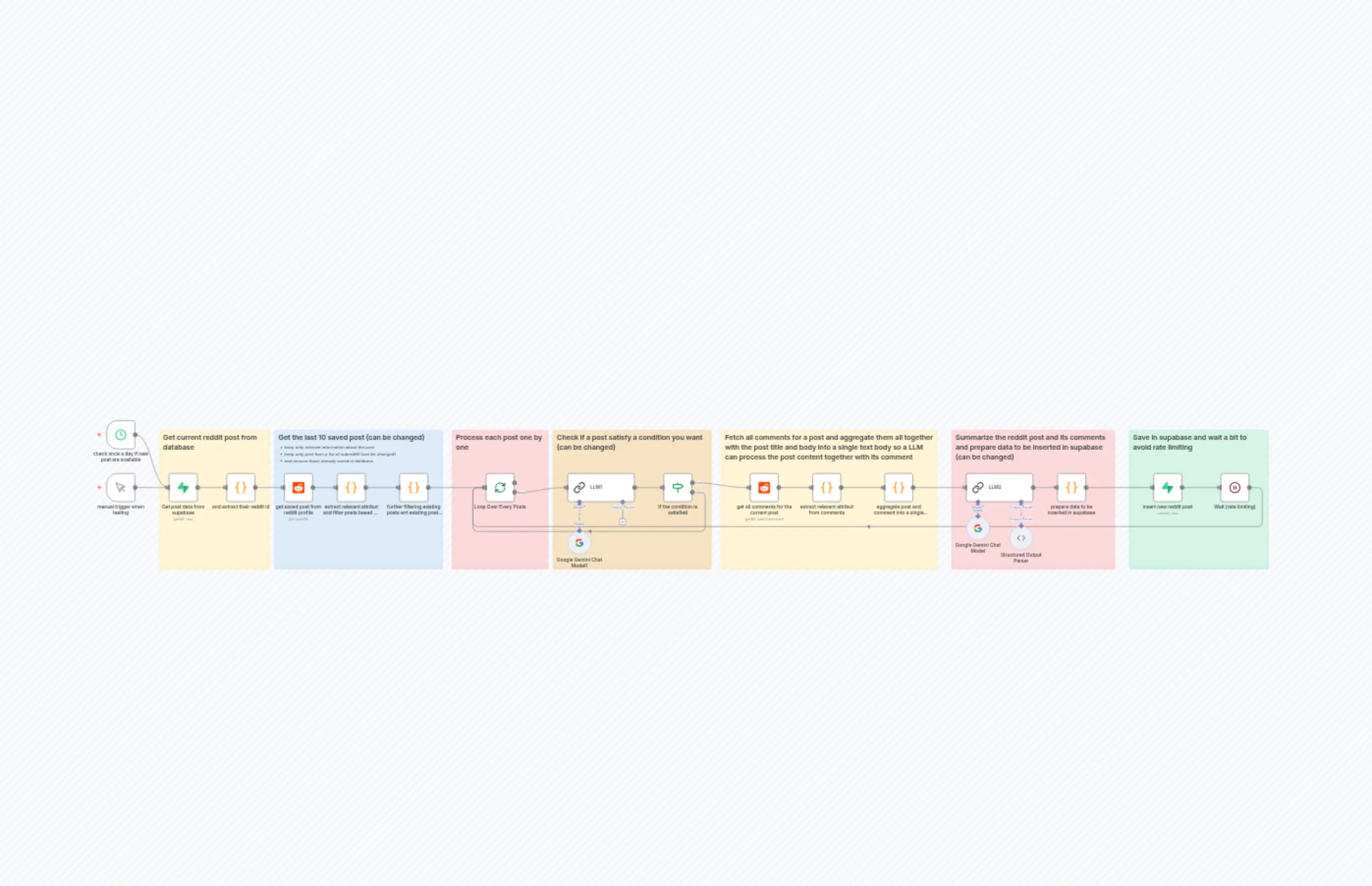
Workflow function to summarize Reddit posts using Google Gemini and Supabase
Description
Categories
📢 Marketing🤖 AI & Machine Learning
Nodes Used
n8n-nodes-base.ifn8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.coden8n-nodes-base.waitn8n-nodes-base.redditn8n-nodes-base.reddit
PriceKostenlos
Views0
Last Updated11/28/2025
workflow.json
{
"meta": {
"instanceId": "f04604a06a1818d538282f856aabe3c16c72da16cc8cc02ebb6de4c017b29c24",
"templateCredsSetupCompleted": true
},
"nodes": [
{
"id": "6e9022b0-adce-4dce-be2d-74819e6f9d8f",
"name": "Google Gemini Chat Model",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
1344,
368
],
"parameters": {
"options": {},
"modelName": "models/gemini-2.0-flash"
},
"credentials": {
"googlePalmApi": {
"id": "7LJhh2SkzDmaJFK9",
"name": "Google Gemini(PaLM) Api account"
}
},
"typeVersion": 1
},
{
"id": "8f8bbc64-d508-40bf-beef-218dcc01f6e1",
"name": "extract relevant attribut from comments",
"type": "n8n-nodes-base.code",
"position": [
832,
224
],
"parameters": {
"jsCode": "// Extract Reddit comment information with full nested structure\n// Get all input items\nconst items = $input.all();\n\n// Array to store all extracted comments\nconst extractedData = [];\n\n// Recursive helper function to extract replies at all levels\nfunction extractReplies(repliesData) {\n if (!repliesData || typeof repliesData !== 'object') {\n return [];\n }\n \n // Reddit API returns replies in a nested structure\n const repliesArray = [];\n \n if (repliesData.data && repliesData.data.children) {\n for (const child of repliesData.data.children) {\n if (child.kind === 't1' && child.data) {\n const reply = child.data;\n \n // Recursively extract nested replies (children of this reply)\n const nestedReplies = reply.replies ? extractReplies(reply.replies) : [];\n \n repliesArray.push({\n body: reply.body,\n upvotes: reply.ups || reply.score || 0,\n author: reply.author || '[deleted]',\n created_utc: reply.created,\n replies: nestedReplies, // Include nested replies\n replies_count: nestedReplies.length\n });\n }\n }\n }\n \n return repliesArray;\n}\n\n// Loop through each input item\nfor (const item of items) {\n const comment = item.json;\n \n // Extract replies recursively\n const replies = comment.replies ? extractReplies(comment.replies) : [];\n \n // Extract required fields from each comment\n extractedData.push({\n body: comment.body,\n upvotes: comment.ups || comment.score || 0,\n replies: replies,\n replies_count: replies.length,\n author: comment.author || '[deleted]',\n created_utc: comment.created,\n });\n}\n\n// Return the extracted data\nreturn extractedData.map(item => ({ json: item }));"
},
"typeVersion": 2
},
{
"id": "af4f6458-f3cb-48af-8e02-d42ddb1dd7bc",
"name": "aggregate post and comment into a single text",
"type": "n8n-nodes-base.code",
"position": [
1072,
224
],
"parameters": {
"jsCode": "// n8n JavaScript Code to Extract and Aggregate Reddit Comments\nconst postData = $('Loop Over Every Posts').first().json;\nconst commentsData = $input.all();\n\n// Function to concatenate all nested comment text into a single string\nfunction concatenateComment(comment, indent = 0) {\n let result = '';\n const indentation = ' '.repeat(indent);\n \n // Add the current comment\n result += `${indentation}[${comment.upvotes} upvotes] ${comment.author || 'Unknown'}:\\n`;\n result += `${indentation}${comment.body}\\n`;\n \n // Recursively add all nested replies\n if (comment.replies && comment.replies.length > 0) {\n result += '\\n';\n for (const reply of comment.replies) {\n result += concatenateComment(reply, indent + 1);\n }\n }\n \n return result;\n}\n\n\n// Build the final aggregated text\nlet finalText = \"\" // concatenateComment(commentsData[0].json)\n\n// Add post title and description\nfinalText += `TITLE:\\n${postData.title}\\n\\n`;\nfinalText += `DESCRIPTION:\\n${postData.description}\\n\\n`;\nfinalText += `${'='.repeat(100)}\\n`;\nfinalText += `COMMENTS SECTION (${commentsData.length} comments)\\n`;\nfinalText += `${'='.repeat(100)}\\n\\n`;\n\n// Iterate over all comments and concatenate\nfor (let i = 0; i < commentsData.length; i++) {\n const comment = commentsData[i].json;\n \n finalText += `COMMENT ${i + 1}:\\n`;\n finalText += concatenateComment(comment);\n finalText += `\\n${'-'.repeat(100)}\\n\\n`;\n}\n\n// Return the final aggregated result\nreturn {\n json: {\n aggregated_text: finalText,\n }\n};"
},
"typeVersion": 2
},
{
"id": "55da0772-4345-4cb7-91f4-e27a5ecab116",
"name": "Structured Output Parser",
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"position": [
1488,
400
],
"parameters": {
"jsonSchemaExample": "{\n\t\"summary\": \"result of the summary\",\n \"tags\": \"a list of the tags separated by comma\"\n}"
},
"typeVersion": 1.3
},
{
"id": "9d5f419a-80a2-4e68-9ab1-eb2aa580ecd4",
"name": "Google Gemini Chat Model1",
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"position": [
16,
416
],
"parameters": {
"options": {},
"modelName": "models/gemini-2.0-flash"
},
"credentials": {
"googlePalmApi": {
"id": "7LJhh2SkzDmaJFK9",
"name": "Google Gemini(PaLM) Api account"
}
},
"typeVersion": 1
},
{
"id": "dac2ac6e-612f-4a94-88a2-1a90348a05f9",
"name": "Wait (rate limiting)",
"type": "n8n-nodes-base.wait",
"position": [
2192,
224
],
"webhookId": "8da44e8a-ec45-425a-a8f2-9490bc84b163",
"parameters": {},
"typeVersion": 1.1
},
{
"id": "f97e2920-5139-4179-82c7-2735c880aeb6",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1344,
80
],
"parameters": {
"width": 368,
"height": 464,
"content": "## Get current reddit post from database"
},
"typeVersion": 1
},
{
"id": "93be6f34-652d-4f97-aef0-d7a614741c09",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-960,
80
],
"parameters": {
"color": 5,
"width": 560,
"height": 464,
"content": "## Get the last 10 saved post (can be changed)\n- keep only relevant information about the post\n- keep only post from a list of subreddit (can be changed)\n- and remove those already saved in database"
},
"typeVersion": 1
},
{
"id": "7e5b3fc7-a09e-41d6-a00c-141779a5678a",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
-368,
80
],
"parameters": {
"color": 3,
"width": 320,
"height": 464,
"content": "## Process each post one by one"
},
"typeVersion": 1
},
{
"id": "0fc264ac-9c59-430e-bb4e-cc1ed75db4b7",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
-32,
80
],
"parameters": {
"color": 2,
"width": 528,
"height": 464,
"content": "## Check if a post satisfy a condition you want (can be changed)"
},
"typeVersion": 1
},
{
"id": "9cb9e6cc-b9b1-4919-89e0-6e1169731082",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
528,
80
],
"parameters": {
"width": 720,
"height": 464,
"content": "## Fetch all comments for a post and aggregate them all together with the post title and body into a single text body so a LLM can process the post content together with its comment"
},
"typeVersion": 1
},
{
"id": "0440fb77-5394-454e-bc44-6d9918e1b821",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
1296,
80
],
"parameters": {
"color": 3,
"width": 544,
"height": 464,
"content": "## Summarize the reddit post and its comments and prepare data to be inserted in supabase (can be changed)"
},
"typeVersion": 1
},
{
"id": "debac080-e6e3-4c76-8bec-d065613aab79",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
1888,
80
],
"parameters": {
"color": 4,
"width": 464,
"height": 464,
"content": "## Save in supabase and wait a bit to avoid rate limiting"
},
"typeVersion": 1
},
{
"id": "16ee10de-4617-470f-a0d0-6adacaaba375",
"name": "manual trigger when testing",
"type": "n8n-nodes-base.manualTrigger",
"position": [
-1520,
224
],
"parameters": {},
"typeVersion": 1
},
{
"id": "263dae2d-baf8-4390-8f9e-4023090302bc",
"name": "check once a day if new post are available",
"type": "n8n-nodes-base.scheduleTrigger",
"position": [
-1520,
48
],
"parameters": {
"rule": {
"interval": [
{}
]
}
},
"typeVersion": 1.2
},
{
"id": "6180a9ca-b5a1-4d57-86ef-6f17b16c4686",
"name": "Get post data from supabase",
"type": "n8n-nodes-base.supabase",
"position": [
-1312,
224
],
"parameters": {
"tableId": "reddit_posts",
"operation": "getAll",
"returnAll": true,
"filterType": "none"
},
"credentials": {
"supabaseApi": {
"id": "D9J5oMWZfLNVALqI",
"name": "Supabase account"
}
},
"typeVersion": 1
},
{
"id": "924cdc72-9c5c-44c6-a886-17b9626a5169",
"name": "and extract their reddit id",
"type": "n8n-nodes-base.code",
"position": [
-1120,
224
],
"parameters": {
"jsCode": "const items = $input.all();\nconst redditIds = items.map((item) => item?.json?.reddit_id);\nreturn { redditIds };\n"
},
"typeVersion": 2
},
{
"id": "f129a042-72fd-4d4f-b8e4-533b7d226ba8",
"name": "get saved post from reddit profile",
"type": "n8n-nodes-base.reddit",
"position": [
-928,
224
],
"parameters": {
"limit": 10,
"details": "saved",
"resource": "profile"
},
"credentials": {
"redditOAuth2Api": {
"id": "7rcEyXptAH3o1j8B",
"name": "Reddit account"
}
},
"typeVersion": 1
},
{
"id": "232786ac-2809-4534-b353-37263dccc03f",
"name": "extract relevant attribut and filter posts based on subreddit",
"type": "n8n-nodes-base.code",
"position": [
-752,
224
],
"parameters": {
"jsCode": "// Extract Reddit post information\n// Get all input items - each item contains a post\nconst items = $input.all();\n\n// Define accepted subreddits (exact matches)\nconst acceptedSubReddits = [];\n\n// Define keywords for soft filtering (case-insensitive)\nconst subredditKeywords = [];\n\n// Filter function\nconst isAcceptedSubreddit = (subreddit) => {\n const subredditLower = subreddit.toLowerCase();\n \n // Check for exact match\n if (acceptedSubReddits.includes(subredditLower)) {\n return true;\n }\n \n // Check if subreddit contains any of the keywords\n return subredditKeywords.some(keyword => subredditLower.includes(keyword));\n};\n\n// Process all posts and filter by subreddit\nconst extractedData = items\n .map(item => item.json) // Extract the json from each item\n .filter(post => isAcceptedSubreddit(post.subreddit)) // Filter by subreddit criteria\n .map(post => ({\n id: post.id,\n title: post.title,\n description: post.selftext || '',\n subreddit: post.subreddit,\n url: `https://reddit.com${post.permalink}`,\n upvotes: post.ups,\n num_comments: post.num_comments,\n post_date: new Date(post.created_utc * 1000).toISOString()\n }));\n\n// Return the extracted data\nreturn extractedData.map(item => ({ json: item }));"
},
"typeVersion": 2
},
{
"id": "5d76664a-5068-4a75-98ff-901ea34c21df",
"name": "further filtering existing posts wrt existing posts in database",
"type": "n8n-nodes-base.code",
"position": [
-544,
224
],
"parameters": {
"jsCode": "const newPosts = $input.all();\n\n// Extract reddit_ids from Supabase response\nconst savedRedditIds = $(\"and extract their reddit id\").first().json.redditIds\n\n// Filter out existing posts\nconst uniquePosts = newPosts.filter(item => {\n const postId = item.json.id;\n return !savedRedditIds.includes(postId);\n});\n\nreturn uniquePosts;"
},
"typeVersion": 2
},
{
"id": "9afcd5d7-6774-4aa9-9f5b-b2bd2b7ba3a7",
"name": "LLM1",
"type": "@n8n/n8n-nodes-langchain.chainLlm",
"position": [
16,
224
],
"parameters": {
"text": "=Does this reddit post {YOUR CONDITION}? Answer only with 'YES' or 'NO'\n\n=== REDDIT POST ===\ntitle: {{ $input.all()[0].json.title }}\n\n{{ $input.all()[0].json.description }}",
"batching": {},
"messages": {
"messageValues": [
{
"message": "{YOUR CUSTOM SYSTEM PROMPT}"
}
]
},
"promptType": "define",
"hasOutputParser": true
},
"typeVersion": 1.7
},
{
"id": "07a68c95-dd2d-41a9-a37d-cfa1768ab66a",
"name": "get all comments for the current post",
"type": "n8n-nodes-base.reddit",
"position": [
624,
224
],
"parameters": {
"postId": "={{ $('Loop Over Every Posts').first().json.id }}",
"resource": "postComment",
"operation": "getAll",
"returnAll": true,
"subreddit": "={{ $('Loop Over Every Posts').first().json.subreddit }}"
},
"credentials": {
"redditOAuth2Api": {
"id": "7rcEyXptAH3o1j8B",
"name": "Reddit account"
}
},
"typeVersion": 1
},
{
"id": "d10341d7-7e4b-4f13-a3a2-58d856b34ac5",
"name": "LLM2",
"type": "@n8n/n8n-nodes-langchain.chainLlm",
"position": [
1344,
224
],
"parameters": {
"text": "=summarize the following reddit post using its content and comments in less than 300 words. Assign to this post some tags when relevant, use tags from the following options: [{YOUR CUSTOM TAGS}]\n\n{{ $json.aggregated_text }}",
"batching": {},
"messages": {
"messageValues": [
{
"message": "{YOUR CUSTOM SYSTEM PROMPT}"
}
]
},
"promptType": "define",
"hasOutputParser": true
},
"typeVersion": 1.7
},
{
"id": "14148b67-c31b-4a79-942e-240a6e096d03",
"name": "prepare data to be inserted in supabase",
"type": "n8n-nodes-base.code",
"position": [
1648,
224
],
"parameters": {
"jsCode": "const postInfo = $('Loop Over Every Posts').first().json\nconst summary = $input.all()[0].json.output.summary || \"\"\nlet tags = $input.all()[0].json.output.tags || \"\"\ntags = tags.split(\",\")\n\nreturn {\n json: {\n reddit_id: postInfo.id,\n title: postInfo.title,\n url: postInfo.url,\n summary: summary,\n tags: tags,\n post_date: postInfo.post_date,\n upvotes: postInfo.upvotes,\n num_comments: postInfo.num_comments\n }\n}"
},
"typeVersion": 2
},
{
"id": "6b333271-11fe-470d-9d79-cb813f2851fd",
"name": "insert new reddit post",
"type": "n8n-nodes-base.supabase",
"position": [
1968,
224
],
"parameters": {
"tableId": "reddit_posts",
"dataToSend": "autoMapInputData"
},
"credentials": {
"supabaseApi": {
"id": "D9J5oMWZfLNVALqI",
"name": "Supabase account"
}
},
"typeVersion": 1
},
{
"id": "33751e13-2123-4563-bf8a-af8d56ef3060",
"name": "Loop Over Every Posts",
"type": "n8n-nodes-base.splitInBatches",
"position": [
-256,
224
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "c82a5220-6aa6-4785-9bad-f815d206a8ea",
"name": "If the condition is satisfied",
"type": "n8n-nodes-base.if",
"position": [
336,
224
],
"parameters": {
"options": {},
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "1e45af06-4c0d-4c43-b9c7-066f046ec572",
"operator": {
"name": "filter.operator.equals",
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $input.all()[0].json.text }}",
"rightValue": "YES"
}
]
}
},
"typeVersion": 2.2
}
],
"pinData": {},
"connections": {
"LLM1": {
"main": [
[
{
"node": "If the condition is satisfied",
"type": "main",
"index": 0
}
]
]
},
"LLM2": {
"main": [
[
{
"node": "prepare data to be inserted in supabase",
"type": "main",
"index": 0
}
]
]
},
"Wait (rate limiting)": {
"main": [
[
{
"node": "Loop Over Every Posts",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Every Posts": {
"main": [
[],
[
{
"node": "LLM1",
"type": "main",
"index": 0
}
]
]
},
"insert new reddit post": {
"main": [
[
{
"node": "Wait (rate limiting)",
"type": "main",
"index": 0
}
]
]
},
"Google Gemini Chat Model": {
"ai_languageModel": [
[
{
"node": "LLM2",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Structured Output Parser": {
"ai_outputParser": [
[
{
"node": "LLM2",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"Google Gemini Chat Model1": {
"ai_languageModel": [
[
{
"node": "LLM1",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Get post data from supabase": {
"main": [
[
{
"node": "and extract their reddit id",
"type": "main",
"index": 0
}
]
]
},
"and extract their reddit id": {
"main": [
[
{
"node": "get saved post from reddit profile",
"type": "main",
"index": 0
}
]
]
},
"manual trigger when testing": {
"main": [
[
{
"node": "Get post data from supabase",
"type": "main",
"index": 0
}
]
]
},
"If the condition is satisfied": {
"main": [
[
{
"node": "get all comments for the current post",
"type": "main",
"index": 0
}
],
[
{
"node": "Loop Over Every Posts",
"type": "main",
"index": 0
}
]
]
},
"get saved post from reddit profile": {
"main": [
[
{
"node": "extract relevant attribut and filter posts based on subreddit",
"type": "main",
"index": 0
}
]
]
},
"get all comments for the current post": {
"main": [
[
{
"node": "extract relevant attribut from comments",
"type": "main",
"index": 0
}
]
]
},
"extract relevant attribut from comments": {
"main": [
[
{
"node": "aggregate post and comment into a single text",
"type": "main",
"index": 0
}
]
]
},
"prepare data to be inserted in supabase": {
"main": [
[
{
"node": "insert new reddit post",
"type": "main",
"index": 0
}
]
]
},
"check once a day if new post are available": {
"main": [
[
{
"node": "Get post data from supabase",
"type": "main",
"index": 0
}
]
]
},
"aggregate post and comment into a single text": {
"main": [
[
{
"node": "LLM2",
"type": "main",
"index": 0
}
]
]
},
"extract relevant attribut and filter posts based on subreddit": {
"main": [
[
{
"node": "further filtering existing posts wrt existing posts in database",
"type": "main",
"index": 0
}
]
]
},
"further filtering existing posts wrt existing posts in database": {
"main": [
[
{
"node": "Loop Over Every Posts",
"type": "main",
"index": 0
}
]
]
}
}
}