": "=\n1- first analyze the {{ $json.Summary }} it is their resume they sent and base on that give point to them 0 to 1000 if you have insufficent data or the resume is incomplete give the 0 for ResumeScore\n\n2-summ Using teh formula - FinalScore = ({{ $json.Followers }}×0.5)+({{ $json.TotalRepo }}×3) + ResumeScore - add the result to FinalScore\n\n\nif you face any insufficient data or problem Give 0 to FinalScore that and continue with next item don't send error\n\nsend all the item data + final Score to the structure Parser for Output formatting like this\n{\n\"Name\":{{ $json.Name }},\n\"Location\":{{ $json.Location }},\n\"TotalRepo\":{{ $json.TotalRepo }},\n\"Folowers\":{{ $json.Followers }},\n\"URL\":{{ $json.Url }},\n\"Score\": \"FinalScore\"\n}\n\n\n\n",
"options": {},
"promptType": "define",
"hasOutputParser": true
},
"retryOnFail": false,
"typeVersion": 2.2
},
{
"id": "1dc89499-f3cd-4934-b1ee-db906c717c60",
"name": "Structured Output Parser",
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"position": [
-320,
528
],
"parameters": {
"jsonSchemaExample": "{\n\"Name\":\"<String>\",\n\"Location\":\"<String>\",\n\"TotalRepo\":\"<String>\",\n\"Folowers\":\"<String>\",\n\"URL\":\"<String>\",\n\"Score\":\"<String>\"\n}"
},
"typeVersion": 1.3
},
{
"id": "939a35bb-c42a-4a7f-b964-4247e91e0111",
"name": "Append or update row in sheet",
"type": "n8n-nodes-base.googleSheets",
"position": [
-64,
320
],
"parameters": {
"columns": {
"value": {
"URL": "={{ $json.output.URL }}",
"Name": "={{ $json.output.Name }}",
"Score": "={{ $json.output.Score }}",
"Folowers": "={{ $json.output.Folowers }}",
"Location": "={{ $json.output.Location }}",
"TotalRepo": "={{ $json.output.TotalRepo }}"
},
"schema": [
{
"id": "Name",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "Name",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Location",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "Location",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "TotalRepo",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "TotalRepo",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Folowers",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "Folowers",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "URL",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "URL",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "Score",
"type": "string",
"display": true,
"removed": false,
"required": false,
"displayName": "Score",
"defaultMatch": false,
"canBeUsedToMatch": true
}
],
"mappingMode": "defineBelow",
"matchingColumns": [
"Name"
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {},
"operation": "appendOrUpdate",
"sheetName": {
"__rl": true,
"mode": "list",
"value": 1185614504,
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/18sw7io0yJOTDzvcknGmjBBqtK154CLk3k0FoWJZbfI0/edit#gid=1185614504",
"cachedResultName": "Source Top GitHub Contributors by Language & Location"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "18sw7io0yJOTDzvcknGmjBBqtK154CLk3k0FoWJZbfI0",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/18sw7io0yJOTDzvcknGmjBBqtK154CLk3k0FoWJZbfI0/edit?usp=drivesdk",
"cachedResultName": "Test For BrowserAct"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"id": "wAMAqU43zjVjlpuA",
"name": "Google Sheets account"
}
},
"typeVersion": 4.7
},
{
"id": "4cadfa65-6904-41c1-acde-54026def1a38",
"name": "Gemini Chat",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
-464,
528
],
"parameters": {
"options": {}
},
"credentials": {
"googlePalmApi": {
"id": "U1olizkBYhp4g9AB",
"name": "Google Gemini(PaLM) Api account"
}
},
"typeVersion": 1
},
{
"id": "f92a627f-ff32-4306-9861-b40c0e6e1d4e",
"name": "Sticky Note - Intro",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1856,
32
],
"parameters": {
"width": 592,
"height": 418,
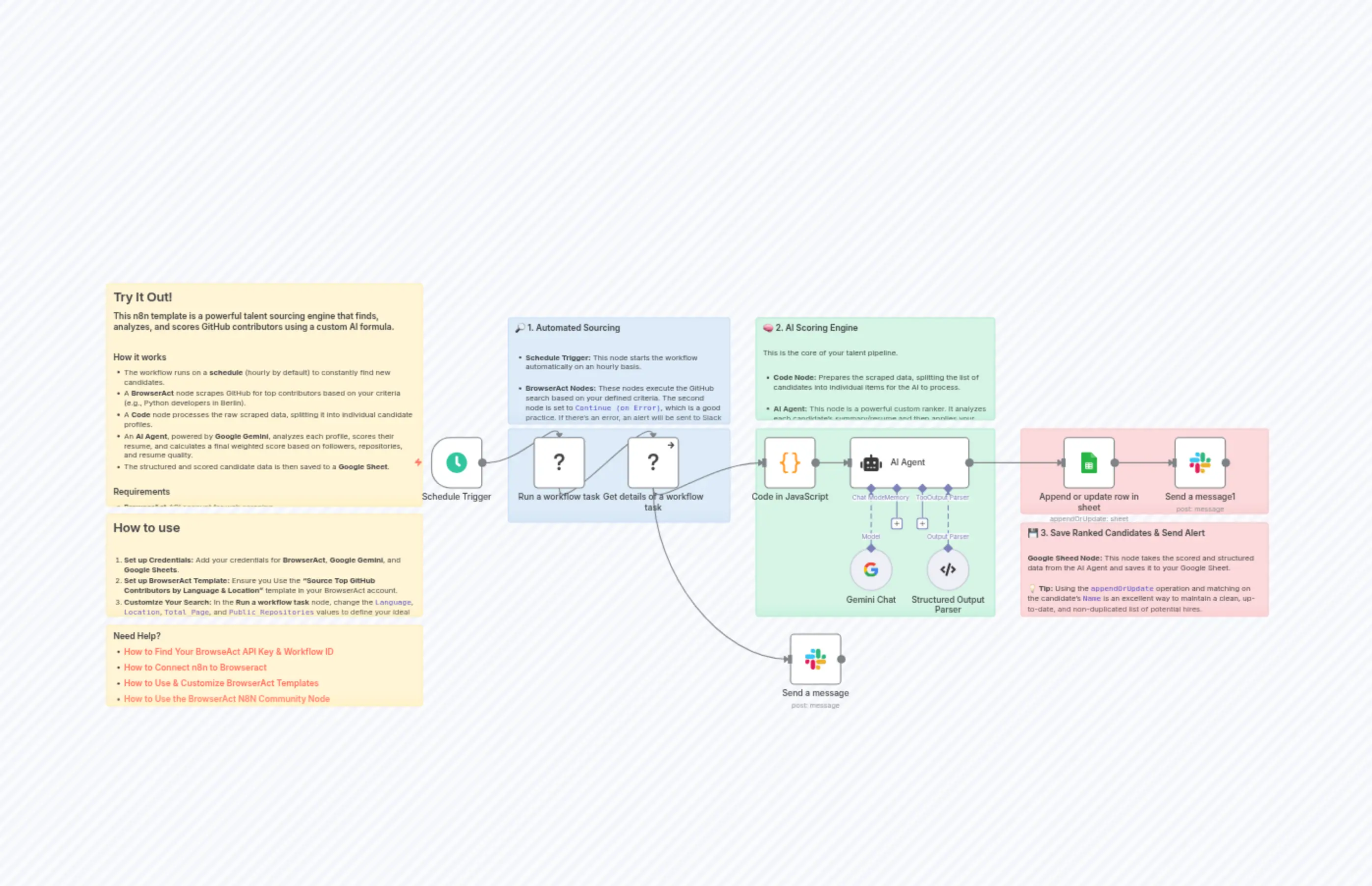
"content": "## Try It Out!\n### This n8n template is a powerful talent sourcing engine that finds, analyzes, and scores GitHub contributors using a custom AI formula.\n\n### How it works\n* The workflow runs on a **schedule** (hourly by default) to constantly find new candidates.\n* A **BrowserAct** node scrapes GitHub for top contributors based on your criteria (e.g., Python developers in Berlin).\n* A **Code** node processes the raw scraped data, splitting it into individual candidate profiles.\n* An **AI Agent**, powered by **Google Gemini**, analyzes each profile, scores their resume, and calculates a final weighted score based on followers, repositories, and resume quality.\n* The structured and scored candidate data is then saved to a **Google Sheet**.\n\n### Requirements\n* **BrowserAct** API account for web scraping.\n* **BrowserAct** n8n Community Node -> ([n8n Nodes BrowserAct](https://www.npmjs.com/package/n8n-nodes-browseract-workflows))\n* **Google Gemini** account for the AI Agent.\n* **Google Sheets** credentials for saving leads.\n* A BrowserAct template named **“Source Top GitHub Contributors by Language & Location”**.\n\n### Need Help?\nJoin the [Discord](https://discord.com/invite/UpnCKd7GaU) or Visit Our [Blog](https://www.browseract.com/blog)!\n"
},
"typeVersion": 1
},
{
"id": "6fdaf305-b5de-4e3e-9043-cc931b9f2763",
"name": "Sticky Note - How to Use",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1856,
464
],
"parameters": {
"width": 592,
"height": 192,
"content": "## How to use\n\n1. **Set up Credentials:** Add your credentials for **BrowserAct**, **Google Gemini**, and **Google Sheets**.\n2. **Set up BrowserAct Template:** Ensure you Use the **“Source Top GitHub Contributors by Language & Location”** template in your BrowserAct account.\n3. **Customize Your Search:** In the **Run a workflow task** node, change the `Language`, `Location`, `Total_Page`, and `Public_Repositories` values to define your ideal candidate profile.\n4. **Activate Workflow:** Activate the workflow to begin sourcing. You can change the search frequency in the **Schedule Trigger** node."
},
"typeVersion": 1
},
{
"id": "4e9e1ed0-429a-46ea-80b7-b7034e229502",
"name": "Sticky Note - Need Help",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1856,
672
],
"parameters": {
"width": 592,
"height": 152,
"content": "### Need Help?\n* #### [How to Find Your BrowseAct API Key & Workflow ID](https://www.youtube.com/watch?v=pDjoZWEsZlE)\n* #### [How to Connect n8n to Browseract](https://www.youtube.com/watch?v=RoYMdJaRdcQ)\n* #### [How to Use & Customize BrowserAct Templates](https://www.youtube.com/watch?v=CPZHFUASncY)\n* #### [How to Use the BrowserAct N8N Community Node](https://youtu.be/j0Nlba2pRLU)\n* #### [Automate Talent Sourcing: Find GitHub Devs with n8n & Browseract](https://youtu.be/TnhnXunNMMU)"
},
"typeVersion": 1
},
{
"id": "226ff98d-1bee-4266-bfa1-23ad201b0fa9",
"name": "Sticky Note - Sourcing Stage",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1104,
96
],
"parameters": {
"color": 5,
"width": 416,
"height": 200,
"content": "### 🔎 1. Automated Sourcing\n\n* **Schedule Trigger:** This node starts the workflow automatically on an hourly basis.\n\n* **BrowserAct Nodes:** These nodes execute the GitHub search based on your defined criteria. The second node is set to `Continue (on Error)`, which is a good practice. If there's an error, an alert will be sent to Slack \n\n**💡 Tip:** For a complete solution, connect an alert node (like Slack or Email) to the second (error) output of the 'Get details' node to be notified if the scraping task fails."
},
"typeVersion": 1
},
{
"id": "46248447-0c5f-48f8-97b8-58bdb2cd31a5",
"name": "Sticky Note - AI Scoring Engine",
"type": "n8n-nodes-base.stickyNote",
"position": [
-640,
96
],
"parameters": {
"color": 4,
"width": 448,
"height": 192,
"content": "### 🧠 2. AI Scoring Engine\n\nThis is the core of your talent pipeline.\n\n* **Code Node:** Prepares the scraped data, splitting the list of candidates into individual items for the AI to process.\n\n* **AI Agent:** This node is a powerful custom ranker. It analyzes each candidate's summary/resume and then applies your specific formula to calculate a `FinalScore`. This allows you to rank candidates based on what's most important to you (e.g., repositories, followers, resume quality)."
},
"typeVersion": 1
},
{
"id": "4f47741b-61df-4af5-a1f3-ea60cf63c954",
"name": "Sticky Note - Saving Candidates",
"type": "n8n-nodes-base.stickyNote",
"position": [
-144,
480
],
"parameters": {
"color": 3,
"width": 464,
"height": 176,
"content": "### 💾 3. Save Ranked Candidates & Send Alert\n\n**Google Sheed Node:** This node takes the scored and structured data from the AI Agent and saves it to your Google Sheet.\n\n**💡 Tip:** Using the `appendOrUpdate` operation and matching on the candidate's `Name` is an excellent way to maintain a clean, up-to-date, and non-duplicated list of potential hires.\n\n* **Slack Nodes:** Send Slack message, providing clear, actionable alerts to your team."
},
"typeVersion": 1
},
{
"id": "ab7c68b0-cafa-41b6-93fa-e42ff635e5f4",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1104,
304
],
"parameters": {
"color": 5,
"width": 416,
"height": 176,
"content": ""
},
"typeVersion": 1
},
{
"id": "e81a953c-7c54-427b-9b14-30f175df1677",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-640,
304
],
"parameters": {
"color": 4,
"width": 448,
"height": 352,
"content": ""
},
"typeVersion": 1
},
{
"id": "7e9afec8-7fb8-4c7c-85bc-cde8f6c4fbf3",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
-144,
304
],
"parameters": {
"color": 3,
"width": 464,
"content": ""
},
"typeVersion": 1
},
{
"id": "ab2e11fa-747f-40e2-a061-37a765c4a2de",
"name": "Send a message",
"type": "n8n-nodes-base.slack",
"position": [
-576,
688
],
"webhookId": "75fe3be1-722e-4dab-8424-d7cb1ce4ab93",
"parameters": {
"text": "BrowserAct Workflow Faces Problem",
"select": "channel",
"channelId": {
"__rl": true,
"mode": "list",
"value": "C09KLV9DJSX",
"cachedResultName": "all-browseract-workflow-test"
},
"otherOptions": {},
"authentication": "oAuth2"
},
"credentials": {
"slackOAuth2Api": {
"id": "5rQCkyObBqbHIbZA",
"name": "Slack account"
}
},
"typeVersion": 2.3
},
{
"id": "1a3ab789-2d02-41d3-9e3c-c5236cdf4b7a",
"name": "Send a message1",
"type": "n8n-nodes-base.slack",
"position": [
144,
320
],
"webhookId": "e8d87864-f3ee-4010-8eab-b9ce861ca68f",
"parameters": {
"text": "GitHub Contributors Updated",
"select": "channel",
"channelId": {
"__rl": true,
"mode": "list",
"value": "C09KLV9DJSX",
"cachedResultName": "all-browseract-workflow-test"
},
"otherOptions": {},
"authentication": "oAuth2"
},
"credentials": {
"slackOAuth2Api": {
"id": "5rQCkyObBqbHIbZA",
"name": "Slack account"
}
},
"typeVersion": 2.3
}
],
"active": false,
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"versionId": "0805aa19-4e7e-48b3-9d7e-e4f8baf2c207",
"connections": {
"AI Agent": {
"main": [
[
{
"node": "Append or update row in sheet",
"type": "main",
"index": 0
}
]
]
},
"Gemini Chat": {
"ai_languageModel": [
[
{
"node": "AI Agent",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Schedule Trigger": {
"main": [
[
{
"node": "Run a workflow task",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript": {
"main": [
[
{
"node": "AI Agent",
"type": "main",
"index": 0
}
]
]
},
"Run a workflow task": {
"main": [
[
{
"node": "Get details of a workflow task",
"type": "main",
"index": 0
}
]
]
},
"Structured Output Parser": {
"ai_outputParser": [
[
{
"node": "AI Agent",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"Append or update row in sheet": {
"main": [
[
{
"node": "Send a message1",
"type": "main",
"index": 0
}
]
]
},
"Get details of a workflow task": {
"main": [
[
{
"node": "Code in JavaScript",
"type": "main",
"index": 0
}
],
[
{
"node": "Send a message",
"type": "main",
"index": 0
}
]
]
}
}
}