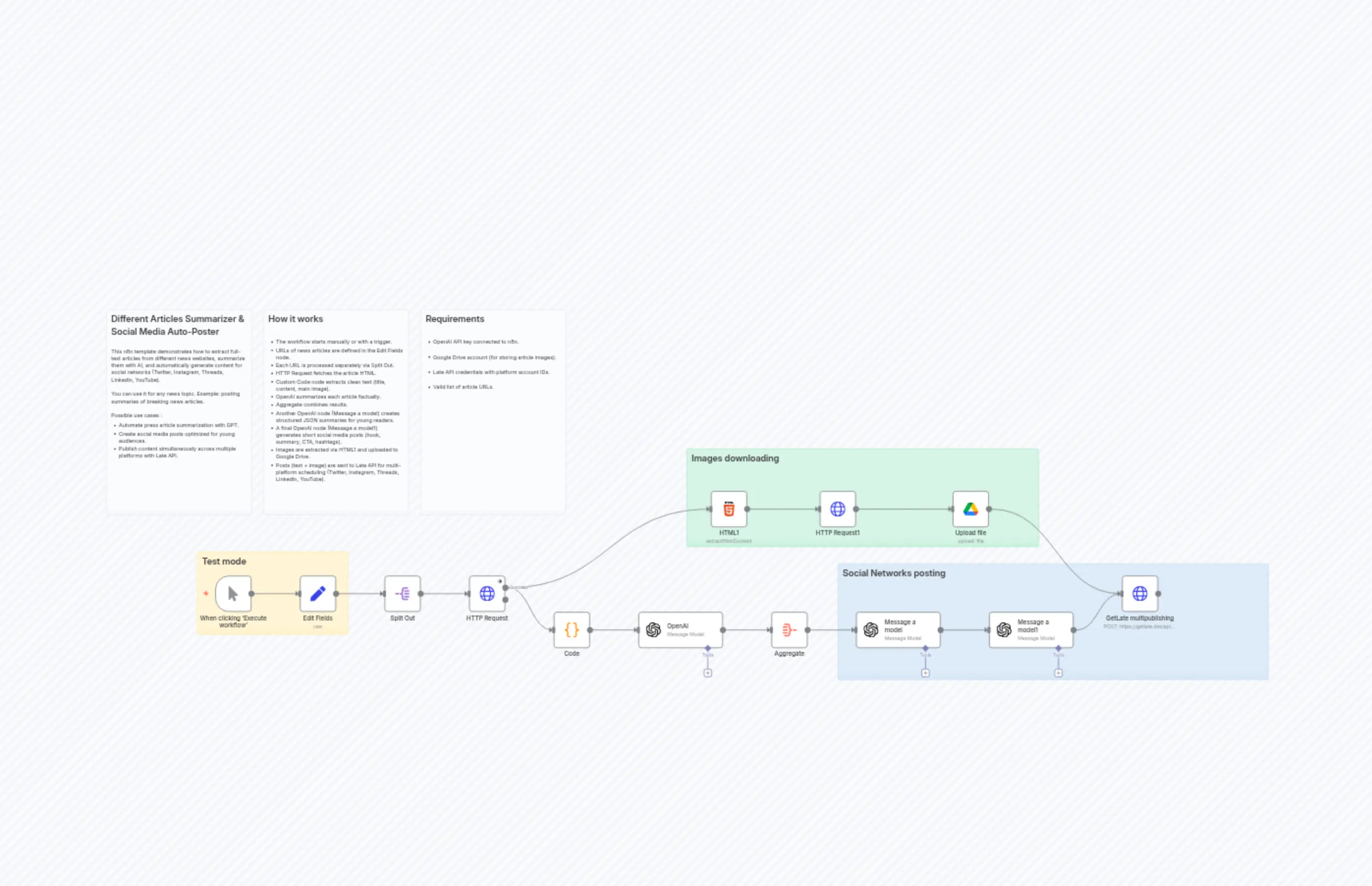
🗞️ News Summarizer & Auto-Poster for Social Media - Late
Description
Categories
🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.setn8n-nodes-base.coden8n-nodes-base.htmln8n-nodes-base.splitOutn8n-nodes-base.aggregaten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNoten8n-nodes-base.stickyNote
PriceKostenlos
Views0
Last Updated11/28/2025
workflow.json
{
"id": "jBgzLQDvUfBwo5rG",
"meta": {
"instanceId": "20129dd042b068f74504e3288edfe39a1229bdd8b410358b39923291ace2903d",
"templateCredsSetupCompleted": true
},
"name": "🗞️ News Summarizer & Auto-Poster for Social Media - Late",
"tags": [
{
"id": "L5OfKYUAxU0VDZh3",
"name": "Content",
"createdAt": "2025-07-02T08:32:59.389Z",
"updatedAt": "2025-07-02T08:32:59.389Z"
}
],
"nodes": [
{
"id": "38daed7e-5981-48b0-9dd4-b5dc4da09cbb",
"name": "Edit Fields",
"type": "n8n-nodes-base.set",
"position": [
-752,
-240
],
"parameters": {
"mode": "raw",
"options": {},
"jsonOutput": "{\n \"urls\": [\n \"URL1\",\n \"URL2\",\n\"URL3\"\n ]\n}"
},
"typeVersion": 3.4
},
{
"id": "0c3c6494-b0d5-4e8c-838c-7c0d83ed2ac9",
"name": "HTTP Request",
"type": "n8n-nodes-base.httpRequest",
"onError": "continueErrorOutput",
"position": [
-304,
-240
],
"parameters": {
"url": "={{ $json.urls }}",
"options": {}
},
"typeVersion": 4.2
},
{
"id": "da58c23f-1a20-45f1-ab4b-f65f14bdae91",
"name": "Code",
"type": "n8n-nodes-base.code",
"position": [
-80,
-144
],
"parameters": {
"mode": "runOnceForEachItem",
"jsCode": "// INPUTS\nconst html = $json.data; // HTML complet\nconst articleUrl = $('Split Out').item.json.urls || \"\"; // URL de l’article (pour les URLs relatives)\n\n// ------------------ Utils ------------------\nfunction decodeEntities(text) {\n return text\n .replace(/&/g, '&')\n .replace(/</g, '<')\n .replace(/>/g, '>')\n .replace(/'/g, \"'\")\n .replace(/"/g, '\"')\n .replace(/ /g, ' ')\n .replace(/é/g, 'é')\n .replace(/è/g, 'è')\n .replace(/à/g, 'à');\n}\n\nfunction resolveUrl(baseUrl, src) {\n if (!src) return null;\n // //cdn… → https:\n if (src.startsWith('//')) return 'https:' + src;\n // absolute\n try {\n return new URL(src, baseUrl).href;\n } catch {\n return src;\n }\n}\n\n// Supprime blocs connus de “parasites” (share, related, newsletter, footer…)\nfunction stripNoise(htmlChunk) {\n let s = htmlChunk;\n\n // blocs “share/social”\n s = s.replace(/<aside[\\s\\S]*?<\\/aside>/gi, '');\n s = s.replace(/<section[^>]*?(?:share|social|related|newsletter|comments)[^>]*>[\\s\\S]*?<\\/section>/gi, '');\n s = s.replace(/<div[^>]*?(?:share|social|related|newsletter|comments|social-tools|meta-social)[^>]*>[\\s\\S]*?<\\/div>/gi, '');\n\n // scripts/styles\n s = s.replace(/<script[\\s\\S]*?<\\/script>/gi, '');\n s = s.replace(/<style[\\s\\S]*?<\\/style>/gi, '');\n\n // nav/footer/header souvent non-article\n s = s.replace(/<(?:nav|footer|header)[\\s\\S]*?<\\/(?:nav|footer|header)>/gi, '');\n\n return s;\n}\n\n// Extrait tous les <p> d’un bloc HTML (en gardant l’ordre)\nfunction extractParagraphs(htmlChunk) {\n const ps = [];\n const re = /<p[^>]*>([\\s\\S]*?)<\\/p>/gi;\n let m;\n while ((m = re.exec(htmlChunk)) !== null) {\n // retire tags résiduels dans <p>\n let t = m[1]\n .replace(/<figure[\\s\\S]*?<\\/figure>/gi, '')\n .replace(/<[^>]+>/g, '')\n .replace(/\\s+/g, ' ')\n .trim();\n if (t) ps.push(t);\n }\n return ps;\n}\n\n// Cherche une image principale : og:image > twitter:image > figure > img dans article/main\nfunction findMainImage(html, baseUrl) {\n let imageMatch =\n html.match(/<meta[^>]+property=[\"']og:image[\"'][^>]+content=[\"']([^\"']+)[\"']/i) ||\n html.match(/<meta[^>]+name=[\"']twitter:image[\"'][^>]+content=[\"']([^\"']+)[\"']/i);\n\n if (imageMatch) return resolveUrl(baseUrl, imageMatch[1]);\n\n // image dans <figure>\n imageMatch =\n html.match(/<figure[\\s\\S]*?<img[^>]+src=[\"']([^\"']+)[\"'][\\s\\S]*?<\\/figure>/i) ||\n html.match(/<(?:article|main)[^>]*>[\\s\\S]*?<img[^>]+src=[\"']([^\"']+)[\"']/i) ||\n html.match(/<img[^>]+src=[\"']([^\"']+)[\"']/i);\n\n return imageMatch ? resolveUrl(baseUrl, imageMatch[1]) : null;\n}\n\n// ------------------ Titre ------------------\nlet titleMatch =\n html.match(/<meta[^>]+property=[\"']og:title[\"'][^>]+content=[\"']([^\"']+)[\"']/i) ||\n html.match(/<meta[^>]+name=[\"']twitter:title[\"'][^>]+content=[\"']([^\"']+)[\"']/i) ||\n html.match(/<title>([\\s\\S]*?)<\\/title>/i);\nlet title = titleMatch ? titleMatch[1] : \"\";\n\n// ------------------ Corps de l’article ------------------\n// 1) Privilégie <article>, sinon <main>, sinon grands conteneurs classiques\nconst candidatePatterns = [\n /<article[^>]*>([\\s\\S]*?)<\\/article>/i,\n /<main[^>]*>([\\s\\S]*?)<\\/main>/i,\n /<div[^>]+class=[\"'][^\"']*(?:article__body|article-body|articleBody|content-article|story|post-content|post__content|entry-content|main-content|content__body)[^\"']*[\"'][^>]*>([\\s\\S]*?)<\\/div>/i,\n // fallback : gros container central (layout courant)\n /<div[^>]+class=[\"'][^\"']*(?:container|content|wrapper)[^\"']*[\"'][^>]*>([\\s\\S]*?)<\\/div>/i,\n];\n\nlet articleHtml = \"\";\nfor (const p of candidatePatterns) {\n const m = html.match(p);\n if (m && m[1]) {\n articleHtml = m[1];\n break;\n }\n}\n// Si encore vide, on prend tout le HTML (on filtrera)\nif (!articleHtml) articleHtml = html;\n\n// 2) Nettoyage “bruit” (share, related, scripts, etc.)\narticleHtml = stripNoise(articleHtml);\n\n// 3) Récupère beaucoup plus de texte : on concatène les <p>\nlet paragraphs = extractParagraphs(articleHtml);\n\n// Si on n’a quasiment rien, tente aussi les <h2>/<h3> comme “paragraphes”\nif (paragraphs.length < 3) {\n const hx = [];\n const reHx = /<(?:h2|h3)[^>]*>([\\s\\S]*?)<\\/(?:h2|h3)>/gi;\n let m;\n while ((m = reHx.exec(articleHtml)) !== null) {\n const t = m[1].replace(/<[^>]+>/g, '').replace(/\\s+/g, ' ').trim();\n if (t) hx.push(t);\n }\n paragraphs = paragraphs.concat(hx);\n}\n\n// 4) Filtrage léger : on retire les lignes trop courtes (menus, miettes)\nparagraphs = paragraphs.filter(p => p.length > 40);\n\n// 5) Limites souples (évite d’avaler l’entier du site)\nconst MAX_PARAGRAPHS = 20; // augmente si tu veux encore plus\nconst MAX_CHARS = 8000; // coupe si trop long\nlet content = \"\";\nfor (const p of paragraphs.slice(0, MAX_PARAGRAPHS)) {\n if ((content + p + \"\\n\\n\").length > MAX_CHARS) break;\n content += p + \"\\n\\n\";\n}\ncontent = content.trim();\n\n// 6) Coupe les blocs “parasites” s’ils apparaissent *plus loin* dans l’article\nconst breakMarkers = [\n \"Partager\", \"Commenter\", \"Partagez sur\", \"Lire aussi\", \"Sur le même sujet\",\n \"Voir aussi\", \"Suivez-nous\", \"Retrouvez-nous\", \"Contactez\", \"Rédaction\",\n \"lire plus tard\", \"newsletter\", \"publicité\", \"nos autres articles\"\n];\n// coupe uniquement après un petit seuil pour ne pas tronquer l’intro\nfor (const marker of breakMarkers) {\n const idx = content.indexOf(marker);\n if (idx > 300) {\n content = content.slice(0, idx).trim();\n break;\n }\n}\n\n// ------------------ Image principale ------------------\nlet imageUrl = findMainImage(html, articleUrl);\n\n// ------------------ Finalisation ------------------\ntitle = decodeEntities(title);\ncontent = decodeEntities(content);\n\nreturn {\n json: {\n title,\n urls: articleUrl,\n content,\n imageUrl\n }\n};\n"
},
"typeVersion": 2
},
{
"id": "d8ba2c62-a400-4634-b0b6-08ce3f1ead6f",
"name": "OpenAI",
"type": "@n8n/n8n-nodes-langchain.openAi",
"position": [
144,
-144
],
"parameters": {
"modelId": {
"__rl": true,
"mode": "list",
"value": "gpt-5",
"cachedResultName": "GPT-5"
},
"options": {},
"messages": {
"values": [
{
"role": "system",
"content": "Tu es un assistant chargé de résumer des articles de presse de manière factuelle, synthétique et hiérarchisée. Tu n'as pas le droit d'inventer quoi que ce soit qui ne soit pas écrit dans le contenu initial"
},
{
"content": "=Voici un article d'actualité à résumer de manière claire, synthétique et détaillé en ne gardant que les informations en rapport avec le titre.\n\nTITRE : {{$json.title}}\n\nCONTENU : {{ $json.content }}"
}
]
}
},
"typeVersion": 1.8
},
{
"id": "f1f69341-f3f5-4fa5-a920-0937da06f643",
"name": "Split Out",
"type": "n8n-nodes-base.splitOut",
"position": [
-528,
-240
],
"parameters": {
"options": {},
"fieldToSplitOut": "=urls"
},
"typeVersion": 1
},
{
"id": "25152ee0-5ccc-4946-96d1-3004094bcb11",
"name": "Aggregate",
"type": "n8n-nodes-base.aggregate",
"position": [
496,
-144
],
"parameters": {
"options": {},
"fieldsToAggregate": {
"fieldToAggregate": [
{
"fieldToAggregate": "message.content"
}
]
}
},
"typeVersion": 1
},
{
"id": "a1ac8d77-76d3-4e98-87cd-ca741123d24b",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1024,
-304
],
"parameters": {
"width": 400,
"height": 220,
"content": "## Test mode"
},
"typeVersion": 1
},
{
"id": "d7d70ef4-ac43-408f-85f2-aeee25030189",
"name": "When clicking ‘Execute workflow’",
"type": "n8n-nodes-base.manualTrigger",
"position": [
-976,
-240
],
"parameters": {},
"typeVersion": 1
},
{
"id": "6905d681-6b32-4fda-a9ea-3fc39aa81ce8",
"name": "HTML1",
"type": "n8n-nodes-base.html",
"position": [
336,
-464
],
"parameters": {
"options": {},
"operation": "extractHtmlContent",
"extractionValues": {
"values": [
{
"key": "figure_img",
"attribute": "content",
"cssSelector": "meta[property=\"og:image\"]",
"returnValue": "attribute"
}
]
}
},
"typeVersion": 1.2
},
{
"id": "f6fd3ca8-7c3d-412a-b1d2-4bcedf3a4dfe",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
272,
-576
],
"parameters": {
"color": 4,
"width": 932,
"height": 260,
"content": "## Images downloading"
},
"typeVersion": 1
},
{
"id": "fcd4a0f2-4cef-42ae-bfd8-bbe9fc3d33ed",
"name": "HTTP Request1",
"type": "n8n-nodes-base.httpRequest",
"position": [
624,
-464
],
"parameters": {
"url": "={{ $json.figure_img }}",
"options": {}
},
"typeVersion": 4.2
},
{
"id": "15bd8581-6713-4421-9c4e-5ba194fa536a",
"name": "Message a model",
"type": "@n8n/n8n-nodes-langchain.openAi",
"position": [
720,
-144
],
"parameters": {
"modelId": {
"__rl": true,
"mode": "list",
"value": "gpt-4o",
"cachedResultName": "GPT-4O"
},
"options": {},
"messages": {
"values": [
{
"role": "assistant",
"content": "Tu es un assistant qui résume de manière journalistique pour les jeunes des articles d’actualité, sans émojis, sans interprétation."
},
{
"content": "=Voici les articles :\n{{ $json.content }}\n\nRéalise une synthèse structurée pour des jeunes lecteurs, formatée comme ce JSON :\n\n{\n \"titre\": \"…\", // min 45 caractères, max 60 caractères\n \"sous_titre\": \"…\", // min 150 caractères, max 220 caractères, ton journalistique et accrocheur\n \"parties\": [\n {\n \"titre_1\": \"…\", // max 60 caractères ton journalistique et accrocheur qui résume la description\n \"description\": \"…\" // max 500 caractères, avec faits et chiffres\n },\n {\n \"titre_2\": \"…\", // idem\n \"description\": \"…\"\n }\n // etc.\n ]\n}\n\nExemple de consignes à inclure en début de prompt :\n\n« **Attention** : \n- il doit y avoir exactement {{ $('Webhook').item.json.body.pages }} pages- `titre` ne doit pas dépasser 60 caractères \n- `sous_titre` ne doit pas dépasser 220 caractères \n- pour chaque objet de `parties`, `titre_X` ≤ 60 caractères et `description` ≤ 500 caractères \nRépond strictement au format JSON ci-dessus, sans explications additionnelles, sans commencer par \"json\". »\n"
},
{
"role": "system",
"content": "Respecte strictement la structure JSON, sans texte avant ou après. N'invente rien. Ne répète pas d'information. Utilise uniquement le contenu fourni."
}
]
}
},
"credentials": {
"openAiApi": {
"id": "xj6uZG7I9SYg1Ypb",
"name": "OpenAi account"
}
},
"typeVersion": 1.8
},
{
"id": "4972cdd6-c3fd-4d1e-95e4-8a1684d5bd66",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
672,
-272
],
"parameters": {
"color": 5,
"width": 1140,
"height": 308,
"content": "## Social Networks posting"
},
"typeVersion": 1
},
{
"id": "ba945e0a-5aa4-4601-a6b2-8c73bb725232",
"name": "Message a model1",
"type": "@n8n/n8n-nodes-langchain.openAi",
"position": [
1072,
-144
],
"parameters": {
"modelId": {
"__rl": true,
"mode": "list",
"value": "chatgpt-4o-latest",
"cachedResultName": "CHATGPT-4O-LATEST"
},
"options": {},
"messages": {
"values": [
{
"content": "=Tu es un assistant spécialisé dans la création de descriptions impactantes pour les réseaux sociaux, à destination des 18-25 ans. Voici le texte de l’article à résumer :\n\" {{ $json.message.content }} \"\n\n\nGénère une description prête à poster sur Instagram, TikTok et autres réseaux, au format suivant :\n\n- Hook d’accroche (1 phrase qui donne envie de lire le post, max 80 caractères)\n- Résumé de l’actu (2 à 4 phrases synthétiques et factuelles, 200 à 250 caractères max)\n- Question ou call-to-action pour inciter à commenter ou réagir (max 80 caractères)\n- Hashtags (5 à 8, séparés par des espaces, mélange de #actu #news #jeunes #actualité + sujets du texte + toujours #pikor)\n\nContraintes :\n- Pas d’émojis ou juste un seul, jamais au début du texte.\n- Aucune invention : tu utilises uniquement les infos de l’article.\n- Le ton doit rester journalistique, mais accrocheur, écrit pour des jeunes adultes (jamais infantilisant).\n- Pas de répétition, ni d’auto-promo, ni de lien externe.\n- Jamais plus de 450 caractères au total."
},
{
"role": "system",
"content": "Tu es un assistant éditorial qui génère des descriptions prêtes à publier sur les réseaux sociaux pour une application d’actualité destinée aux 18-25 ans. \n\nTa mission : \n- Structurer la description comme demandé (hook, résumé, call-to-action, hashtags)\n- Toujours respecter les consignes de format, de longueur et de ton : journalistique, accrocheur, jamais infantilisant.\n- Aucune invention ni ajout extérieur : uniquement des faits présents dans l’article.\n- Pas de répétition, pas d’auto-promo, pas de lien externe, pas plus d’un émoji.\n- Si l’information manque dans l’article, n’ajoute rien et passe à la suite.\n- La sortie doit être claire, prête à l’emploi et strictement respecter la structure demandée dans le prompt utilisateur."
}
]
}
},
"credentials": {
"openAiApi": {
"id": "xj6uZG7I9SYg1Ypb",
"name": "OpenAi account"
}
},
"typeVersion": 1.8
},
{
"id": "01102406-10d0-424f-9f60-69717e87dc9c",
"name": "Upload file",
"type": "n8n-nodes-base.googleDrive",
"position": [
976,
-464
],
"parameters": {
"name": "={{$now.format('f') }}_{{ $json[\"source\"] || \"image\" }}_{{$itemIndex}}.jpg",
"driveId": {
"__rl": true,
"mode": "list",
"value": "My Drive",
"cachedResultUrl": "https://drive.google.com/drive/my-drive",
"cachedResultName": "My Drive"
},
"options": {},
"folderId": {
"__rl": true,
"mode": "list",
"value": "191yh8eb9mx8wykfpGXJNVy9F9IWgDZxz",
"cachedResultUrl": "https://drive.google.com/drive/folders/191yh8eb9mx8wykfpGXJNVy9F9IWgDZxz",
"cachedResultName": "Pikor - Images articles"
}
},
"typeVersion": 3
},
{
"id": "1cfd0408-80e4-411e-9c9b-130a327be710",
"name": "GetLate multipublishing",
"type": "n8n-nodes-base.httpRequest",
"position": [
1424,
-240
],
"parameters": {
"url": "https://getlate.dev/api/v1/post",
"method": "POST",
"options": {},
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Authorization",
"value": "={\n \"content\": \"{{ $('Message a model1').item.json.message.content }}\",\n \"platforms\": [\n {\"platform\": \"twitter\", \"accountId\": \"TWITTER_ACCOUNT_ID\"},\n {\"platform\": \"instagram\", \"accountId\": \"INSTAGRAM_ACCOUNT_ID\"},\n {\"platform\": \"linkedin\", \"accountId\": \"LINKEDIN_ACCOUNT_ID\"},\n {\"platform\": \"threads\", \"accountId\": \"THREADS_ACCOUNT_ID\"},\n {\"platform\": \"youtube\", \"accountId\": \"YOUTUBE_ACCOUNT_ID\"}\n ],\n \"scheduledFor\": \"today\",\n \"timezone\": \"America/New_York\",\n \"publishNow\": false,\n \"isDraft\": false,\n \"visibility\": \"public\",\n \"tags\": [\"programming\", \"tutorial\", \"api\", \"coding\"],\n \"mediaItems\": [\n {\n \"type\": \"image\",\n \"url\": \"{{ $('HTTP Request1').item.json.figure_img }}\",\n \"filename\": \"optional_filename\"\n }\n ]\n}"
},
{
"name": "Content-Type",
"value": "application/json"
}
]
}
},
"typeVersion": 4.2
},
{
"id": "d5abfc93-9f61-4c24-b577-4cf7fef2e35f",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1264,
-944
],
"parameters": {
"color": 7,
"width": 384,
"height": 544,
"content": "## Different Articles Summarizer & Social Media Auto-Poster\n\nThis n8n template demonstrates how to extract full-text articles from different news websites, summarize them with AI, and automatically generate content for social networks (Twitter, Instagram, Threads, LinkedIn, YouTube).\n\nYou can use it for any news topic. Example: posting summaries of breaking news articles.\n\nPossible use cases :\n* Automate press article summarization with GPT.\n* Create social media posts optimized for young audiences.\n* Publish content simultaneously across multiple platforms with Late API."
},
"typeVersion": 1
},
{
"id": "92d59f4a-125b-4579-b842-345ff18e1936",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
-848,
-944
],
"parameters": {
"color": 7,
"width": 384,
"height": 544,
"content": "## How it works\n\n* The workflow starts manually or with a trigger.\n* URLs of news articles are defined in the Edit Fields node.\n* Each URL is processed separately via Split Out.\n* HTTP Request fetches the article HTML.\n* Custom Code node extracts clean text (title, content, main image).\n* OpenAI summarizes each article factually.\n* Aggregate combines results.\n* Another OpenAI node (Message a model) creates structured JSON summaries for young readers.\n* A final OpenAI node (Message a model1) generates short social media posts (hook, summary, CTA, hashtags).\n* Images are extracted via HTML1 and uploaded to Google Drive.\n* Posts (text + image) are sent to Late API for multi-platform scheduling (Twitter, Instagram, Threads, LinkedIn, YouTube)."
},
"typeVersion": 1
},
{
"id": "90105c8e-5fb0-4626-a18a-41f3aa05e5b2",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
-432,
-944
],
"parameters": {
"color": 7,
"width": 384,
"height": 544,
"content": "## Requirements\n\n* OpenAI API key connected to n8n.\n\n* Google Drive account (for storing article images).\n\n* Late API credentials with platform account IDs.\n\n* Valid list of article URLs."
},
"typeVersion": 1
}
],
"active": false,
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"versionId": "c968e6b7-0af4-4269-b953-2961c85e7f67",
"connections": {
"Code": {
"main": [
[
{
"node": "OpenAI",
"type": "main",
"index": 0
}
]
]
},
"HTML1": {
"main": [
[
{
"node": "HTTP Request1",
"type": "main",
"index": 0
}
]
]
},
"OpenAI": {
"main": [
[
{
"node": "Aggregate",
"type": "main",
"index": 0
}
]
]
},
"Aggregate": {
"main": [
[
{
"node": "Message a model",
"type": "main",
"index": 0
}
]
]
},
"Split Out": {
"main": [
[
{
"node": "HTTP Request",
"type": "main",
"index": 0
}
]
]
},
"Edit Fields": {
"main": [
[
{
"node": "Split Out",
"type": "main",
"index": 0
}
]
]
},
"Upload file": {
"main": [
[
{
"node": "GetLate multipublishing",
"type": "main",
"index": 0
}
]
]
},
"HTTP Request": {
"main": [
[
{
"node": "Code",
"type": "main",
"index": 0
},
{
"node": "HTML1",
"type": "main",
"index": 0
}
],
[]
]
},
"HTTP Request1": {
"main": [
[
{
"node": "Upload file",
"type": "main",
"index": 0
}
]
]
},
"Message a model": {
"main": [
[
{
"node": "Message a model1",
"type": "main",
"index": 0
}
]
]
},
"Message a model1": {
"main": [
[
{
"node": "GetLate multipublishing",
"type": "main",
"index": 0
}
]
]
},
"GetLate multipublishing": {
"main": [
[]
]
},
"When clicking ‘Execute workflow’": {
"main": [
[
{
"node": "Edit Fields",
"type": "main",
"index": 0
}
]
]
}
}
}